基于元多智能体深度强化学习的新型电力系统多目标鲁棒优化方法与流程
- 国知局
- 2024-07-31 17:28:01
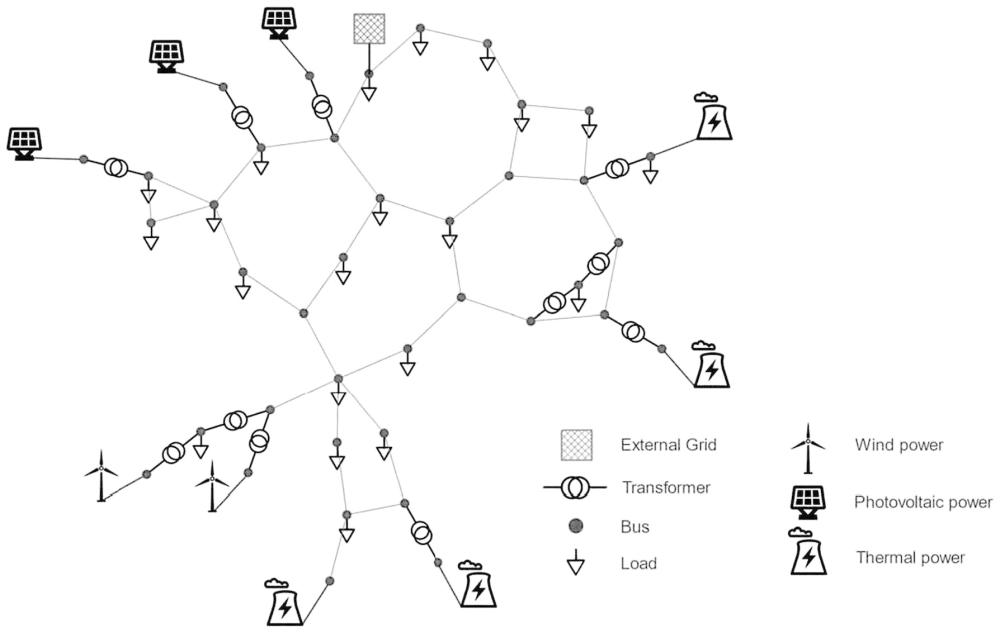
本发明涉及风电/光伏等新能源发电接入电网的优化领域,具体为一种基于元多智能体深度强化学习的新型电力系统多目标鲁棒优化方法。
背景技术:
1、过度依赖化石燃料的能源结构给气候环境问题带来了巨大的挑战。随着近年来全球范围内的气候环境问题愈发得严峻,世界各国对能源结构调整的相关进展也越来越重视,使用清洁的可再生能源替换传统的化石燃料能源的已成为全球范围内的发展共识。
2、风力发电和太阳能发电作为新能源发电的主力军,近年来在电力系统中的占比不断上升。一方面,得益于风能、太阳能资源分布广泛,可以在多种地理环境下应用;但同时,其所作为非平稳电源具有的间歇性和波动性为并网带来巨大挑战。针对新能源发电接入电网的优化调度中存在的多目标和不确定性,制定相应的解决方案,是提升新型电力系统调节能力的关键。
3、传统的基于群智能优化算法的解决方案存在无法保存优化经验、调度时间区间短、难以应对问题空间的高复杂性等问题。为此,需要一种能够解决上述问题的优化算法。
技术实现思路
1、本发明为了解决传统的基于群智能优化算法的解决方案存在无法保存优化经验、调度时间区间短、难以应对问题空间的高复杂性等问题,提供了一种基于元多智能体深度强化学习的新型电力系统多目标鲁棒优化方法。
2、本发明是通过如下技术方案来实现的:本发明研究了使用强化学习相关算法解决电力系统的多目标含不确定性优化调度问题,提供了一种基于元多智能体深度强化学习的新型电力系统多目标鲁棒优化方法,包括如下步骤:
3、s1:建模了风电/光伏/火电混合能源系统的多目标二阶段鲁棒优化数学模型,数学模型中的优化目标包括:最小化经济成本、最小化碳排放量以及最小化电网的线路有功损耗,考虑风力发电和光伏发电的不确定性,构建不确定集数学模型如式(1)和(2)所示,是的真实值,是预测值,是不确定量:
4、
5、
6、经济一阶段调度目标如式(3)至(7)所示,ai、bi、ci是火电站的成本系数,是风电站的成本系数,是光伏电站的成本系数,mt是t时刻的电价:
7、
8、
9、
10、
11、c=ct+cw+cpv+cext (7)
12、碳排放一阶段调度目标如式(8)和(9)所示,ρi、τi、ωi、αi、βi是碳排放的计算系数,由具体火电站给出;
13、
14、
15、线路有功损耗一阶段目标如式(10)所示:
16、
17、一阶段的总目标表示为式(11):
18、
19、对于二阶段调度目标而言,经济、碳排放、线损的二阶段目标如式(12)-(13)所示,其中,新加入了一个系数hi为二阶段实时调整的运维成本系数;
20、
21、
22、二阶段目标是在不确定集u中找到最大化目标的不确定量u,同时找到最小化目标的阶段决策变量y,为式(14)所示:
23、
24、解调度策略的约束条件包括功率平衡约束、最大最小功率约束、火电站功率爬坡约束,如式(15)-(17)所示:
25、
26、
27、
28、因为二阶段目标为一个max-min形式的目标不易直接求解,为此通过拉格朗日乘子式,引入kkt条件,构造二阶段目标的拉格朗日对偶问题,同时引入权重(λ1,λ2,λ3)将三个目标进行加权,得到最终多目标二阶段鲁棒优化数学模型,如式(18)-(20)所示;
29、
30、
31、
32、其中一阶段优化变量依然为日/周/月前调度策略二阶段调度策略则变为了不确定量u和拉格朗日乘子γ0,
