一种滑坡位移预测方法、存储介质、设备
- 国知局
- 2024-08-05 11:44:20
本发明涉及地质位移预测,尤其涉及一种滑坡位移预测方法、存储介质、设备。
背景技术:
1、滑坡是指由于重力、地形、降雨等因素导致大量土壤和岩石突然向下滑动或流动的自然现象,其可以发生在陡坡、山脚、河岸等地形,在一些情况下滑坡可能会造成严重的财产损失和人员伤亡。由于滑坡现象的发生存在突发性和未知性,对滑坡位移进行预测可以提前采取预防措施,降低灾害风险,保护大众的生命财产安全,也有助于加深对地质灾害机理的理解与认识。
2、目前的滑坡位移预测主要采用模型预测。预测模型主要分为物理模型以及数据驱动模型。物理模型引入地质、地形和水文等物理因素,通过模拟土体力学行为来预测滑坡,其提供了对土体行为的物理解释,有助于理解滑坡的机制,但依赖于复杂的物理方程和参数,模型的不确定性较高。数据驱动模型则引入历史数据和监测的数据,利用统计学以及机器学习等方法建立模型来预测滑坡,适用于复杂的地质环境,能够处理多维的数据和非线性关系,但模型可能缺乏物理解释性,对数据质量和特征选择要求高,所以如何对滑坡位移数据特征进行有效提取,是当前数据驱动模型需要改进的地方。
3、采用深度学习的方法来构建滑坡预测模型是当前主流的预测方法,其中包括了循环神经网络(rnn)、卷积神经网络(cnn)、深度神经网络(dnn)等神经网络模型,其中隶属于循环神经网络的长短期记忆神经网络(lstm)、门控循环单元(gru)等模型广泛用于滑坡位移预测之中。专利cn202110311836.3中使用了gru来对滑坡位移进行预测,其相比于传统深度学习方法,能够解决rnn在处理长序列数据时出现的梯度消失或爆炸问题,但在处理长序列时,仍然存在信息衰减或遗忘的问题。总的来看,由于滑坡位移受到多种复杂因素的影响,其依赖的数据具有高度的随机性、多源性以及不确定性,故而难以全面的捕捉到这些因素之间的复杂关系,位移预测精度还有待提升。
技术实现思路
1、本发明的目的在于:为了解决现有技术存在的难以捕捉到滑坡位移因素之间的复杂关系,预测精度不高的问题,提出一种滑坡位移预测方法,包括以下步骤:
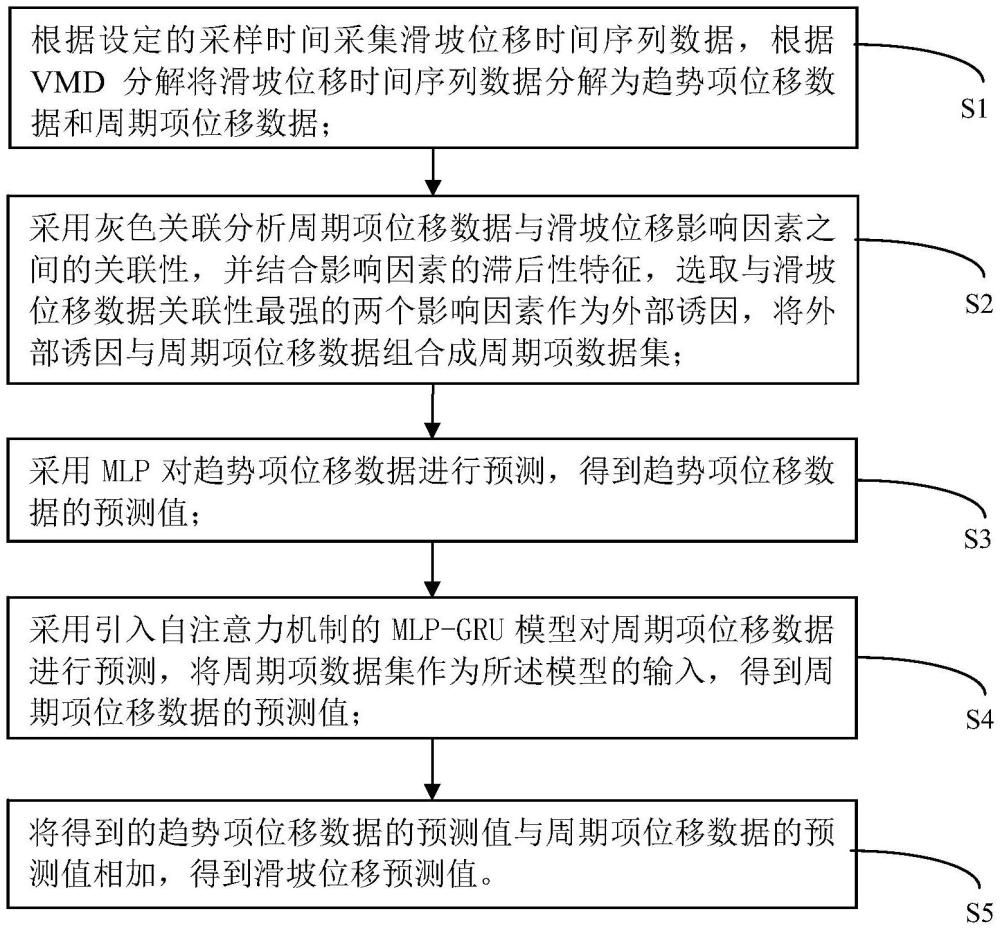
2、s1、根据设定的采样时间采集滑坡位移时间序列数据,根据vmd分解将滑坡位移时间序列数据分解为趋势项位移数据和周期项位移数据;
3、s2、采用灰色关联分析周期项位移数据与滑坡位移影响因素之间的关联性,并结合影响因素的滞后性特征,选取与滑坡位移数据关联性最强的两个影响因素作为外部诱因,将外部诱因与周期项位移数据组合成周期项数据集;
4、s3、采用mlp对趋势项位移数据进行预测,得到趋势项位移数据的预测值;
5、s4、采用引入自注意力机制的mlp-gru模型对周期项位移数据进行预测,将周期项数据集作为所述模型的输入,得到周期项位移数据的预测值;
