一种基于强化学习的分层式区域协调信号控制方法
- 国知局
- 2024-07-31 21:06:29
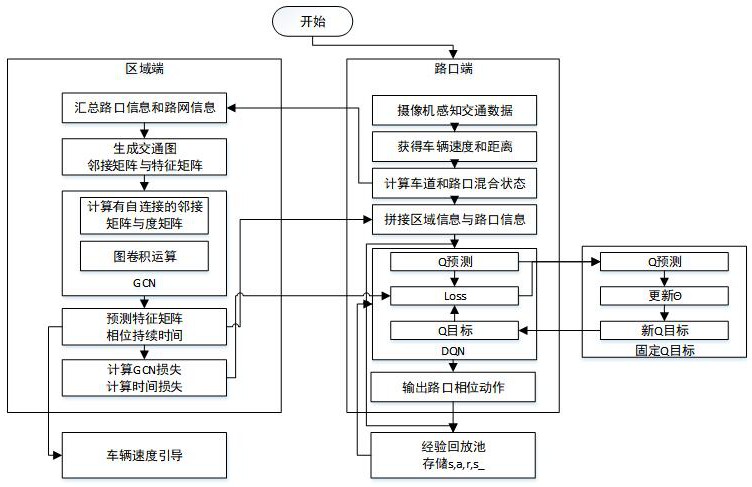
本发明涉及一种基于强化学习的分层式区域协调信号控制方法,涉及智能交通。
背景技术:
1、在现代城市交通管理领域,交通拥堵、交通事故和紧急救援的复杂性日益增加,需要创新性的方法来解决这些问题,传统的交通信号控制和车辆协同方法常常难以适应不断变化的交通情况,特别是随机性的交通事故发生与非理性驾驶行为发生时,问题更加复杂;
2、强化学习算法是应对这些挑战的一种极具潜力的方法,强化学习算法能够使交通系统在实时环境中不断学习和优化决策,控制信号灯做出准确的相位变化,强化学习算法可以在虚拟环境中训练,在真实环境中部署,有效减少训练成本和时间,强化学习算法可同时控制多智能体协同运动,有效解决交叉口复杂车况协同控制的问题,但是,现有强化学习的交叉口控制方法准确性不高、实时控制效果较差以及路口间的协同效果差,为此,我们提出一种基于强化学习的分层式区域协调信号控制。
3、与现有技术对比如下:
4、与专利cn 113299079 b“一种基于ppo和图卷积神经网络区域交叉口信号控制方法”的技术对比中
5、1、专利cn 113299079 b中,涉及的分层理念体现该控制模型具有上下两层结构,下层结构为基于ppo强化学习算法的单点交叉口控制模型,上层结构为基于图卷积神经网络的区域统筹控制模型。但上层输出是预测车辆数作为动作,该方法的时间步为5s,但该动作空间会随着时间步长和路口数变大,依赖于极高信息交互频率,制约了在信息交互差地区使用。本专利的分层主要体现在上层区域进行状态预测输出时间长度后的状态,下层路口端结合预测状态很当前状态进行决策,区域层的状态变化从环境获得训练难度不随空间和时间维度变化显著,可以适应较低的信息交互情况。
6、2、专利cn 113299079 b中,单交叉口的的状态由车道的车辆数和路口相位表示,具有较强的可操作性,但是单一交通状态对交叉口状态的真实状态很难充分表达。针对这一问题,利用路口摄像机这一现有设备采用yolo算法获得单车级数据和计数型数据,即车辆速度、位置、道路车辆数和停车数,通过单车级的数据跟细致的描述交叉口真实状态,同时为了惩罚排队对车辆位置进行平方处理。
7、3、专利cn 113299079 b中,上层采用的图卷积神经网络主要是通过增加图卷积层数的方式增加对于空间信息的提取,但是对于图卷积的本身没有进行具体的设计。本专利针对交叉口考虑周围状态要结合本交叉运行情况,在图卷积积中使用采集的道路车辆数和停车数计算路口效率来修正自邻接矩阵,使得使用图卷积进行空间特征提取的时候进一步考虑到路口效率对于状态的影响。
8、与专利cn 114627657 a“一种基于图深度强化学习的自适应交通信号控制方法”的技术对比中
9、1、专利cn 114627657 a中,使用了双层图卷积神经网络提取全局信息给路口决策使用,提升了决策信息的有效性,但是对于图卷积的本身没有进行具体的设计。本专利针对交叉口考虑周围状态要结合本交叉运行情况,在图卷积积中使用采集的道路车辆数和停车数计算路口效率来修正自邻接矩阵,使得使用图卷积进行空间特征提取的时候进一步考虑到路口效率对于状态的影响。
10、2、专利cn 114627657 a中,路口输出的动作是定频率的相位切换,可以很好的应对交叉口的突发状况,但是在现实中当前相位的持续实现也是影响驾驶员驾驶行为的因素,针对该问题,本专利在区域层让区域根据全局的交通趋势输出一个当前相位的持续时间预测值,该值不会影响实际相位执行,该值预测的训练可以通过预测值和实际持续时间之差进行预测模型更新。
11、3、专利cn 114627657 a中,状态表达方面使用了单车级数据,通过排队长度,车辆数和平均速度来表达交叉口的交通状态,可以较为全面的反应交叉口的真实状况,但是对于现有数据应用不充分,针对这一问题,利用车辆速度和位置构建状态表达函数可以跟充分的利用收集的单车级数据,同时为了惩罚排队对车辆位置进行平方处理。
技术实现思路
1、针对以上问题,本发明提出了一种基于强化学习的分层式区域协调信号控制方法,通过摄像头收集的单车级数据进行合理的状态表示作为路口端决策的依据,调高了决策的科学性。通过区域层使用gcn预测全局交通状态,向区域端发生目标,进一步丰富路口决策信息内容。
2、为实现上述目的,本发明采取的技术方案是:
