一种非结构化数据存储方法及系统与流程
- 国知局
- 2024-08-05 11:50:07
本发明涉及非结构化数据存储,具体是一种非结构化数据存储系统及方法。
背景技术:
1、非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据,在现有技术背景下,非结构化数据一般指的是非结构化文本数据,也即,格式没有预先设置的文本数据,某一产品的评论信息就是最典型的非结构化文本数据。
2、现有的面向此类数据的存储方式是借助不限制大小的表格,按照评论信息的时间或是首词进行排序,并不会考虑评论信息的内在联系,在后续处理时,很难快速定位到相似的评论,往往需要再外接一个算法,进行分类,较为繁琐,如何提高非结构化文本数据在存储时的可阅读性,便于后续的分析处理过程是本发明想要解决的技术问题。
技术实现思路
1、本发明的目的在于提供一种非结构化数据存储方法及系统,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:
3、本发明的第一方面,提供一种非结构化数据存储方法,所述方法包括:
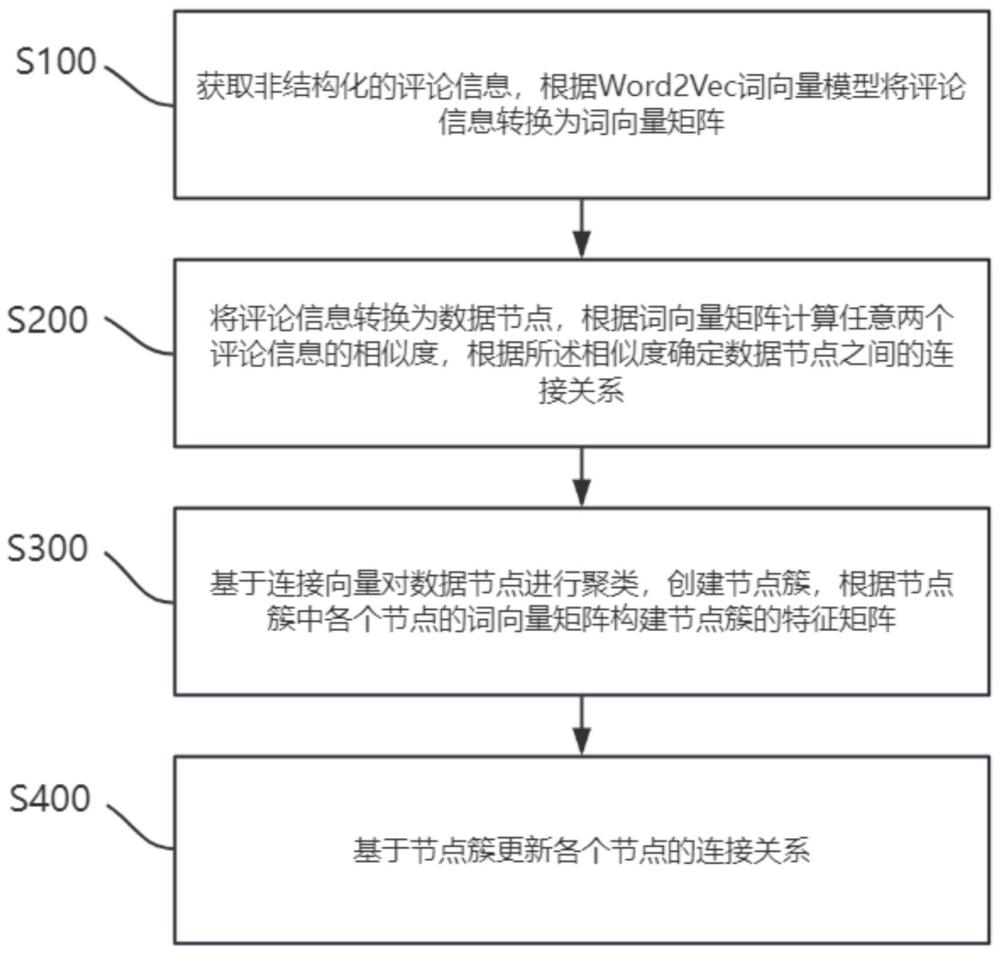
4、获取非结构化的评论信息,根据word2vec词向量模型将评论信息转换为词向量矩阵;
5、将评论信息转换为数据节点,根据词向量矩阵计算任意两个评论信息的相似度,根据所述相似度确定数据节点之间的连接关系;所述连接关系包括两个相互连接的数据节点的名称和连接向量;所述连接向量的模长为相似度,所述连接向量的方向为前一时刻的评论信息的数据节点指向后一时刻的评论信息的数据节点;
6、基于连接向量对数据节点进行聚类,创建节点簇,根据节点簇中各个节点的词向量矩阵构建节点簇的特征矩阵;
7、基于节点簇更新各个节点的连接关系。
8、进一步的,所述获取非结构化的评论信息,根据word2vec词向量模型将评论信息转换为词向量矩阵的步骤包括:
9、获取非结构化的评论信息,对评论信息进行词性分析,定位评论信息中的字词;
10、根据word2vec词向量模型将所述字词转换为词向量;
11、获取字词在评论信息中的顺序,根据字词在评论信息中的顺序排列词向量,得到词向量矩阵。
12、进一步的,所述将评论信息转换为数据节点,根据词向量矩阵计算任意两个评论信息的相似度,根据所述相似度确定数据节点之间的连接关系的步骤包括:
13、读取评论信息的词向量矩阵,计算词向量矩阵中任意两个词向量的向量距离;
14、计算每个词向量与其他词向量的平均向量距离,选取平均向量距离小于预设的距离阈值的词向量,读取词向量对应的字词,作为节点名称;
15、计算词向量矩阵的数据量,根据数据量确定节点尺寸,根据节点尺寸创建数据节点,将节点名称插入数据节点;
