基于关系图卷积神经网络的中文作者姓名消歧方法及装置
- 国知局
- 2024-08-05 11:50:14
本发明涉及姓名消歧,特别是指一种基于关系图卷积神经网络的中文作者姓名消歧方法及装置。
背景技术:
1、随着研究产出的逐步增加,中文论文中的作者重名现象不可避免地日益增多,该现象给科学文献管理、科研能力评价和数据分析任务带来了诸多挑战,严重影响了很多数据集的准确性和科学性。作者姓名消歧,是命名实体消歧的一个分支,就是把同名的作者通过分析以识别出真正对应的作者是否为同一个人的过程。目前,几乎所有的姓名消歧技术都是针对英文论文中的英文姓名消歧研究,而针对中文论文中的中文姓名消歧相对较少。
2、目前已有进行作者姓名消歧方法主要是基于传统的机器学习方法,传统的机器学习的消歧方法包括三类:无监督、半监督和有监督的机器学习方法。它们三者的区别在于是否利用数据集的标签标识进行训练。
3、(1)无监督的作者姓名消歧方法
4、无监督的作者姓名消歧方法,是根据作者所发论文的特征,即论文标题、论文分区、论文关键词等进行聚类分析。一般采取k-means、dbscan等传统的聚类方式。由于其不需要标注数据、节省巨大的人力物力而得到较多的应用,其中cota等人基于层次聚类的方法对论文的一些指标进行相似性度量。但实际上这种方法的准确率相对较差,无法得出精准的结果。
5、(2)有监督的作者姓名消歧方法
6、有监督的作者姓名消歧方法,是根据人工标注好的数据同样根据论文的特征和作者单位等指标进行分类,较为常用的有支持向量机模型(svm)和朴素贝叶斯模型。其中han等人提取了共同发布作者姓名、论文标题和论文发表的刊物三个参数,生成每篇论文的语义指纹,通过支持向量机和朴素贝叶斯训练出两种分类器,从而达到姓名消歧的目的。但巨大的人工标注成本使得这样的方法注定不适用于大数据量的任务,因此,其应用的范围较少。
7、(3)半监督的作者姓名消歧方法
8、半监督的作者姓名消歧方法,是介于无监督和半监督二者之间的方法,只需要标注小部分的数据,然后用这小部分的数据来训练大部分未标注的数据,有助于提升训练的准确性。但这种方法不仅比较复杂,人为的标注也可能带来一些误差。
9、传统的机器学习的方式在处理大规模、复杂的学术数据时有局限性,不能全面且快捷地得出结果,导致作者姓名消歧的成本较大,准确率低且效率低。
技术实现思路
1、为了解决现有技术存在的作者姓名消歧的成本较大,准确率低且效率低的技术问题,本发明实施例提供了一种基于关系图卷积神经网络的中文作者姓名消歧方法及装置。所述技术方案如下:
2、一方面,提供了一种基于关系图卷积神经网络的中文作者姓名消歧方法,该方法由基于关系图卷积神经网络的中文作者姓名消歧设备实现,该方法包括:
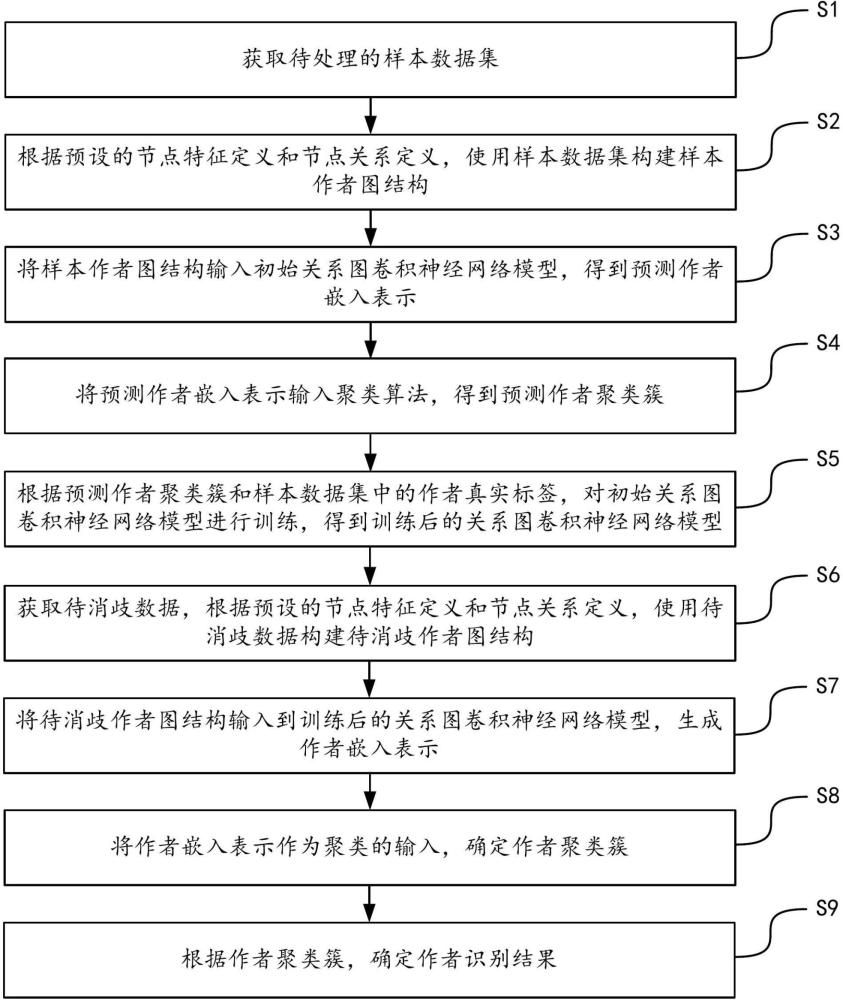
3、s1、获取待处理的样本数据集;
4、s2、根据预设的节点特征定义和节点关系定义,使用所述样本数据集构建样本作者图结构;
5、s3、将样本作者图结构输入初始关系图卷积神经网络模型,得到预测作者嵌入表示;
