基于大数据的交通平台数据管理方法与流程
- 国知局
- 2024-07-31 21:06:48
本发明涉及数据处理,更具体地说,本发明涉及基于大数据的交通平台数据管理方法。
背景技术:
1、申请公开号为cn117238128a的专利公开了一种交通运输大数据管理平台,包括主控中心、数据采集模块、数据整合模块、数据分析模块和决策支持模块,主控中心配置为管理平台的控制中心,同时,主控中心还具备信号传输、数据接收和反馈模块;数据采集交通运输大数据管理平台通过在交通路网上布置传感器设备,对交通流量、车辆位置、航班信息进行实时采集;能够高效地收集、整合和分析交通运输系统中的大数据,为决策者和规划者提供真实、准确的数据支持,有助于优化交通流量、提高交通系统的效率,从而推动城市交通的可持续发展。
2、但是现有技术依然缺乏有效的数据清洗和预处理方法,原始数据中的错误和不一致性会影响后续分析和决策的准确性;传统的数据表示方式(如表格或列表)难以充分表达复杂的交通数据元素及其内在关联关系;缺乏有效的数据建模方法,无法充分挖掘数据的内在价值,导致交通状态分析的深度和广度受到限制;其次,现有技术通常只关注单一维度的交通状态指标,如拥堵程度或平均车速,难以全面反映路段的综合交通状况;无法为交通管理决策提供准确和全面的依据;并且现有模型通常是黑箱模型,难以解释交通状态的形成原因及影响因素;缺乏可解释性会影响交通管理决策的透明度和可信度,无法为决策提供有力支持和解释依据。
3、鉴于此,本发明提出基于大数据的交通平台数据管理方法以解决上述问题。
技术实现思路
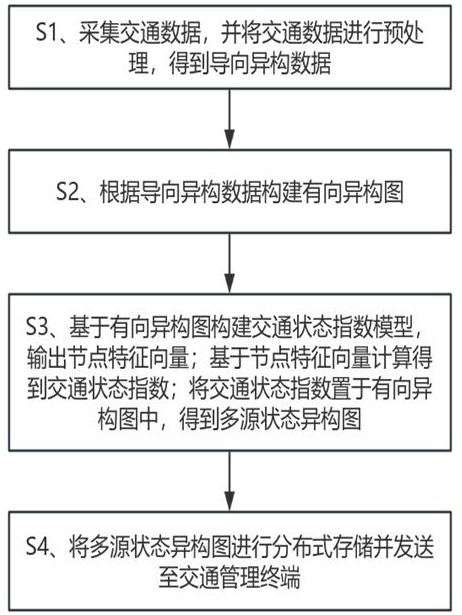
1、为了克服现有技术的上述缺陷,为实现上述目的,本发明提供如下技术方案:基于大数据的交通平台数据管理方法,包括:s1、采集交通数据,并将交通数据进行预处理,得到导向异构数据;
2、s2、根据导向异构数据构建有向异构图;
3、s3、基于有向异构图构建交通状态指数模型,输出节点特征向量;基于节点特征向量计算得到交通状态指数;将交通状态指数置于有向异构图中,得到多源状态异构图;
4、s4、将多源状态异构图进行分布式存储并发送至交通管理终端。
5、进一步地,所述交通数据包括交通流量数据、交通状态数据、道路网络数据和交通设施数据;
6、交通流量数据包括道路车辆数量和道路车辆密度;交通状态数据包括拥堵数据、行车平均速度和交通事故数据;道路网络数据包括道路拓扑结构和路段属性数据;交通设施数据包括交通灯及监控设备位置数据和配套设施数据;
7、所述将交通数据进行预处理的方式包括:
8、将交通数据进行异常值处理,得到完善交通数据;将完善交通数据进行数值型数据归一化、类别型数据编码以及特征构造;即完成交通数据的预处理;得到导向异构数据。
9、进一步地,所述异常值处理的方式包括:
10、基于统计学方法检测出异常值,将异常值划分为极端异常值和温和异常值;将极端异常值进行剔除或替换;所述替换的方式包括替换为空值或替换为临近值;将温和异常值进行平滑转换处理;
11、所述替换为临近值的方式包括:
12、用时间序列上异常值前后最近的正常值替换、用空间位置上最近的正常值替换;
13、对于交通数据,选择时间特征、空间特征和交通状态特征;将时间特征、空间特征和交通状态特征编码成特征向量;将特征向量作为样本,构成样本集;
14、对于含有极端异常值的样本,计算它与其他所有样本的距离;距离的计算使用欧几里得距离或余弦相似度;将所有计算得到的距离进行升序排序,得到排序后的样本集合n;
15、从n中选取前k个最近邻样本,记为n_k;替换为临近值的替换策略包括第一替换策略、第二替换策略和第三替换策略;
16、第一替换策略为取n_k的中值将极端异常值进行替换;第二替换策略为取n_k的均值将极端异常值进行替换;
17、第三替换策略为基于n_k拟合出概率分布模型,基于所得概率分布模型,从概率分布模型中重复随机抽取m个样本,作为模拟样本;
18、将模拟样本与n_k样本进行两样本k-s检验;若通过两样本k-s检验,则模拟样本的分布与n_k的分布无显著差异;从通过验证的模拟样本中随机抽取一个值,作为替换值;利用替换值将极端异常值进行替换。
19、进一步地,所述基于n_k拟合出概率分布的方式包括:
20、使用三角核密度估计从n_k中获取基础概率密度函数;
21、三角核密度估计的核函数为:当时,;否则;
22、对于n_k中的每个样本,计算加权核函数值的和作为基础概率密度函数的初步估计;
