一种基于时序融合多视角的三维占用网格预测方法及系统与流程
- 国知局
- 2024-08-19 14:24:43
本发明属于自动驾驶控制,具体涉及一种基于时序融合多视角的三维占用网格预测方法及系统。
背景技术:
1、自动驾驶汽车代表了技术创新的前沿,具有独立导航和感知复杂环境的能力。这种自主性的一个重要方面在于获得对周围空间的准确和全面的了解,包括行人、车辆、道路、交通标志和交通信号灯。感知算法在使自动驾驶车辆有效解释和理解周围环境方面发挥着关键作用。高效感知的重要性在于它对于确保自动驾驶的安全性、可靠性和效率。这涉及对物体、障碍物和环境线索的精确检测、识别和预测。这些算法可以分为三个主要组:图像空间中的2d对象检测、鸟瞰图(bev)特征空间中的三维感知和3d占用网格预测。
2、随着技术的不断进步,3d场景的理解由于能够提供更精细的空间物体表示,正在逐步取代传统的2d检测,并成为基于视觉的自动驾驶感知的一个重要方面。与bev表示相反,3d占用网格表示捕获周围场景的3d几何形状,是自动驾驶系统中的基本过程。这种方法有效地解决了感知任务中固有的挑战,包括长尾问题,如截断的目标、不规则形状的物体,以及缺乏清晰语义标签的问题(例如拖车、树木、碎片和石头),这些挑战是以往方法无法充分解决的3d检测问题。通过占用的网格直接对环境进行建模,它不仅解决了这些问题,而且还提供了更精确和语义丰富的表示。同时提供了更为全面的高度和深度信息,使其成为自动驾驶领域的关键感知任务。
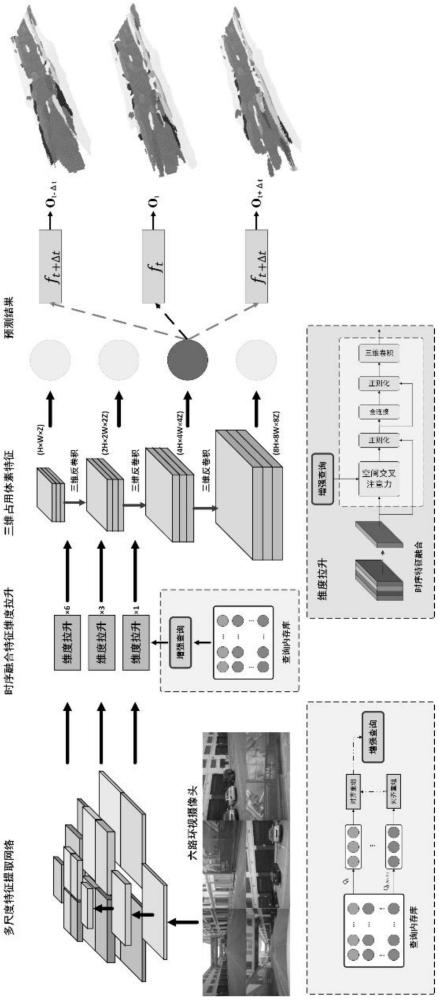
3、由于现实世界中时间固有的连续性,时序信息对感知数据的全面性十分重要。提高了物体检测的准确性和鲁棒性。值得注意的是,时序信息在减轻对象检测中的遮挡问题、提供对对象的运动状态和速度的洞察以及提供有关目标的关键连续性和一致性信息方面发挥着关键作用。因此,时序信息的有效整合是自动驾驶感知的关键挑战。
4、现有的3d占用网络采用六个环视视觉传感器作为输入,生成3d占用体素,随后对这些体素进行分类以进行三维语义分割。然而,这些算法普遍存在的局限性是它们倾向于逐帧进行单独预测,而忽略了时序信息的融合。这种缺失导致输出视频的特点是帧之间的碎片化和不平滑的过渡。尽管时序融合在bev表示中已被证明是成功的,但在bevformer中使用时序自注意力(tsa)引起了人们对潜在的长期时序信息丢失的担忧。这对于解决长期时间依赖性并确保预测随时间的一致性尤其重要。
技术实现思路
1、针对现有技术的不足,本发明提供一种基于时序融合多视角的三维占用网格预测方法及系统,解决了多摄像机3d占用预测不稳定的缺陷。
2、为实现上述目的,本发明提供了如下方案:
3、一种基于时序融合多视角的三维占用网格预测方法,包括以下步骤:
4、采集并预处理车辆自动驾驶时周围环境的多视角图像;
5、基于预处理后的所述多视角图像,构建基于时序融合多视角的三维占用网格模型;
6、基于所述三维占用网格模型对车辆自动驾驶时周围环境进行三维占用网格预测,获得所述多视角图像预设帧的三维占用网格预测结果。
7、优选的,所述三维占用网格模型包括特征提取模块、查询内存库、对齐重组模块以及体素特征获取模块;
8、基于所述特征提取模块,获得3d体积特征;
9、基于所述查询内存库,获得所述3d体积特征的查询;
10、基于所述对齐重组模块,对所述3d体积特征以及所述查询进行聚合,获得当前增强查询;
11、基于所述体素特征获取模块,对所述当前增强查询进行3d反卷积,获得车辆自动驾驶时周围环境的三维占用体素特征,完成所述三维占用网格模型的构建。
12、优选的,基于所述特征提取模块,获得3d体积特征的方法为:
13、基于多尺度特征提取网络对预处理后的所述多视角图像进行特征提取,获得多尺度特征;
14、采用transformer架构,构建具有时空交叉注意力的时序融合特征维度拉升模块,对所述多尺度体积特征进行维度拉升,完成所述特征提取模块的构建,获得3d体积特征;所述3d体积特征包括当前特征和先前特征。
15、优选的,基于所述查询内存库,获得所述3d体积特征的查询的方法为:
