场景声纹模型优化方法、装置、设备、介质和程序产品与流程
- 国知局
- 2024-08-08 17:02:48
本技术涉及人工智能,特别是涉及一种场景声纹模型优化方法、装置、计算机设备、计算机可读存储介质和计算机程序产品。
背景技术:
1、随着人工智能技术的发展,出现了声纹识别技术,这个技术正被广泛应用在各种加密或者解密场景中。主流的声纹识别模型一般采用resnet等深度神经网络,利用大量带有说话人标签的语料进行学习,通过不断训练使得模型可以准确提取对应说话人的声学或语言特征,从而完成说话人辨认、说话人确认、说话人日志等下游任务。
2、目前,在声纹识别任务中,对于特定场景的模型优化主要有两种方式:第一种是直接将场景数据与基础数据混合,重新对整个模型进行训练。第二种是对基础模型进行微调。然而,第一种方式耗时长,会浪费大量计算资源,且对场景数据识别的优化效果非常有限。第二种方式虽然一定程度上缩短了模型训练的时间,但是由于参与微调的只有场景数据,且相较于基础数据,场景数据的数据量较少。这会导致训练的模型在被应用于真实场景(尤其是与训练数据存在较大差异的场景)时,会出现识别效果不佳,鲁棒性低的问题。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种能够显著节约模型训练时长,在特定场景上具有很好的识别效果,且保证鲁棒性和泛化能力的场景声纹模型优化方法、装置、计算机设备、计算机可读存储介质和计算机程序产品。
2、第一方面,本技术提供了一种场景声纹模型优化方法,包括:
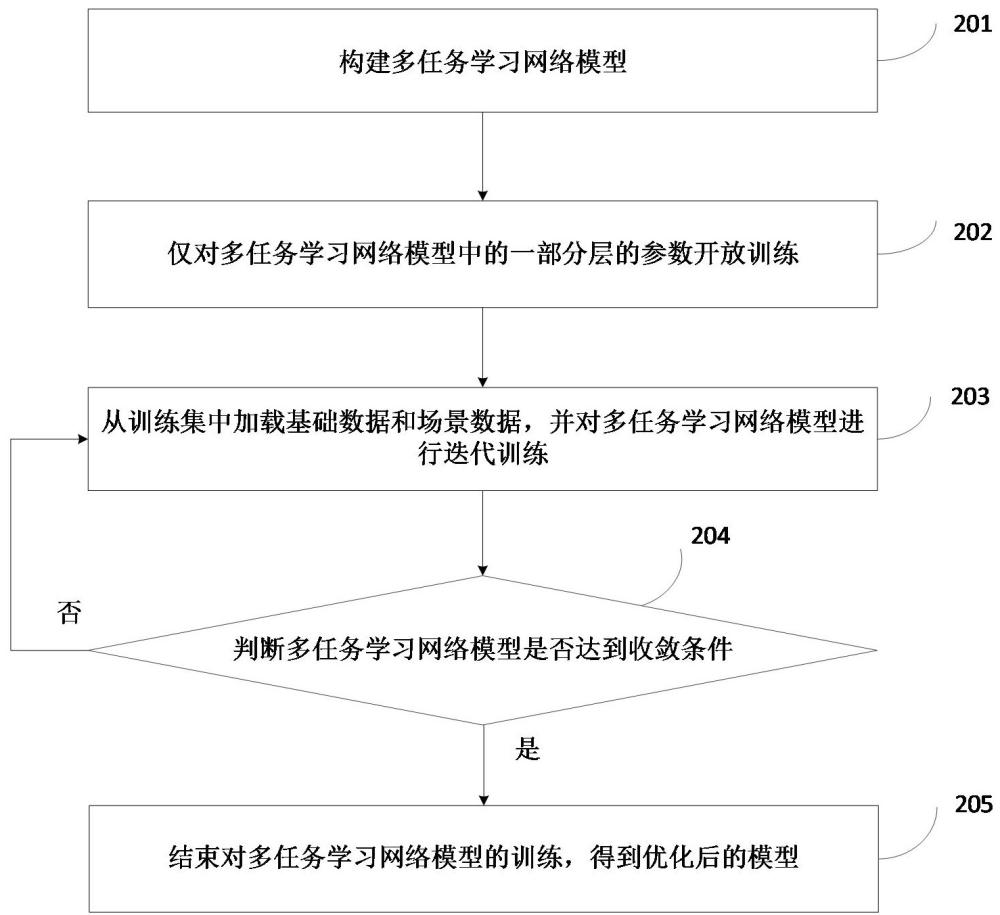
3、构建多任务学习网络模型,其中,所述多任务学习网络模型包括:基础分类模型、第一输出层,第二输出层;所述基础分类模型用于对输入的基础数据和场景数据进行分类处理,所述第一输出层为基础分支,用于输出基础数据对应的类别;所述第二输出层为场景分支,用于输出场景数据对应的类别;
4、仅对所述多任务学习网络模型中的一部分层的参数开放训练;
5、从训练集中加载基础数据和场景数据,并对所述多任务学习网络模型进行迭代训练,其中,在每一轮迭代中,基础数据和场景数据分别参与训练;
6、判断所述多任务学习网络模型是否达到收敛条件,若是,则结束对所述多任务学习网络模型的训练,得到优化后的模型。
7、在其中一个实施例中,所述构建多任务学习网络模型,包括:
8、构建基础分类模型,所述基础分类模型包括:残差神经网络resnet,深度卷积神经网络vgg中的任一种;
9、在所述基础分类模型上添加第一输出层和第二输出层,并随机初始化所述第一输出层和第二输出层对应的参数,其中,所述第一输出层、第二输出层包括:softmax,largemargin softmax中的任一种。
10、在其中一个实施例中,所述仅对所述多任务学习网络模型中的一部分层的参数开放训练,包括:
