一种基于激光视觉融合算法的车辆超限报警系统
- 国知局
- 2024-07-31 21:08:49
本发明涉及激光雷达、图像识别、目标检测相关,具体涉及一种基于激光视觉融合算法的车辆超限报警系统。
背景技术:
1、近年来,我国经济蓬勃发展,道路交通运输扮演着至关重要的角色。随着交通便利性的提升,汽车总数不断攀升。截至2023年9月,全国机动车保有量已达4.3亿辆,其中汽车占据了3.3亿辆,成为我国主要的出行方式之一。然而,这也带来了一些问题。在交通运输行业中,运输车辆常因车身宽大,在遇到限高杆、涵洞等障碍物时,驾驶员往往无法准确估计车辆的安全通行高度,导致运输事故频发。
2、目前车辆超限(超宽和超高)报警领域实现测距的方式主要有雷达与相机两种。雷达方面是采用毫米波雷达、激光雷达和双目相机作为车载测距传感器,毫米波雷达与激光雷达的工作原理是通过计算发送与接收电磁波的时间差来进行距离的测量,这样的方式具有分辨率高、隐蔽性好、抗有源干扰能力强、低空探测性能好、体积小、质量轻等优点;但是会受环境的影响大、容易受到干扰、不能分辨障碍物的类别等缺点。
3、相机方面采用双目相机形式,利用立体成像原理,可以通过左右相机分别拍摄图片然后进行立体匹配,计算障碍物的视差值,使得相机可以像人的眼睛一样感知障碍物的距离,配合目标检测算法还可以识别障碍物的类别。该方式具有测距且分辨障碍物类别的能力、通用性好、价格低廉、体积小等优点。但它也有一些缺点,比如受环境的影响大、对于两个相机的标定依赖高、测距精度低等缺点。
技术实现思路
1、针对上述的技术问题,本技术方案提供了一种基于激光视觉融合算法的车辆超限报警系统,通过改进的yolov9与lvi-sam融合得到激光视觉融合算法,并用激光视觉融合算法检测限高杆或涵洞的长度和宽度,结合了纯视觉和纯雷达的优点,即高准确度的物体类别识别和较小的物体真实位置测量误差,实现对目标真实位置的精准定位;能有效的解决上述问题。
2、本发明通过以下技术方案实现:
3、一种基于激光视觉融合算法的车辆超限报警系统,将激光视觉融合算法直接部署在移动终端,之后将终端安装到车辆上;通过调试雷达与相机的位置,以完成相机与雷达的标定,提高终端测量涵洞与限高杆的位置信息精确度;其特征在于:包括步骤:
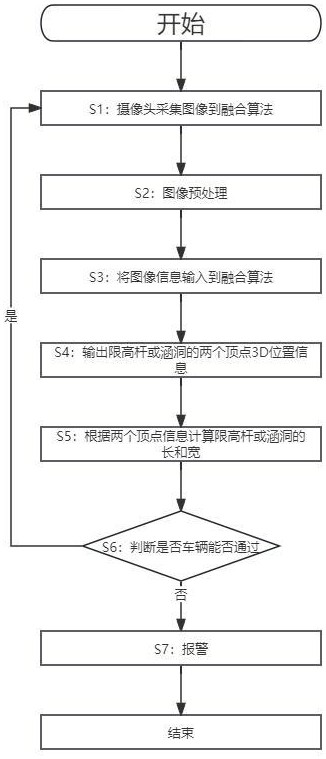
4、s1:使用相机与雷达采集车辆前方路段信息;
5、s2:对相机采集到的图像进行预处理;
6、s3:将步骤s2中预处理后的图像与激光雷达采集的点云信息,输入到激光视觉融合算法中检测限高杆或涵洞;所述的激光视觉融合算法由改进yolov9与lvi-sam结合而成,所述改进的yolov9是将crcb的注意力机制引入到yolov9;
7、s4:算法输出限高杆或涵洞的两个顶点3d位置信息;
8、s5:根据s4得到的两个顶点3d位置信息计算限高杆或涵洞的长和宽;
9、s6:根据上一步骤得到的限高杆或涵洞的长和宽与车辆的长宽比较,判断车辆是否能够通过。当判断车辆不能通过时执行s7,能够通过时执行s1;
10、s7:车辆不能通行,提示报警。
11、进一步的,步骤s1的具体操作方式为:将雷达安装到车辆顶部,相机安装到车辆头部位置,使相机有一个开阔的视野,获取车辆前方路段的图像。
12、进一步的,步骤s2对相机采集到的图像进行预处理是通过图像预处理消除图像中无关的信息,恢复有用的真实信息,增强有关信息的可检测性;具体的处理流程为:
13、s21:输入相机采集到的图像;
14、s22:对图像进行灰度化处理:使用平均值法,将彩色图像中的三分量亮度求平均得到一个灰度值,完成灰度图像的转换;
15、s23:对图像进行几何变换处理,通过对图像进行平移、转置、镜像、旋转、缩放的处理,用于改正图像采集系统的系统误差和仪器位置的随机误差;
16、s24:对图像进行图像增强处理,通过使用求平均值法和中值滤波法,去除或减弱噪声;
17、s25:输出处理完成的图像。
18、进一步的,步骤s3中所述crcb的注意力机制由十字交叉和eca注意力机制融合而成,当采集到的原始图像输入到十字交叉注意力机制后,而后将原始图像分别与3个1×1的卷积核进行降维处理,第一个和第二个卷积核得到的图像进行affinity操作后,再使用softmax函数得到权重图;之后,将权重图与第三个1×1的卷积核得到的图进行aggregation后,输出特征图;所用公式为:
19、
20、其中,q、k是通过卷积核为1×1的卷积对输入图像的通道进行降维得到图像,a是由两者通过affinity后经过softmax函数得到的权重图,h为原始图像,a与h同维的v进行aggregation操作得到最终特征图h';k代表尺度为h+w-1的一个子集,qj代表q的空间维度上每个像素,di,j为出两者的相似性的度量,h,w为特征图的高和宽,i,j分别为特征图行数和列数,t为矩阵转置;