16、构建大小为n×s的查询内存库,基于所述查询内存库,获得所述3d体积特征的查询;其中,n和s分别表示查询的数量和每个查询的大小;所述查询包括当前查询和先前增强查询;所述查询内存库,遵循先进先出原则,指定用于存储从当前帧生成的查询。
17、优选的,所述对齐重组模块包括对齐、查询和聚合三个步骤,基于所述对齐重组模块,获得当前增强查询的方法为:
18、建立预设时间的自车外参矩阵,并基于所述自车外参矩阵获得变换矩阵;
19、基于所述变换矩阵,将所述先前特征从世界坐标转换为当前自我坐标,获得对齐的先前特征;其中,给定时间t–1时的自车外参矩阵和先前特征从世界坐标系到当前自车坐标系的变换执行如下:
20、
21、
22、其中和表示变换矩阵,是对齐的先前特征ft-δt;
23、基于所述先前增强查询和对齐的先前特征,通过可变形注意函数执行变形注意,获得对齐的先前增强查询;
24、利用层归一化和前馈网络,将对齐的先前增强查询和所述当前查询进行聚合,获得所述当前增强查询。
25、本发明还提供一种基于时序融合多视角的三维占用网格预测系统,用于应用所述的三维占用网格预测方法,包括:
26、图像采集模块,用于采集并预处理车辆自动驾驶时周围环境的多视角图像;
27、模型构建模块,用于基于预处理后的所述多视角图像,构建基于时序融合多视角的三维占用网格模型;
28、预测模块,用于基于所述三维占用网格模型对车辆自动驾驶时周围环境进行三维占用网格预测,获得所述多视角图像预设帧的三维占用网格预测结果。
29、优选的,所述三维占用网格模型包括特征提取模块、查询内存库、对齐重组模块以及体素特征获取模块;所述模型构建模块包括:
30、特征提取单元,用于基于所述特征提取模块,获得3d体积特征;
31、查询单元,用于基于所述查询内存库,获得所述3d体积特征的查询;
32、对齐重组单元,用于基于所述对齐重组模块,对所述3d体积特征以及所述查询进行聚合,获得当前增强查询;
33、模型构建单元,用于基于所述体素特征获取模块,对所述当前增强查询进行3d反卷积,获得车辆自动驾驶时周围环境的三维占用体素特征,完成所述三维占用网格模型的构建。
34、优选的,所述特征提取单元包括:
35、多尺度特征获取子单元,用于基于多尺度特征提取网络对预处理后的所述多视角图像进行特征提取,获得多尺度特征;
36、升维子单元,用于采用transformer架构,构建具有时空交叉注意力的时序融合特征维度拉升模块,对所述多尺度体积特征进行维度拉升,完成所述特征提取模块的构建,获得3d体积特征;所述3d体积特征包括当前特征和先前特征。
37、优选的,所述查询单元中,构建大小为n×s的查询内存库,基于所述查询内存库,获得所述3d体积特征的查询;其中,n和s分别表示查询的数量和每个查询的大小;所述查询包括当前查询和先前增强查询;所述查询内存库,遵循先进先出原则,指定用于存储从当前帧生成的查询。
38、优选的,所述对齐重组单元包括:
39、对齐子单元,用于建立预设时间的自车外参矩阵,并基于所述自车外参矩阵获得变换矩阵;基于所述变换矩阵,将所述先前特征从世界坐标转换为当前自我坐标,获得对齐的先前特征;
40、查询子单元,用于基于所述先前增强查询和对齐的先前特征,通过可变形注意函数执行变形注意,获得对齐的先前增强查询;
41、聚合子单元,用于利用层归一化和前馈网络,将对齐的先前增强查询和所述当前查询进行聚合,获得所述当前增强查询。
42、与现有技术相比,本发明的有益效果为:本发明的方法采用多尺度检测流程,有助于感知不同尺度的对象,从而增强语义粒度由此产生的占用网格。与流行的占用网络不同,本发明提出查询内存库和对齐重组模块(arm),该模块聚合来自车辆在道路场景中运动的长期信息。使用训练最佳模型对nuscenes公开数据集中的测试集进行测试,精度与目前算法相比得到了提高,尤其是对于复杂场景中无人驾驶的感知能力更加优异。本发明通过分析捕捉道路上车辆运动的一系列连续帧,即使呈现的是平面二维图像,也可以推断出车辆的周围环境。此外,考虑到帧之间观察到的连续性,当车辆经历自我运动时,可以推断出周围时刻物体的相对运动。
本文地址:https://www.jishuxx.com/zhuanli/20240819/275109.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表