城市Mesh数据的半监督语义分割方法、装置和设备
- 国知局
- 2024-08-05 12:14:26
本技术涉及三维图像处理,特别是涉及一种城市mesh数据的半监督语义分割方法、装置和设备。
背景技术:
1、城市mesh语义分割是指对三维城市mesh数据进行语义分割,为每块三角面片提供类别信息,从而提升城市mesh中地理信息的细节表达。它在智慧城市、数字地球、工程监管、水利工程、虚拟现实等领域有着广泛的应用。
2、城市mesh是描述大规模户外环境的主流三维数据之一,能够真实反映大规模户外场景下的三维空间信息,例如建筑物、道路、水域等地物的分布。城市mesh本质上是带纹理的三维mesh数据,相较于点云,具有连续表面、强真实感以及轻量的特点;相较于一般的mesh,城市mesh用于描述户外场景下的真实环境,而mesh通常指小型的三维个体物体;相比正射影像,城市mesh包含空间侧面信息,能够描述户外场景中的三维空间内容。
3、随着深度学习在三维数据分析中取得的显著成功,城市mesh的语义分割蓬勃发展。这种分割主要采用两种方法:基于超表面方法和点云采样语义分割方法。基于超表面方法首先使用聚类算法对城市mesh进行过度分割,生成超表面,然后通过超表面分类完成语义分割。典型的超表面方法包括rf-mrf、sum和pssnet。rf-mrf在最后阶段使用马尔可夫随机场来平滑预测,而pssnet在过度分割阶段使用马尔可夫随机场来增强超表面的平滑度。此外,图神经网络在超表面分类阶段被用来学习超表面之间的关联。尽管这些方法有效,但超表面方法存在一个共同的限制:聚类算法(过度分割阶段)不可微分,阻碍了端到端训练。基于点云采样方法则有效地避开了这一限制。urban-meshcnn基于meshcnn,并结合广度优先搜索(bfs)技术对城市mesh进行语义分割。然而,庞大的城市mesh数据量使urban-meshcnn在计算上效率低下,因此不适用于大规模城市mesh应用。此外,它仅依赖于边信息来描述每个面,缺乏原始特征信息。为了解决这一问题,transformermesh利用transformer网络学习和处理实体之间的长距离依赖关系,以实现语义分割。grzeczkowicz提倡使用泊松圆盘采样(pds)算法对城市mesh进行随机而均匀的点云采样,然后使用kpconv算法进行点云语义分割,点云语义分割的结果随后被映射回城市mesh。
4、当前关于城市mesh语义分割的方法主要是基于全监督学习的,但是城市mesh标注耗时耗力;未充分利用所有未标记数据,并且伪标签中噪声对模型分割性能存在较大的不利影响。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种城市mesh数据的半监督语义分割方法、装置和设备。
2、一种城市mesh数据的半监督语义分割方法,该方法包括:
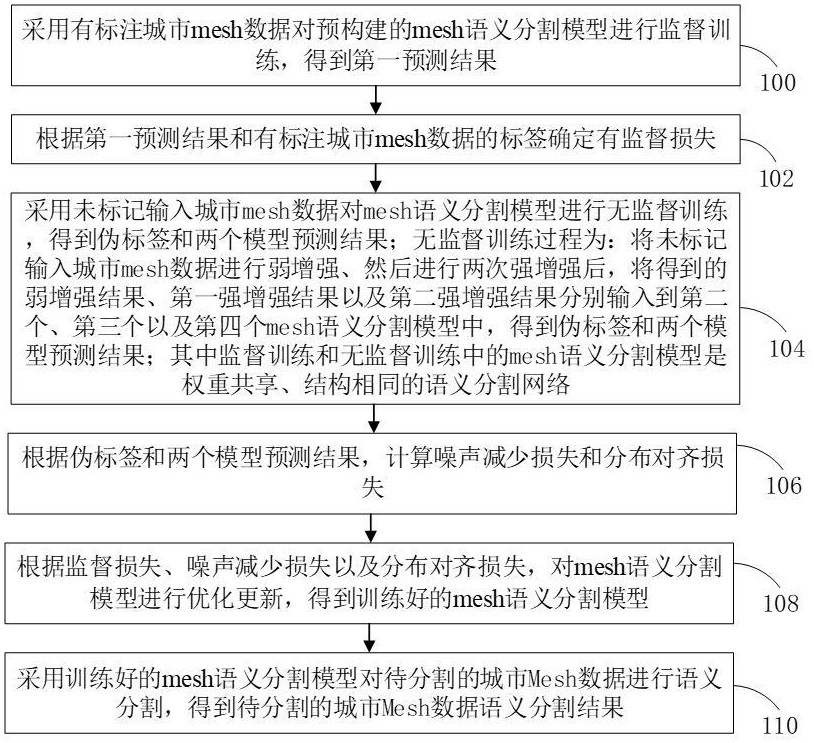
3、采用有标注城市mesh数据对预构建的mesh语义分割模型进行监督训练,得到第一预测结果。
4、根据第一预测结果和有标注城市mesh数据的标签确定有监督损失。
5、采用未标记输入城市mesh数据对mesh语义分割模型进行无监督训练,得到伪标签和两个模型预测结果;无监督训练过程为:将未标记输入城市mesh数据进行弱增强、然后进行两次强增强后,将得到的弱增强结果、第一强增强结果以及第二强增强结果分别输入到第二个、第三个以及第四个mesh语义分割模型中,得到伪标签和两个模型预测结果;其中监督训练和无监督训练中的mesh语义分割模型是权重共享、结构相同的语义分割网络。
6、根据伪标签和两个模型预测结果,计算噪声减少损失和分布对齐损失。
7、根据监督损失、噪声减少损失以及分布对齐损失,对mesh语义分割模型进行优化更新,得到训练好的mesh语义分割模型。
8、采用训练好的mesh语义分割模型对待分割的城市mesh数据进行语义分割,得到待分割的城市mesh数据语义分割结果。
9、在其中一个实施例中,采用有标注城市mesh数据对预构建的mesh语义分割模型进行监督训练,得到第一预测结果,包括:
10、对有标注城市mesh数据进行泊松盘采样,对采样结果进行弱增强。