6、其中,引入自注意力机制的mlp-gru模型包括mlp单元、门控循环单元、自注意力单元以及两个全连接层和输出层;
7、周期项位移数据输入mlp单元,提取特征向量,将mlp单元提取的特征向量输入门控循环单元得到隐藏状态,利用自注意力单元注意不同时间步的隐藏状态在门控循环单元的各层之间传递时的相关性,得到全局特征向量,利用两个全连接层实现对全局特征向量的线性回归计算,并从输出层输出周期项位移数据的预测值。
8、s5、将得到的趋势项位移数据的预测值与周期项位移数据的预测值相加,得到滑坡位移预测值。
9、进一步地,根据vmd分解将滑坡位移时间序列数据分解为趋势项位移数据和周期项位移数据,具体为:
10、vmd处理过程由公式表达如下:
11、
12、其中,{uk}={u1,u2,...,uk},{ωk}={ω1,ω2,...,ωk},k表示模态分解个数,f为原始信号,uk表示分解出的第k个模态,ωk表示第k个模态的中心频率,表示对t求偏导符号,δ(t)表示狄拉克函数,j表示虚数,uk(t)表示分解出的第k个模态在时域上的表示,‖‖2表示2范数;
13、约束条件为分解出的模态和为原始信号,通过增广拉格朗日函数将上述等式约束优化问题等效为一个无约束优化问题,如下:
14、
15、其中,l({uk},{ωk},λ)表示关于{uk}、{ωk}、λ的增广拉格朗日函数,λ表示拉格朗日乘法算子,α表示二次惩罚因子,f(t)表示原始信号在时域上的表示,λ(t)表示拉格朗日乘法算子在时域上的表示;
16、求解上述等式约束优化问题通过交替方向乘子迭代算法求解。
17、进一步地,灰色关联分析的公式为:
18、
19、其中,ζi(k)表示y(k)与xi(k)的关联性,y(k)表示周期项位移数据的在第k个时刻的值,xi(k)表示滑坡位移影响因素的第i个因素在第k个时刻的值,ρ表示分辨系数。
20、进一步地,采用mlp对趋势项位移数据进行预测,具体为:
21、将前若干个采样时间内采集的趋势项位移数据输入mlp,对下一个采样时间的趋势项位移数据进行预测。
22、进一步地,周期项位移数据输入mlp单元,提取特征向量,表示为:
23、h=φ(xwh+bh)
24、其中,φ表示激活函数,x表示输入,这里表示周期项数据集,wh和bh分别表示mlp单元的输出权重和偏置,h为提取的特征向量。
25、进一步地,将mlp单元提取的特征向量输入门控循环单元得到隐藏状态,表示为:
26、zt=σ(wz.[ht-1,h]+bz)
27、rt=σ(wr.[ht-1,h]+br)
28、
29、
30、其中,wz、wr、wc分别为更新门、重置门、隐藏状态的权重矩阵,bz、br、bc分别为更新门、重置门、隐藏状态的偏置,σ是sigmoid激活函数,zt表示t时刻的重置门,rt表示t时刻的更新门,ht表示t时刻的隐藏状态,ht-1表示t时刻的隐藏状态,表示t时刻的候选隐藏状态,*表示卷积运算。
