一种基于服务器超融合的数据写入管理方法、设备和介质与流程
- 国知局
- 2024-08-05 12:21:01
本发明涉及数据处理,具体涉及一种基于服务器超融合的数据写入管理方法、设备和介质。
背景技术:
1、在服务器超融合过程中,通常需要将来自不同数据源的数据汇集到一个中央数据储存库中,以便能够处理和分析数据集,但是在数据写入过程中,服务器在执行数据写入时,当数据量大时,无法进行存放,因此本方案为了进行数据的正常存放操作,当服务器写入数据超过区域阈值时,需要进行区域的切分,但是在切分后,数据写入每个分区时,其数据的迁移是随机的,只有在遍历指定的区域服务器中的区域时才停止,这个过程会耗费很长时间,并且在服务器超融合过程中,需要满足有效扩展资源、动态重新分配存储以及适应不断变化的数据处理需求的能力;
2、而在在多节点的网络环境中,由于数据的复杂程度以及数据量较大,在数据到达服务器后,由于各个分区区域的性能和处理能力的差异,其写入是存在随机性的,往往会出现在某一时刻有些分区区域的访问频率较高,导致该分区的负载负荷较高,而又有些区域的访问频率较低,负载较轻甚至空闲,浪费存储空间,并且在分区后导致负载不均匀,造成数据写入的瘫痪甚至导致写入数据不可用。
技术实现思路
1、本发明所要解决的技术问题是当数据量大时,无法进行数据的正常存储,且在分区后数据存放不均衡,目的在于提供一种基于服务器超融合的数据写入管理方法、设备和介质,通过在服务器中创建一个存放区域,将插入数据写入存放区域中;当插入数据的写入量超过存放区域容纳量时,存放区域进行自动分割,保证数据的正常写入进程,获取区域服务器容量和区域服务器比例,根据数据的唯一标识符生成行键,对行键进行散列化处理得到分区,通过散列化处理通过将数据转换为固定长度的散列值可以增强数据节点的均匀性和安全性,有助于优化数据在存储和检索过程中的性能,在得到分区后,获取每个分区区域空间负载信息和每个分区数据访问负载信息,对数据进行负载均衡计算,通过负载均衡实现资源均匀分布,提升分布式数据库集群的整体性能。
2、本发明通过下述技术方案实现:
3、本发明第一方面提供一种基于服务器超融合的数据写入管理方法,包括以下具体步骤:
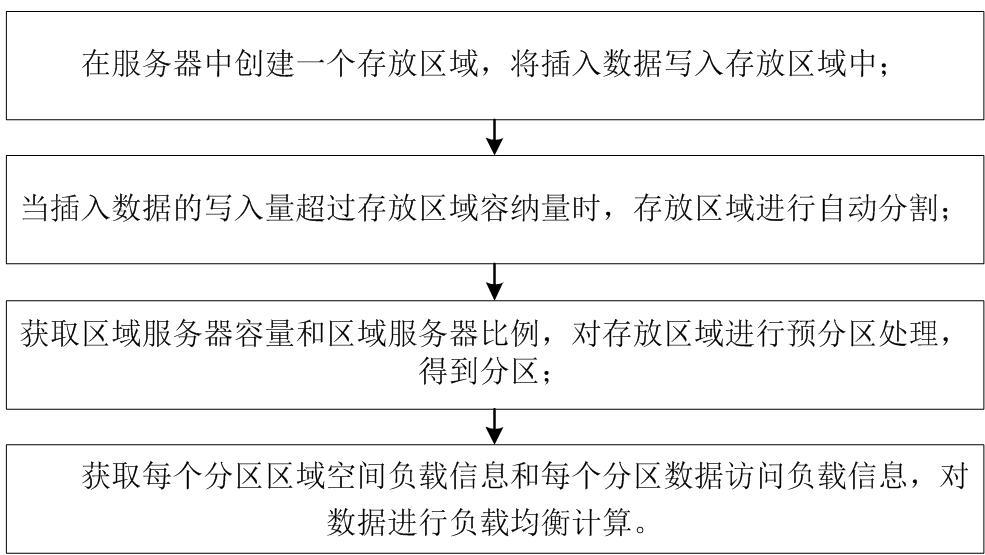
4、在服务器中创建一个存放区域,将插入数据写入存放区域中;
5、当插入数据的写入量超过存放区域容纳量时,存放区域进行自动分割;
6、获取区域服务器容量和区域服务器比例,对存放区域进行预分区处理,获取区域服务器容量和区域服务器比例,生成多个预分区;
7、采用虚拟节点映射提取每个分区的唯一标识符,根据数据的唯一标识符生成行键;
8、对行键进行散列化处理,得到可以均等写入数据的多个分区;
9、获取每个分区区域空间负载信息和每个分区数据访问负载信息,对数据进行负载均衡计算。
10、本发明通过在服务器中创建一个存放区域,将插入数据写入存放区域中;当插入数据的写入量超过存放区域容纳量时,存放区域进行自动分割,保证数据的正常写入进程,获取区域服务器容量和区域服务器比例,对存放区域进行预分区处理,根据数据的唯一标识符生成行键,对行键进行散列化处理得到分区,通过散列化处理通过将数据转换为固定长度的散列值可以增强数据节点的均匀性和安全性,有助于优化数据在存储和检索过程中的性能,并在得到分区后,获取每个分区区域空间负载信息和每个分区数据访问负载信息,对数据进行负载均衡计算,通过负载均衡实现资源均匀分布,提升分布式数据库集群的整体性能。通过处理后写入数据可以均等的名字预分区区域,在各个区域进行数据均匀存储,提高数据写入和读取效率,实现集群内区域级别的负载均衡。
11、进一步的,所述预分区处理的步骤包括:
12、获取区域服务器容量和区域服务器比例,生成多个预分区;