11、将得到的弱增强结果输入到预构建的mesh语义分割模型中,得到第一预测结果。
12、在其中一个实施例中,根据第一预测结果和有标注城市mesh数据标签确定有监督损失为:
13、;
14、其中,为有监督损失,为类别数量,为符号函数,为观测样本属于类别的预测概率。
15、在其中一个实施例中,弱增强的方法为旋转或者平移操作。
16、在其中一个实施例中,强增强的方法为加入噪声或者颜色变化操作。
17、在其中一个实施例中,采用未标记输入城市mesh数据对mesh语义分割模型进行无监督训练,得到伪标签和两个模型预测结果,包括:
18、对未标记城市mesh数据进行泊松盘采样,对采样结果进行弱增强,得到第一弱增强结果。
19、将第一弱增强结果进行两次强增强,得到第一强增强结果和第二强增强结果。
20、将第一弱增强结果输入到第二个mesh语义分割模型中,将得到的预测结果作为伪标签。
21、将第一强增强结果输入到第三个mesh语义分割模型中,得到第一个模型预测结果。
22、将第二强增强结果输入到第四个mesh语义分割模型中,得到第二个模型预测结果。
23、在其中一个实施例中,根据伪标签和两个模型预测结果,计算噪声减少损失和分布对齐损失,包括:
24、根据伪标签,计算噪声减少损失为:
25、;
26、其中,为噪声减少损失,为伪标签的数量,为伪标签的第个样本。
27、根据伪标签和两个模型预测结果采用kl散度,计算分布对齐损失为:
28、;
29、其中,为分布对齐损失, kl(||)为kl散度,和分别为伪标签、第一个模型预测结果和第二个模型预测结果。
30、在其中一个实施例中,根据监督损失、噪声减少损失以及分布对齐损失,对mesh语义分割模型进行优化更新,得到训练好的mesh语义分割模型,包括:
31、根据监督损失、噪声减少损失以及分布对齐损失,确定模型总损失为:
32、;
33、其中,为模型总损失,为有监督损失,为分布对齐损失,为噪声减少损失。
34、根据模型总损失对mesh语义分割模型进行优化更新,得到训练好的mesh语义分割模型。
35、一种城市mesh数据的半监督语义分割装置,该装置包括:
36、监督训练模块,用于采用有标注城市mesh数据对预构建的mesh语义分割模型进行监督训练,得到第一预测结果;根据第一预测结果和有标注城市mesh数据的标签确定有监督损失。
37、无监督训练模块,用于采用未标记输入城市mesh数据对mesh语义分割模型进行无监督训练,得到伪标签和两个模型预测结果;无监督训练过程为:将未标记输入城市mesh数据进行弱增强、然后进行两次强增强后,将得到的弱增强结果、第一强增强结果以及第二强增强结果分别输入到第二个、第三个以及第四个mesh语义分割模型中,得到伪标签和两个模型预测结果;其中监督训练和无监督训练中的mesh语义分割模型是权重共享、结构相同的语义分割网络;根据伪标签和两个模型预测结果,计算噪声减少损失和分布对齐损失。
38、mesh语义分割模型更新模块,用于根据监督损失、噪声减少损失以及分布对齐损失,对mesh语义分割模型进行优化更新,得到训练好的mesh语义分割模型。
39、城市mesh数据语义分割模块,用于采用训练好的mesh语义分割模型对待分割的城市mesh数据进行语义分割,得到待分割的城市mesh数据语义分割结果。
40、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述城市mesh数据的半监督语义分割方法的步骤。
41、上述城市mesh数据的半监督语义分割方法、装置和设备,所述城市mesh数据的半监督语义分割方法的训练过程包括监督学习部分和无监督学习部分,在无监督学习部分引入了噪声减少损失、分布对齐损失和扩展扰动空间;噪声减少损失改善了伪标签中的噪声,从而提高了其准确性;分布对齐损失减少了模型预测与伪标签之间的差异,从而提高了模型的分割准确性;扩展扰动空间增强了模型的鲁棒性和整体性能。采用城市mesh数据的半监督语义分割方法对待分割的城市mesh数据进行语义分割,可以提升城市mesh数据的分割准确性。
本文地址:https://www.jishuxx.com/zhuanli/20240802/261734.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表