21、将原始图像输入到十字交叉注意力机制得到一个特征图后,再将特征图输入到eca注意力机制中,通过sigmoid激活函数获取输入的特征图各个通道的权重值w,再将原始图像与特征图各个通道的权重值w相乘,输出最终的特征图;所用公式为:
22、w=σ(c1h(y))
23、
24、
25、其中,c1h为一维卷积,h为卷积核大小;odd表示h取奇数,γ和b为常数,用以维护通道数和卷积核大小的数量关系,c为通道数,σ为sigmoid函数,y为通道数的平均池化。
26、进一步的,步骤3中所述的改进yolov9模块需要提前对限高杆或涵洞进行数据采集与模型训练,具体操作方式为:构建数据集,通过摄像头采集限高杆或涵洞图像信息构建数据集,用于改进yolov9模型训练;经过训练得到最优训练结果权重文件和最后训练结果权重文件,最优训练结果文件作为最优检测模型。
27、进一步的,步骤3中所述激光视觉融合算法的运行流程包括以下步骤:
28、s31:在激光点云处理模块中,特征提取模块对点云信息中具有鲜明几何结构的点云特征进行提取,并对其进行分析,再将它们作为点云地图中的关键特征点;
29、s32:激光点云特征匹配模块对步骤s31中提取到的特征点进行计算特征描述子,所述的描述子通常包含有关特征点周围区域的信息;接着,通过比较当前时刻的特征点描述子与之前时刻或地图中的特征点描述子,进行特征匹配,计算当前时刻无人车在点云地图中的位置和姿态,作为激光雷达里程计的输出;
30、s33:多传感器图优化模块通过整合激光雷达里程计和惯性测量单元模块中输出的无人车的位姿信息,利用图优化方法来提高系统位姿估计的精度、鲁棒性和全局一致性;
31、s34:基于激光雷达辅助视觉惯性里程计的垃圾三维坐标转换模块接收激光惯性系统采集到的视觉特征点的深度信息,来对视觉惯性系统进行初始化操作,提高其位置和姿态估计的精度;
32、s35:深度配准模块将视觉里程计中视觉特征点与激光雷达特征提取模块去畸变后的点云信息中的深度进行关联,以便更准确地估计无人车的位置和姿态。
33、s36:改进yolov9模块使用标注框标注2d图像中的涵洞或限高杆位置,并提供标注框的两个顶点位置信息;而后,将两个顶点位置信息传递给视觉特征跟踪模块,与其2d视觉特征点进行距离公式计算,找到离两个顶点位置最近的视觉特征点;为确保后续的二维坐标点到三维坐标点的转换正确,采用每个视觉特征点的唯一标识进行操作;
34、s37:基于激光雷达辅助视觉惯性里程计的垃圾三维坐标转换模块接收视觉特征跟踪模块传送过来的视觉特征点与两个顶点坐标匹配的id值;之后,通过id值找到2d视觉特征点所对应的真实世界坐标。
35、进一步的,步骤s4中通过算法输出限高杆或涵洞的两个顶点3d位置信息,其具体操作方式为:经过步骤s3中的算法对相机与激光雷达采集的信息进行处理后,输出通过算法得到的限高杆或涵洞的两个顶点3d位置坐标,此坐标系的构成是以车辆起始点为原点,以车辆头部朝向为x轴,左右为y轴,上下为z轴进行定点。
36、进一步的,步骤s5中计算限高杆或涵洞的长和宽的方式为:限高杆或涵洞的长为两个顶点坐标y轴方向向量相加,限高杆或涵洞的长宽为两个顶点的z轴方向向量。
37、有益效果
38、本发明提出的一种基于激光视觉融合算法的车辆超限报警系统,与现有技术相比较,其具有以下有益效果:
39、(1)本发明将crcb的注意力机制引入到目标检测算法yolov9中,然后与slam算法lvi-sam进行融合,使得系统不仅可以获取物体类别,还能获取物体的深度信息。激光视觉融合算法首先使用标注框标记目标物体,然后将标注框的两个顶点传送到slam算法部分进行深度配准,能将物体的二维坐标转化为三维坐标,从而实现对目标真实位置的精准定位。同时,激光视觉融合算法结合了纯视觉和纯雷达的优点,即高准确度的物体类别识别和较小的物体真实位置测量误差。此外,系统从识别物体到计算出物体的长度与宽度所需的时间也完全能够满足需求。
40、(2)本发明中的激光视觉融合算法由改进的yolov9与lvi-sam融合而成,采用分层式技术架构处理视觉数据流与激光点云数据流,分层式的物体位置估计技术架构,不同于传统ai视觉的端到端输入输出模式;基于改进改进yolov9模型和lvi-sam模型的限高杆或涵洞3d位置估计算法,实现了限高杆或涵洞识别与3d位置估计,改变现有方法中无法对限高杆或涵洞与其他物体进行有效区分和3d位置估计精度低的问题。
本文地址:https://www.jishuxx.com/zhuanli/20240731/188562.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表