一种GQL语料生成模型训练方法、装置和存储介质与流程
- 国知局
- 2024-08-05 12:12:12
本发明涉及自然语言处理,尤其涉及一种gql语料生成模型训练方法、装置和存储介质。
背景技术:
1、随着大数据和人工智能技术的不断发展,得益于图查询语言gql(graph querylanguage)在图形数据库查询过程中对复杂关系的优异处理能力和高度的可扩展性,人们对gql语料的构建需求日益旺盛。目前,大多数gql语料都是通过人工设计和标注的方式获取的,由于掌握gql和图数据库原理专家的稀缺,以及gql表达能力的丰富,使得在构建过程中很难同时兼顾语料的质量及其多样性和规模性,导致当前针对gql的各种ai辅助技术无法被充分优化训练,使其在实际应用中的效果大打折扣,难以真正为用户提供有价值的辅助。
2、同时,在人工标注过程中,由于标注者疏忽所导致的错误和遗漏、由于标注者理解偏差所导致的标注差异、由于标注者对某些语法边界情况的了解缺乏所导致的测试用例遗漏,以及人工语料对某些隐式依赖的覆盖不全面,同样会造成语料质量不稳定,在后续训练和测试过程中影响gql相关系统的可靠性,使得当前的gql语料很难直接应用于实际的图数据库应用开发和优化中。
技术实现思路
1、本发明针对现有技术中的不足,公开了一种gql语料生成模型训练方法,包括如下步骤:
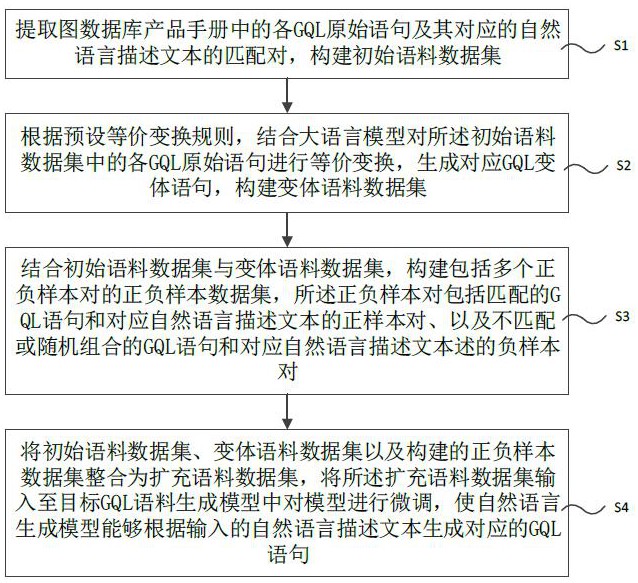
2、s1,提取图数据库产品手册中的各gql原始语句及其对应的自然语言描述文本的匹配对,构建初始语料数据集;
3、s2,根据预设等价变换规则,结合大语言模型对所述初始语料数据集中的各gql原始语句进行等价变换,生成对应gql变体语句,构建变体语料数据集;
4、s3,结合初始语料数据集与变体语料数据集,构建包括多个正负样本对的正负样本数据集,所述正负样本对包括匹配的gql语句和对应自然语言描述文本的正样本对、以及不匹配或随机组合的gql语句和对应自然语言描述文本的负样本对;
5、s4,将初始语料数据集、变体语料数据集以及构建的正负样本数据集整合为扩充语料数据集,将所述扩充语料数据集输入至目标gql语料生成模型中对模型进行微调,使目标gql语料生成模型能够根据输入的自然语言描述文本生成对应的gql语句。
6、优选的,所述等价变换规则包括但不限于连接条件重写规则、谓词重排序规则、同义词替换规则、变量重命名规则。
7、优选的,所述步骤s2包括:
8、s21,识别初始语料数据集中各gql原始语句的可变换单元,根据预设等价变换规则生成分别对应各gql原始语句的各等价变换语句组,所述可变换单元包括不限于谓词、where子句;
9、s22,将各gql原始语句和对应的等价变换语句组输入训练好的第一语言模型中结合预设打分函数对各等价变换语句进行打分,将最高打分结果所对应的等价变换语句作为对应gql变换语句。
10、优选的,所述目标gql语言模型的loss函数被配置为:
11、;
12、其中,为基于图同构的对比学习 loss:
13、;
14、为基于关系路径的对比学习 loss:
15、;
16、为基于语义解析的对比学习 loss:
17、;
18、为传统的监督学习loss函数;分别表示上述各loss函数的权重, 表示gql原始语句或 gql 变体语句, 表示正 样本 gql,表示负样本gql,d为正负样本数据集 ,、 分别表示正样本和负样本的自然语言描述文本parse表示语义解析模型, 为查询图的相似度度量函数,为关系路径相似度的度量函数, 表示在语义解析结果之上定义的相似度函数, 为基于查询图是否同构的权重函数 :