6、s4、将所述预测作者嵌入表示输入聚类算法,得到预测作者聚类簇;
7、s5、根据预测作者聚类簇和样本数据集中的作者真实标签,对初始关系图卷积神经网络模型进行训练,得到训练后的关系图卷积神经网络模型;
8、s6、获取待消歧数据,根据预设的节点特征定义和节点关系定义,使用所述待消歧数据构建待消歧作者图结构;
9、s7、将待消歧作者图结构输入到训练后的关系图卷积神经网络模型,生成作者嵌入表示;
10、s8、将所述作者嵌入表示作为聚类的输入,确定作者聚类簇;
11、s9、根据所述作者聚类簇,确定作者识别结果。
12、另一方面,提供了一种基于关系图卷积神经网络的中文作者姓名消歧装置,该装置应用于基于关系图卷积神经网络的中文作者姓名消歧方法,该装置包括:
13、获取单元,用于获取待处理的样本数据集;
14、第一构建单元,用于根据预设的节点特征定义和节点关系定义,使用所述样本数据集构建样本作者图结构;
15、预测单元,用于将样本作者图结构输入初始关系图卷积神经网络模型,得到预测作者嵌入表示;
16、第一聚类单元,用于将所述预测作者嵌入表示输入聚类算法,得到预测作者聚类簇;
17、训练单元,用于根据预测作者聚类簇和样本数据集中的作者真实标签,对初始关系图卷积神经网络模型进行训练,得到训练后的关系图卷积神经网络模型;
18、第二构建单元,用于获取待消歧数据,根据预设的节点特征定义和节点关系定义,使用所述待消歧数据构建待消歧作者图结构;
19、生成单元,用于将待消歧作者图结构输入到训练后的关系图卷积神经网络模型,生成作者嵌入表示;
20、第二聚类单元,用于将所述作者嵌入表示作为聚类的输入,确定作者聚类簇;
21、识别单元,用于根据所述作者聚类簇,确定作者识别结果。
22、另一方面,提供一种基于关系图卷积神经网络的中文作者姓名消歧设备,所述基于关系图卷积神经网络的中文作者姓名消歧设备包括:处理器;存储器,所述存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,实现如上述基于关系图卷积神经网络的中文作者姓名消歧方法中的任一项方法。
23、另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现上述基于关系图卷积神经网络的中文作者姓名消歧方法中的任一项方法。
24、本发明实施例提供的技术方案带来的有益效果至少包括:
25、本发明实施例提供了一种基于关系图卷积神经网络的中文作者姓名消歧方法,来区分相同中文名字的不同中文作者。首先,本发明实施例提出进行作者图的节点特征构建和节点关系构建方法,给出了关系判断规则。其次,本发明实施例提出结合图扰动技术对r-gcn的算法进行训练,基于训练后的r-gcn获取作者嵌入表示。最后,基于dbscan进行作者聚类。相较于以往单纯使用某一种词嵌入表示方式进行作者表征,本发明实施例提出的基于fasttext获得作者多种信息的词嵌入表示,再通过结合图扰动技术训练后的r-gcn获取作者最终嵌入表示,能够有效表示文献间的多重计量关系。采用本发明,可以进行通用、快捷且准确的中文作者姓名消歧操作,可以准确区分相同中文名字的不同作者。