31、进一步地,利用自注意力单元注意不同时间步的隐藏状态在门控循环单元的各层之间传递时的相关性,得到全局特征向量,具体为:
32、qn=hn·wq
33、kn=hn·wk
34、vn=hn·wv
35、其中,qn表示自注意力单元在门控循环单元第n个时间步的查询向量,hn表示门控循环单元第n个时间步的隐藏状态向量,wq表示qn的权重矩阵,kn表示自注意力单元在门控循环单元第n个时间步的键向量,wk表示kn的权重矩阵,vn表示自注意力单元在门控循环单元第n个时间步的值向量,wv表示vn的权重矩阵;
36、自注意力单元计算不同向量的查询向量与键向量之间的相关性得到相关性矩阵
37、
38、其中,表示相关性矩阵;
39、根据相关性矩阵计算门控循环单元的隐藏状态向量之间的相关性:
40、
41、其中,wn表示门控循环单元第n个时间步的隐藏状态向量之间相关性,将wn作为门控循环单元第n个时间步的自注意力权重,对vn进行加权得到经过自注意力单元计算后的门控循环单元第n个时间步的隐藏状态向量:
42、hn=wnvn
43、其中,hn表示经过自注意力单元计算后的门控循环单元第n个时间步的隐
44、藏状态向量;基于hn,通过门控循环单元输出全局特征向量。
45、本发明还提出一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述的滑坡位移预测方法。
46、本发明还提出一种电子设备,包括处理器和存储器,所述处理器与所述存储器相互连接,其中,所述存储器用于存储计算机程序,所述计算机程序包括计算机可读指令,所述处理器被配置用于调用所述计算机可读指令,执行上述的滑坡位移预测方法。
47、本发明提供的技术方案带来的有益效果是:
48、本发明通过vmd分解将滑坡位移时间序列数据分解为趋势项位移数据和周期项位移数据;采用灰色关联分析周期项位移数据与滑坡位移影响因素之间的关联性,采用mlp对趋势项位移数据进行预测,得到趋势项位移数据的预测值;采用引入自注意力机制的mlp-gru模型对周期项位移数据进行预测,得到周期项位移数据的预测值;多层感知机(mlp)能够学习复杂的非线性关系,其全连接结构有助于处理高维特征,而门控循环单元(gru)能够捕捉时间序列数据中长期依赖关系,通过mlp快速提取数据特征的能力,减少了gru对数据的计算,自注意力单元能注意不同时间步的包含空间特征与时间特征的隐藏状态在门控循环单元的各层之间传递时的相关性,提高了模型的预测效率。
本文地址:https://www.jishuxx.com/zhuanli/20240802/259127.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。