16、根据词向量矩阵计算任意两个评论信息的相似度,根据两个评论信息的时间先后确定方向,根据方向创建模长为相似度的连接向量;所述方向为前一时刻指向后一时刻;
17、基于连接向量连接两个评论信息对应的数据节点;
18、其中,所述向量距离的计算过程为:
19、;式中,为向量和向量的向量距离,为向量的第个参数,为向量的第个参数;为向量和向量的维度;
20、相似度的计算过程为:
21、;式中,为两个词向量矩阵的相似度,表示较小列数的词向量矩阵在较大列数的词向量矩阵的遍历起点列数,表示较小列数的词向量矩阵中的列数;是较小列数的词向量矩阵的总列数,是较大列数的词向量矩阵的总列数;为较小列数的词向量矩阵中的第个列向量,为较大列数的词向量矩阵中的第个列向量;为和的向量距离;为最小值选取函数。
22、进一步的,所述基于连接向量对数据节点进行聚类,创建节点簇,根据节点簇中各个节点的词向量矩阵构建节点簇的特征矩阵的步骤包括:
23、基于所述连接向量对数据节点进行谱聚类,得到节点簇;
24、根据节点簇中各数据节点的名称确定节点簇名称;
25、读取节点簇中各个数据节点的词向量矩阵,连接各个数据节点的词向量矩阵,作为节点簇的特征矩阵。
26、进一步的,所述基于节点簇更新各个节点的连接关系的步骤包括:
27、依次选取节点簇,遍历节点簇中的数据节点,读取数据节点的连接关系;
28、查询连接关系中另一数据节点的节点名称,判断其是否属于同一节点簇;
29、当所述另一数据节点的节点名称不属于同一节点簇时,查询另一数据节点所在的节点簇的节点簇名称;
30、将连接关系中另一数据节点的节点名称替换为节点簇名称;
31、基于连接向量生成与节点簇相连的上层向量。
32、进一步的,所述基于连接向量生成与节点簇相连的上层向量的步骤包括:
33、读取节点簇的特征矩阵;
34、读取数据节点对应的词向量矩阵,由词向量矩阵遍历所述特征矩阵,计算最大相似度;
35、保留连接向量的方向,将最大相似度作为模长,生成由数据节点至节点簇的向量,作为连接向量的上层向量;
36、其中,所述上层向量嵌套所述连接向量。
37、本发明技术方案还提供了一种非结构化数据存储系统,所述系统包括:
38、词向量转换模块,用于获取非结构化的评论信息,根据word2vec词向量模型将评论信息转换为词向量矩阵;
39、连接关系构建模块,用于将评论信息转换为数据节点,根据词向量矩阵计算任意两个评论信息的相似度,根据所述相似度确定数据节点之间的连接关系;所述连接关系包括两个相互连接的数据节点的名称和连接向量;所述连接向量的模长为相似度,所述连接向量的方向为前一时刻的评论信息的数据节点指向后一时刻的评论信息的数据节点;