11、对所述多任务学习网络模型的前n层参数进行固定,仅开放训练后m层的参数,其中,n、m为大于0的自然数,且n与m之和小于或等于所述多任务学习网络模型的总层数。
12、在其中一个实施例中,在从训练集中加载基础数据和场景数据之前,所述方法还包括:
13、对包含说话人标签和场景信息的数据进行预处理,得到预设长度的场景数据;
14、对所述场景数据进行扩充,使得所述场景数据达到与所述基础数据一样的数量级,其中,扩充的方式包括:复制。
15、在其中一个实施例中,对所述多任务学习网络模型进行迭代训练,包括:
16、采用基础数据和场景数据交替训练的方式,对所述多任务学习网络进行迭代训练,其中,
17、在每一轮迭代中,所述基础数据参与一次基础分类模型和第一输出层的迭代与反向传播,且所述场景数据参与一次基础分类模型和第二输出层的迭代与反向传播。
18、在其中一个实施例中,所述方法还包括:
19、构建测试集;
20、通过所述测试集对所述优化后的模型进行验证,若验证通过,则得到目标模型;
21、若验证不通过,则调整所述优化后的模型中的部分参数,重新进行训练;
22、通过所述目标模型对语料数据进行识别,得到对应的识别结果。
23、第二方面,本技术还提供了一种场景声纹模型优化装置,包括:
24、模型构建模块,用于构建多任务学习网络模型,其中,所述多任务学习网络模型包括:基础分类模型、第一输出层,第二输出层;所述基础分类模型用于对输入的基础数据和场景数据进行分类处理,所述第一输出层为基础分支,用于输出基础数据对应的类别;所述第二输出层为场景分支,用于输出场景数据对应的类别;
25、参数设置模块,用于仅对所述多任务学习网络模型中的一部分层的参数开放训练;
26、模型训练模块,用于从训练集中加载基础数据和场景数据,并对所述多任务学习网络模型进行迭代训练,其中,在每一轮迭代中,基础数据和场景数据分别参与训练;
27、判断所述多任务学习网络模型是否达到收敛条件,若是,则结束对所述多任务学习网络模型的训练,得到优化后的模型。
28、第三方面,本技术还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
29、构建多任务学习网络模型,其中,所述多任务学习网络模型包括:基础分类模型、第一输出层,第二输出层;所述基础分类模型用于对输入的基础数据和场景数据进行分类处理,所述第一输出层为基础分支,用于输出基础数据对应的类别;所述第二输出层为场景分支,用于输出场景数据对应的类别;
30、仅对所述多任务学习网络模型中的一部分层的参数开放训练;
31、从训练集中加载基础数据和场景数据,并对所述多任务学习网络模型进行迭代训练,其中,在每一轮迭代中,基础数据和场景数据分别参与训练;
32、判断所述多任务学习网络模型是否达到收敛条件,若是,则结束对所述多任务学习网络模型的训练,得到优化后的模型。
33、第四方面,本技术还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