19、,表示查询图是否同构,和 为超参数且 > 。
20、优选的,所述方法还包括:
21、s51,提取所需目标领域图数据中的gql语句及其对应的自然语言描述文本的匹配对,构建新域语料数据集;
22、s52,对新域语料数据集进行预处理,对预处理后数据集中的gql语句进行等价变换及正负样本构建,生成新域扩充语料数据集;
23、s53,对新域扩充语料数据集进行质量评估,选取其中质量高于预设值的部分语料,与扩充语料数据集混合生成二次微调语料数据集,输入目标gql语料扩充模型中对模型进行微调。
24、本发明还公开了一种gql语料生成模型训练装置,包括数据提取模块、等价变换模块、样本生成模块和模型微调模块,其中数据提取模块,用于提取图数据库产品手册中的各gql原始语句及其对应的自然语言描述文本的匹配对,构建初始语料数据集;等价变换模块,用于根据预设等价变换规则,结合大语言模型对所述初始语料数据集中的各gql原始语句进行等价变换,生成对应gql变体语句,构建变体语料数据集;样本生成模块,用于结合初始语料数据集与变体语料数据集,构建包括多个正负样本对的正负样本数据集,所述正负样本对包括匹配的gql语句和对应自然语言描述文本的正样本对、以及不匹配或随机组合的gql语句和对应自然语言描述文本的负样本对;模型微调模块,用于将初始语料数据集、变体语料数据集以及构建的正负样本数据集整合为扩充语料数据集,将所述扩充语料数据集输入至目标gql语料生成模型中对模型进行微调,使目标gql语料生成模型能够根据输入的自然语言描述文本生成对应的gql语句。
25、优选的,所述等价变换规则包括但不限于连接条件重写规则、谓词重排序规则、同义词替换规则、变量重命名规则。
26、优选的,所述等价变换模块包括语句生成模块和语句筛选模块,其中语句生成模块,用于识别初始语料数据集中各gql原始语句的可变换单元,根据预设等价变换规则生成分别对应各gql原始语句的各等价变换语句组,所述可变换单元包括不限于谓词、where子句;语句筛选模块,用于将各gql原始语句和对应的等价变换语句组输入训练好的第一语言模型中结合预设打分函数对各等价变换语句进行打分,将最高打分结果所对应的等价变换语句作为对应gql变换语句。
27、本发明还公开了一种服务器,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述任一所述gql语料生成模型训练方法的步骤。
28、本发明还公开了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时如上述任一所述gql语料生成模型训练方法的步骤。
29、本发明公开的gql语料生成模型训练方法、装置和存储介质,在基于图数据产品用户手册初步构建高质量少样本语料集后,结合等价变换规则、大语言模型等生成gql变体语句以实现对gql语料中gql语句的自动扩充,增加语料丰富程度,同时生成正负样本对并与所生成的全部好的语料一起输入目标gql语料生成模型中对模型进行微调,使模型可根据输入的自然语言描述文本自动生成对应gql扩充语句,以在保证质量的前提下,实现少成本条件下gql语料的自动扩充,避免了人为标注过程中所存在的人为疏忽、遗漏、标注差异,降低了由于人工标注所花费的人力物力成本。
30、本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
本文地址:https://www.jishuxx.com/zhuanli/20240802/261520.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。