40、数据节点聚类模块,用于基于连接向量对数据节点进行聚类,创建节点簇,根据节点簇中各个节点的词向量矩阵构建节点簇的特征矩阵;
41、连接关系更新模块,用于基于节点簇更新各个节点的连接关系。
42、进一步的,所述词向量转换模块包括:
43、字词定位单元,用于获取非结构化的评论信息,对评论信息进行词性分析,定位评论信息中的字词;
44、字词转换单元,用于根据word2vec词向量模型将所述字词转换为词向量;
45、词向量排序单元,用于获取字词在评论信息中的顺序,根据字词在评论信息中的顺序排列词向量,得到词向量矩阵。
46、进一步的,所述连接关系构建模块包括:
47、距离计算单元,用于读取评论信息的词向量矩阵,计算词向量矩阵中任意两个词向量的向量距离;
48、名称生成单元,用于计算每个词向量与其他词向量的平均向量距离,选取平均向量距离小于预设的距离阈值的词向量,读取词向量对应的字词,作为节点名称;
49、节点创建单元,用于计算词向量矩阵的数据量,根据数据量确定节点尺寸,根据节点尺寸创建数据节点,将节点名称插入数据节点;
50、向量生成单元,用于根据词向量矩阵计算任意两个评论信息的相似度,根据两个评论信息的时间先后确定方向,根据方向创建模长为相似度的连接向量;所述方向为前一时刻指向后一时刻;
51、连接执行单元,用于基于连接向量连接两个评论信息对应的数据节点;
52、其中,所述向量距离的计算过程为:
53、;式中,为向量和向量的向量距离,为向量的第个参数,为向量的第个参数;为向量a和向量b的维度;
54、相似度的计算过程为:
55、;式中,为两个词向量矩阵的相似度,表示较小列数的词向量矩阵在较大列数的词向量矩阵的遍历起点列数,表示较小列数的词向量矩阵中的列数;是较小列数的词向量矩阵的总列数,是较大列数的词向量矩阵的总列数;为较小列数的词向量矩阵中的第个列向量,为较大列数的词向量矩阵中的第个列向量;为和的向量距离;为最小值选取函数。
56、进一步的,所述数据节点聚类模块包括:
57、聚类执行单元,用于基于所述连接向量对数据节点进行谱聚类,得到节点簇;
58、名称统计单元,用于根据节点簇中各数据节点的名称确定节点簇名称;
59、特征抽取单元,用于读取节点簇中各个数据节点的词向量矩阵,连接各个数据节点的词向量矩阵,作为节点簇的特征矩阵。
60、与现有技术相比,本发明的有益效果是:本发明将评论信息转换为数据节点,基于图结构存储评论信息,在存储阶段,同步构建各个数据节点的连接关系,进而生成一种类似于知识图谱的存储架构,可阅读性极高,便于后续的分析处理过程。
本文地址:https://www.jishuxx.com/zhuanli/20240802/259676.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表