33、s2:分别通过多智能体强化学习解决二阶段鲁棒优化问题,采用元强化学习解决多目标优化问题;通过设置两个异构智能体agent1和agent2,agent1负责最小化整体优化目标,agent2负责最大化二阶段目标,具体为:agent1通过接受当前t时刻电网的运行状态信息statet,输出一阶段解xt,agent2则接受statet和一阶段的解xt,输出二阶段的解yt,agent2通过影响agent1的奖励函数来使agent1输出的一阶段调度策略更具鲁棒性;
34、s2-1:agent1得到当前时刻电网的状态信息st并且输出一阶段调度策略xt;
35、s2-2:agent1得到当前时刻电网的状态信息st以及agent1输出的一阶段策略xt,输出二阶段的不确定量u以及拉格朗日乘子γ;
36、s2-3:仿真环境接受两个智能体输出的动作,返回两个智能体在这一时刻的奖励,并进入下一状态st+1;重复s2-1~s2-3,直到t=t;
37、s2-4:根据步骤s2-1到s2-3产生的数据更新两个智能体。
38、s3:将多智能体强化学习与元强化学习结合形成针对风电/光伏/火电混合能源系统的多目标二阶段鲁棒优化端到端的解决方案,具体如下:
39、s3-1:meta learning元学习阶段:
40、s3-1-1:首先初始化一个meta model,其中包含agent1的策略网络和价值网络与agent2的策略网络和价值网络;
41、s3-1-2:然后,通过均匀分布采样若干权重(λ1,λ2,λ3)代入数学模型中,构造多智能体强化学习环境;
42、s3-1-3:接下来使用reptile算法框架进行meta learning,多智能体之间的对抗学习使用ippo算法,具体每个智能体的策略网络和价值网络的更新算法使用ppo-clip算法;
43、s3-1-4:当达到预设的meta learning轮数后,结束meta learning并返回metamodel;
44、s3-2:fine tuning微调阶段:
45、s3-2-1:首先接受meta learning后的meta model,将meta model拷贝z份;
46、s3-2-2:然后,等距采样若干权重(λ1,λ2,λ3)代入数学模型中,构造多智能体强化学习环境;
47、s3-2-3:使用ippo算法和ppo-clip算法对每一份拷贝的meta model分别在不同权重的多智能体强化学习环境中进行微调;
48、s3-2-4:当达到微调轮数后,就能够使用微调过后的模型解决具体的优化调度问题,得到帕累托最优解;
49、s3-2-5:使用所有得到的帕累托最优解,通过非支配原则,构造帕累托前沿。
50、与现有技术相比本发明具有以下有益效果:本发明所提供的一种基于元多智能体深度强化学习的新型电力系统多目标鲁棒优化方法,①相较于传统的基于群智能优化算法的多目标求解方法,得益于强化学习对长期奖励的关注,可以处理较长时间步骤的调度任务,传统方法的调度时长一般为日级别(24小时),而该方法可以处理周级别(7*24)甚至是月级别(30*24)的调度任务;②得益于深度神经网络强大的非线性处理能力,该方法相较于传统方法可以处理复杂电力系统中的非线性信息,这使得该方法不容易陷入局部最优,从而得到更好的帕累托最优解;③得益于神经网络的学习能力,该方法可以保存优化经验,这使得对于新的时间段,可以直接使用已经训练好的神经网络模型,而不是像传统算法那样重头运行优化程序,这在实际生产应用中将大大节约计算成本和计算时间。
本文地址:https://www.jishuxx.com/zhuanli/20240731/175659.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表