23、加权核函数值的和的计算公式为:
24、;其中,其中,k为最近邻样本数量,为带宽参数;为最近邻样本的索引;为第个最近邻样本;
25、对进行正态分布拟合,即初步得到概率分布模型;使用最大似然估计得到概率分布模型的参数;即得到最终的概率分布模型;所述最大似然估计的对数似然函数为:
26、;其中,为正态分布的方差;为正态分布的均值;
27、所述平滑转换处理的方式包括:
28、定义平滑转换处理的转换参数;为实数,当时,等同于不做平滑转换处理;当时,等同于将温和异常值进行对数变换,即;为对数变换后的温和异常值;当时,等同于将温和异常值进行倒数变换,即;为倒数变换后的温和异常值;
29、确定数值的方法为构建回归模型,回归模型中的数值使回归模型的残差最小化;
30、利用的数值将温和异常值进行转换,进行转换的公式为:;为转换后的温和异常值;
31、在转换后的温和异常值的空间中检测异常值,对温和异常值进行平滑处理,得到平滑异常值;
32、将进行反变换;反变换的公式为:;其中,为反变换后的平滑异常值;即完成平滑转换处理;
33、所述数值型数据归一化的方式包括:
34、对于数值型数据,利用最小-最大归一化方法或者z-score标准化,将数据归一化至[0,1]的数值区间内;
35、所述类别型数据编码的方式包括:
36、对于类别型的数据,利用one-hot编码或词嵌入编码。
37、进一步地,所述构建有向异构图的方式包括:
38、初始化定义一个异构数据集,按照导向异构数据中数据的实体类型将数据进行划分;对于实体类型对应的每个实体,提取描述其属性的属性特征向量;所有实体类型以及对应的属性特征向量构成异构数据集;
39、利用异构数据集构建异构图结构;定义异构图结构的节点层和边层;将异构数据集对应的映射到异构图结构上,即得到初步异构图;
40、节点层即为将每个实体作为一个节点;边层则是根据实体间的关系,构建异构边连接节点;将边赋予不同的类型和属性;
41、将初步异构图进行图数据增强处理;得到异构中图;
42、所述图数据增强处理的方式包括路网拓扑增强和设施影响增强;
43、所述路网拓扑增强的方式包括:
44、对于每个实体类型为路口的节点q,补充与其相连的实体类型为路段的节点集合nq;并构建路网异构边(q,p),且p∈nq;
45、所述设施影响增强的方式包括:
46、对于实体类型为设施的节点s,定义影响范围;计算影响范围内实体类型为路段的节点集合ns;并构建设施异构边(s,a),a∈ns,设施异构边的边属性为距离d(s,a),即设施与路段之间的距离;
47、将异构中图进行时空特征编码,即完成有向异构图的构建;
48、将时间看作词序列,即时间词序列;将经纬度/地点id看作地理词序列,并使用word2vec对时间词序列进行嵌入向量;得到时空嵌入向量;将时空嵌入向量作为节点/边的属性中。
49、进一步地,所述交通状态指数模型的构建方式包括:
50、定义交通状态指数模型的基础模型结构,基础模型结构包括原始节点提取结构和融合向量结构;
51、所述原始节点提取结构对于有向异构图中的每个节点,提取其本身的类型和属性作为节点原始特征向量;
52、融合向量结构用于利用图神经网络,获取有向异构图中的每个节点的邻居信息特征,并将邻居信息特征融合到对应的节点原始特征向量中;即得到节点特征向量;
53、所述节点的邻居信息特征的获取方式包括:
54、对每个节点有向异构图中的每个节点采样一个邻居子集;邻居子集内包含h个邻居节点;
55、对于采样得到的每个邻居节点,将其节点原始特征向量经过一个转换函数,转换到同一向量空间,得到对应的邻居节点特征向量;
56、将转换后的邻居节点特征向量进行聚合,得到该节点的邻居信息特征;进行聚合的方式有平均池化、最大池化或注意力池化;
57、将邻居信息特征融合到对应的节点原始特征向量的方式为向量的直接拼接。
58、进一步地,所述采样的方式包括:
59、步骤1、在有向异构图中初始定义一个中心节点v,对于中心节点v,确定采样的长度l和数量n;l表示每次采样的步数,n表示要进行的采样次数;初始化一个空集合n_v用于存储采样得到的邻居节点;
60、步骤2、从中心节点v出发,从中心节点v的所有邻居节点中等概率随机选择一个节点u,将节点u添加到当前路径中,从节点u的邻居节点中等概率随机选择一个节点作为下一步的节点;重复直到当前路径的长度达到l或者无法继续前进;将路径中经过的所有节点添加到集合n_v中;
61、重复执行步骤1-2,共进行p次,每次采样的起点都是中心节点v,但路径不同;将p次采样中经过的所有节点添加到集合n_v中;