13、采用虚拟节点映射提取每个分区的唯一标识符,根据数据的唯一标识符生成行键;
14、对行键进行散列化处理,得到可以均等写入数据的多个分区。
15、进一步的,所述标识符的生成步骤包括:
16、获取数据集中每个序列的字符框的真实标签;
17、获取字符框线段和字符框的标注点数,通过扩张和收缩的方式生成标识符。
18、进一步的,所述通过扩张和收缩的方式生成标识符的具体步骤包括:
19、将字符框的真实标签向内收缩得到收缩标签;
20、将字符框的真实标签向外扩张得到扩张标签;
21、根据收缩标签和扩张标签分别得到收缩和扩张的偏移量;
22、对收缩和扩张的偏移量进行归一化处理,输出标识符。
23、进一步的,所述根据收缩标签和扩张标签分别得到收缩和扩张的偏移量的具体步骤包括:
24、使用固定阈值对收缩标签和扩张标签进行二值化处理,获得检测到的字符框。
25、获取字符框的最小内接矩形,最后对最小内接矩形进行扩张收缩,得到最终字符框的边界线,根据最终字符框的面积、周长和膨胀因子确定最终偏移量。
26、进一步的,所述根据数据的唯一标识符生成行键的具体步骤包括:
27、获取预分区容量和预分区个数,通过预分区个数确定虚拟节点的数量;
28、获取写入数据的主键,得到写入数据起始键和通用唯一识别码;
29、将写入数据起始键和通用唯一识别码合并生成行键。
30、进一步的,所述对行键进行散列化处理具体包括:
31、构建散列函数,通过散列函数将行键的值进行映射,得到散列值;
32、根据散列值对节点数量取模;
33、根据散列值将数据分布到不同的存储节点上。
34、进一步的,所述对数据进行负载均衡计算的具体步骤包括:
35、获取每个分区区域空间负载信息和每个分区数据访问负载信息,得到每个分区的数据访问阈值;
36、根据分区的数据访问阈值,筛选出每个分区的负载超载量和饥饿节点;
37、根据每个分区的负载超载量和饥饿节点计算每个负载成本值,基于负载成本值进行负载均衡调整。
38、进一步的,所述计算每个负载成本值的具体步骤包括:
39、将服务器中的最大负载区域和最小负载区域进行交换,计算新的成本值;
40、如果计算出的成本值小于原始值,则使用新的成本值;
41、否则,对负载区域交换进行迭代操作,并计算新的成本值,在迭代阈值内选择最优成本值,根据最优成本值进行负载均衡调整。
42、本发明第二方面提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现一种基于服务器超融合的数据写入管理方法。
43、本发明第三方面提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现一种基于服务器超融合的数据写入管理方法。
44、本发明与现有技术相比,具有如下的优点和有益效果:
45、本发明通过在服务器中创建一个存放区域,将插入数据写入存放区域中;当插入数据的写入量超过存放区域容纳量时,存放区域进行自动分割,保证数据的正常写入进程,获取区域服务器容量和区域服务器比例,对存放区域进行预分区处理,根据数据的唯一标识符生成行键,对行键进行散列化处理得到分区,通过散列化处理通过将数据转换为固定长度的散列值可以增强数据节点的均匀性和安全性,有助于优化数据在存储和检索过程中的性能,并在得到分区后,获取每个分区区域空间负载信息和每个分区数据访问负载信息,对数据进行负载均衡计算,通过负载均衡实现资源均匀分布,提升分布式数据库集群的整体性能。通过处理后写入数据可以均等的名字预分区区域,在各个区域进行数据均匀存储,提高数据写入和读取效率,实现集群内区域级别的负载均衡。
本文地址:https://www.jishuxx.com/zhuanli/20240802/262320.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。