技术特征:1.一种基于关系图卷积神经网络的中文作者姓名消歧方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于关系图卷积神经网络的中文作者姓名消歧方法,其特征在于,所述s2的根据预设的节点特征定义和节点关系定义,使用所述样本数据集构建样本作者图结构,包括:
3.根据权利要求2所述的基于关系图卷积神经网络的中文作者姓名消歧方法,其特征在于,所述预设的节点特征定义包括:论文名称、作者姓名、论文关键词、摘要以及第一机构;
4.根据权利要求3所述的基于关系图卷积神经网络的中文作者姓名消歧方法,其特征在于,所述预设的节点关系定义包括:作者高文献耦合关系、作者生僻字关系以及作者论文来源耦合关系;
5.根据权利要求1所述的基于关系图卷积神经网络的中文作者姓名消歧方法,其特征在于,所述初始关系图卷积神经网络模型为初始改进r-gcn模型;
6.根据权利要求5所述的基于关系图卷积神经网络的中文作者姓名消歧方法,其特征在于,所述改进r-gcn模型包括线性变换模块、消息传递模块、消息聚合模块、特征更新模块、层归一化模块、自环更新模块、dropout模块以及输出模块;
7.根据权利要求1所述的基于关系图卷积神经网络的中文作者姓名消歧方法,其特征在于,所述s8的将所述作者嵌入表示作为聚类的输入,确定作者聚类簇,包括:
8.一种基于关系图卷积神经网络的中文作者姓名消歧装置,所述基于关系图卷积神经网络的中文作者姓名消歧装置用于实现如权利要求1-7任一项所述基于关系图卷积神经网络的中文作者姓名消歧方法,其特征在于,所述装置包括:
9.一种基于关系图卷积神经网络的中文作者姓名消歧设备,其特征在于,所述基于关系图卷积神经网络的中文作者姓名消歧设备包括:
10.一种计算机可读取存储介质,其特征在于,所述计算机可读取存储介质中存储有程序代码,所述程序代码可被处理器调用执行如权利要求1至7任一项所述的方法。
技术总结本发明涉及姓名消歧技术领域,特别是指一种基于关系图卷积神经网络的中文作者姓名消歧方法及装置,方法包括:根据预设节点特征定义和节点关系定义,使用样本数据集构建样本作者图结构,输入初始关系图卷积神经网络模型,得到预测作者嵌入表示,根据聚类算法,得到预测作者聚类簇;根据预测作者聚类簇和作者真实标签,得到训练后的关系图卷积神经网络模型;获取待消歧数据,使用待消歧数据构建待消歧作者图结构;将待消歧作者图结构输入到训练后的关系图卷积神经网络模型,生成作者嵌入表示;将作者嵌入表示作为聚类的输入,确定作者聚类簇;根据作者聚类簇,确定作者识别结果。采用本发明,可以进行通用、快捷且准确的中文作者姓名消歧操作。技术研发人员:黄月,霍际同受保护的技术使用者:北京语言大学技术研发日:技术公布日:2024/8/1本文地址:https://www.jishuxx.com/zhuanli/20240802/259688.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表