3、一种基于强化学习的分层式区域协调信号控制方法,所述控制方法包含以下步骤:
4、步骤一、确定路口终端的收集和计算周期,选取时间为5s、10s以及20s其中之一,路口终端通过摄像头收集t1时刻距离路口x米的车辆数据、计数信息和信号状态l,并计算得到车道的混合状态slane和路口的混合状态sintersection,其中车辆数据包括车辆位置xi和车辆速度vi,计数信息包括车辆总数ncar和停车总数nstop,路口的混合状态sintersection包括8个进口车道的车道的混合状态slane;
5、步骤二、区域终端通过接收路口终端t1时刻的混合状态,生成区域交通的当前交通图g1(a,h),其中a是交叉口的邻接关系矩阵,h是包含各路口的混合状态的混合交通状态矩阵,结合路网状态计算自邻接矩阵并预测1t时间后混合状态生成预测交通图g2和这个路口的信号持续时间l;
6、步骤三、路口终端通过接收t1时刻的预测交通图g2中预测路口的混合状态sintersection_predict,利用路口端的强化学习控制器生成控制策略数据,并将交互策略存入经验池;
7、步骤四、测算区域终端用于预测损失值,其中包括1t时间后的实际交通图g3和预测交通图g2之间的差距,以及预测信号的持续时间l和路口断相位保持不变的累计持续时间之间的差距;
8、步骤五、采用路口端强化学习运用dqn算法,奖励设置保持和路口端混合状态的高度一致性;
9、步骤六、基于路口的信号持续时间l,对车速进行合理的引导。
10、作为本发明进一步改进,所述第一步骤中路口的车道混合状态slane包括车道车辆当前的速度vi和距离xi,路口的监控终端实时采集的影像数据通过yolo算法获得,其运行公式为:
11、
12、其中xi表示车辆流量,vi表示车辆速度,将实际的xi值和vi值带入公式中进行计算。
13、作为本发明进一步改进,所述第二步骤中自邻接矩阵考虑了所述第一步骤中的计数信息包括车辆总数ncar和停车总数nstop,其运行公式如下:
14、
15、
16、其中是调整后的单位矩阵,i是单位矩阵,下标ii表示i中第i行第i列元素。
17、作为本发明进一步改进,所述步骤六中所提及的dqn算法是一种基于强化学习的分层式区域协调信号控制,dqn的训练过程包括以下步骤:
18、s1、经验回放,将agent在环境中的经验存储在经验回放缓冲区中,随机抽取这些经验用于训练,减少数据间的相关性;
19、s2、目标网络,dqn使用两个神经网络:一个是评估网络q-network,用于选择动作和计算q值;另一个是目标网络,用于计算目标q值;
20、s3、ε-greedy策略,agent会以一定的概率ε进行探索,选择非最优动作,以便探索更多的状态空间。
21、作为本发明进一步改进,所述步骤一中的速度以米每秒m/s表示,距离为该车到信号灯的距离以米m表示。
22、作为本发明进一步改进,所述步骤二中区域终端为了把握整个路网流量的变化趋势,包括预测时间,可预测临近路口影响本路口交通情况的问题。
23、作为本发明进一步改进,所述第二步骤与第三步骤中区域终端生成的当前交通图g1和预测交通图g2,该路口的持续时间l与当前信号状态l不冲突,持续时间l是为了帮助驾驶员更好调整当前车速,并不是具体执行时间。
24、采用上述技术方案,与现有技术相比,本发明的有益效果在于:
25、1、确定路口终端的收集和计算周期,选取时间为5s、10s以及20s其中之一,路口终端通过摄像头收集t1时刻距离路口x米的车辆数据、计数信息和信号状态l,并计算得到车道的混合状态slane和路口的混合状态sintersetion,其中车辆数据包括车辆位置xi和车辆速度vi,计数信息包括车辆总数ncar和停车总数nstop,路口的混合状态sintersetion包括8个进口车道的车道的混合状态slane;
26、2、本发明通过路口端收集的数据实时传输至区域终端,区域端生成区域交通的当前交通图g1,结合路网状态计算自邻接矩阵并预测1t时间后混合状态生成预测交通图g2和这个路口的信号持续时间l,有利于交叉口从路网层面宏观把握交通变化趋势,生成适合本路的相位动作,同时区域端会生成相位持续时长预测,便于司机做出恰当驾驶行为。
本文地址:https://www.jishuxx.com/zhuanli/20240731/188390.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表