34、构建多任务学习网络模型,其中,所述多任务学习网络模型包括:基础分类模型、第一输出层,第二输出层;所述基础分类模型用于对输入的基础数据和场景数据进行分类处理,所述第一输出层为基础分支,用于输出基础数据对应的类别;所述第二输出层为场景分支,用于输出场景数据对应的类别;
35、仅对所述多任务学习网络模型中的一部分层的参数开放训练;
36、从训练集中加载基础数据和场景数据,并对所述多任务学习网络模型进行迭代训练,其中,在每一轮迭代中,基础数据和场景数据分别参与训练;
37、判断所述多任务学习网络模型是否达到收敛条件,若是,则结束对所述多任务学习网络模型的训练,得到优化后的模型。
38、第五方面,本技术还提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现以下步骤:
39、构建多任务学习网络模型,其中,所述多任务学习网络模型包括:基础分类模型、第一输出层,第二输出层;所述基础分类模型用于对输入的基础数据和场景数据进行分类处理,所述第一输出层为基础分支,用于输出基础数据对应的类别;所述第二输出层为场景分支,用于输出场景数据对应的类别;
40、仅对所述多任务学习网络模型中的一部分层的参数开放训练;
41、从训练集中加载基础数据和场景数据,并对所述多任务学习网络模型进行迭代训练,其中,在每一轮迭代中,基础数据和场景数据分别参与训练;
42、判断所述多任务学习网络模型是否达到收敛条件,若是,则结束对所述多任务学习网络模型的训练,得到优化后的模型。
43、上述场景声纹模型优化方法、装置、计算机设备、计算机可读存储介质和计算机程序产品,通过构建多任务学习网络模型,其中,所述多任务学习网络模型包括:基础分类模型、第一输出层,第二输出层;所述基础分类模型用于对输入的基础数据和场景数据进行分类处理,所述第一输出层为基础分支,用于输出基础数据对应的类别;所述第二输出层为场景分支,用于输出场景数据对应的类别;从而可以在一个模型中分别完成对基础数据和场景数据的单独训练。通过仅对所述多任务学习网络模型中的一部分层的参数开放训练;从而可以避免训练过程中模型的参数波动过大,提升模型的稳定性,缩短模型训练周期。通过从训练集中加载基础数据和场景数据,并对所述多任务学习网络模型进行迭代训练,其中,在每一轮迭代中,基础数据和场景数据分别参与训练;从而可以使得模型的迭代次数大大降低,并能够在特定场景上具备很好的识别效果,显著节约模型训练时长。通过判断所述多任务学习网络模型是否达到收敛条件,若是,则结束对所述多任务学习网络模型的训练,得到优化后的模型。从而可以保证模型的鲁棒性和泛化能力。
本文地址:https://www.jishuxx.com/zhuanli/20240808/272024.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表