62、将集合n_v进行去重,即去除集合n_v中重复的节点,从去重后的n_v中随机采样一个固定大小的子集n'_v;n'_v即为中心节点v的邻居子集。
63、进一步地,所述交通状态指数的获取方式包括:
64、构建一个全连接前馈神经网络,定义全连接前馈神经网络的基础架构包括输入层、个隐藏层以及输出层;
65、定义全连接前馈神经网络的损失函数;
66、;
67、其中,为训练所用的所有样本数量;为全连接前馈神经网络输出的交通状态指数;为训练所用样本的真实标注的交通状态指数;是控制线性区域范围的超参数;
68、采集历史固定时间段的交通数据,记作历史交通数据;利用历史交通数据构建有向异构图;并获取每个节点对应的节点特征向量;并将节点特征向量标注出交通状态指数;将带有交通状态指数的节点特征向量作为样本;所有样本构成训练数据集;
69、将训练数据集划分为训练集和验证集;并初始化模型参数;对于全连接前馈神经网络中的所有权重矩阵和偏置向量,使用xavier初始化分别给予权重矩阵和偏置向量一个初始值;
70、定义adam优化器和学习率调度器在训练过程中更新模型参数;
71、将学习率调度器设置一个初始学习率以及学习率衰减策略;学习率衰减策略采用阶梯式衰减;
72、将训练集中的样本输入至全连接前馈神经网络中,依次经过隐藏层和输出层,得到全连接前馈神经网络预测的交通状态指数;
73、计算损失函数的值,并计算损失函数的值关于全连接前馈神经网络中权重矩阵和偏置向量的梯度;使用adam优化器,根据梯度的方向对权重矩阵和偏置向量进行更新;在训练过程中,根据学习率调度策略动态调整学习率;利用验证集获取全连接前馈神经网络的性能指标;若性能指标在连续u个样本没有提升,则停止训练得到训练完成的全连接前馈神经网络;
74、将得到的所有节点特征向量,利用训练完成的全连接前馈神经网络预测输出得到所有节点特征向量各自对应的交通状态指数。
75、进一步地,所述输入层包含d个神经元,d个神经元对应节点特征向量的每一个维度;
76、定义个隐藏层中第一个隐藏层的神经元数量为、权重矩阵;
77、每个输入层的神经元与每个隐藏层的神经元之间均有一个连接权重;定义第一个隐藏层的偏置向量;即对应每个隐藏层神经元有一个偏置值;
78、定义第个隐藏层的神经元数量为、权重矩阵;是当前隐藏层的神经元数量;偏置向量为;
79、将节点特征向量依次通过隐藏层进行计算,即第一个隐藏层进行计算的公式为:;
80、第个隐藏层进行计算的公式为:;其中为激活函数;是第个隐藏层的上一隐藏层的神经元数量;
81、输出层仅设置一个神经元,对应最终的交通状态指数的值;
82、定义输出层的权重矩阵wout;输出层的偏置值bout;权重矩阵wout中的每个元素都是一个权重值,它将与第个隐藏层的每个神经元输出相连接;
83、将第个隐藏层的输出与权重矩阵wout进行矩阵乘法,得到一个标量值;将标量值加上偏置值bout,即得到交通状态指数;其中不使用任何激活函数,直接输出。
84、进一步地,所述多源状态异构图的获取方式为将所有节点特征向量各自对应的交通状态指数作为有向异构图中节点的属性保存;即得到多源状态异构图;
85、所述将多源状态异构图进行分布式存储的方式包括:
86、将多源状态异构图按照节点的类型进行分片,将整个多源状态异构图分割成h个的数据块;每个数据块包含节点、边以及相关的属性;
87、将分片后的数据存储到不同的节点上;对于读写请求,通过负载均衡策略将其分发到不同的节点;负载均衡策略为随机、最小连接数或一致性哈希;
88、并对存储的多源状态异构图进行压缩,即完成分布式存储。
89、本发明基于大数据的交通平台数据管理方法的技术效果和优点:
90、本发明通过数据处理有效消除了原始交通数据中的异常值和噪声,确保了数据的高质量和可靠性;借助异构图模型,能够自然地表达复杂的交通数据元素及其内在关联,充分挖掘数据的内在价值,为全面分析交通状态提供了强有力的支持;基于图神经网络构建了综合交通状态指数模型,能够全面反映路段的拥堵程度、平均车速等多维度交通状态,为交通管理决策提供了准确的依据;模型基于有向异构图构建,具有良好的可解释性,能够清晰呈现交通状态的形成原因及影响因素,为交通管理决策提供了有力支持和解释依据。
本文地址:https://www.jishuxx.com/zhuanli/20240731/188416.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表