一种跨数据中心分布式机器学习通信方法及系统
- 国知局
- 2024-08-22 14:22:17
本发明属于通信,具体涉及一种跨数据中心分布式机器学习通信方法及系统。
背景技术:
1、随着人工智能的迅猛发展,机器学习尤其是深度学习在图像识别、语音处理、自然语言理解等领域取得了突破性进展。然而,训练大型深度学习模型往往需要海量的数据样本和计算资源。为了加快模型训练过程,分布式机器学习应运而生,其通过将训练任务拆分到多个训练节点并行执行,再通过ps(parameter server,参数服务器)架构实现训练节点间的参数同步,从而大幅提升训练效率。
2、然而,在分布式训练过程中,ps架构面临严重的长尾时延问题,制约了系统的可扩展性。其根本原因在于,随着训练节点数量增加,大量训练节点在每轮迭代结束时几乎同时与ps进行通信,产生many-to-one(多对一)的"incast"流量模式,导致网络带宽争用激烈、丢包率急剧上升。部分数据流不得不频繁重传,显著拉长了尾部流的完成时间。且由于采用了批量同步并行(bulk synchronous parallel,bsp)的同步模型,所有训练节点必须等待最慢的训练节点完成参数更新后才能进入下一轮迭代。少数延迟严重的节点会使整个训练效率大打折扣。
3、此外,在跨数据中心训练场景下,训练节点与ps之间的通信需经由广域网或无线链路,物理链路故障、信号衰落等因素时有发生,造成显著的非拥塞丢包,进一步加剧了长尾时延问题。网络已成为制约分布式机器学习可扩展性的关键瓶颈。
4、针对上述问题,现有的解决方案主要从两方面着手:一是优化通信拓扑,如ring-allreduce(一种以环状拓扑为基础的通信系统)、二层参数服务器层次化聚合参数等;二是压缩通信量,如参数量化、剪枝、梯度稀疏化等。但这些方法均未从根本上解决网络瓶颈问题。传统的传输控制协议如tcp,虽然能保证数据的可靠交付,但无法容忍丢包,面对incast场景下的严重丢包,频繁重传反而恶化了长尾时延。udp(user datagram protocol,用户数据报协议)虽然对丢包容忍,但过多的丢包又会影响模型训练的收敛性。
5、因此,如何提供一种可靠且高效的跨数据中心分布式机器学习通信方法,成为了一个亟待解决的技术问题。
技术实现思路
1、为了解决现有技术中所存在的上述问题,本发明提供了一种跨数据中心分布式机器学习通信方法及系统。
2、本发明要解决的技术问题通过以下技术方案实现:
3、第一方面,本发明提供了一种跨数据中心分布式机器学习通信方法,所述方法包括:
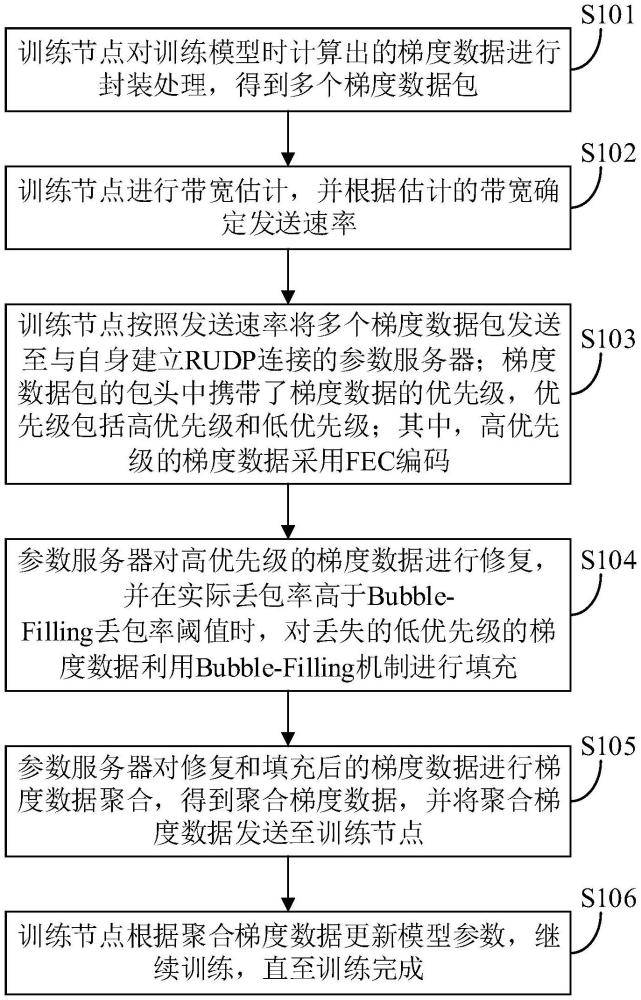
4、训练节点对训练模型时计算出的梯度数据进行封装处理,得到多个梯度数据包;
5、训练节点进行带宽估计,并根据估计的带宽确定发送速率;
6、训练节点按照所述发送速率将所述多个梯度数据包发送至与自身建立rudp连接的参数服务器;所述梯度数据包的包头中携带了梯度数据的优先级,所述优先级包括高优先级和低优先级;其中,高优先级的梯度数据采用fec编码;
7、参数服务器对高优先级的梯度数据进行修复,并在实际丢包率高于bubble-filling丢包率阈值时,对丢失的低优先级的梯度数据利用bubble-filling机制进行填充;
8、参数服务器对修复和填充后的梯度数据进行梯度数据聚合,得到聚合梯度数据,并将所述聚合梯度数据发送至训练节点;
9、训练节点根据所述聚合梯度数据更新模型参数,继续训练,直至训练完成。
10、可选的,训练节点进行带宽估计,包括:
11、在每个往返时延内,通过调整拥塞窗口大小,触发网络队列的积累和耗尽来测量出当前带宽。
12、可选的,训练节点根据估计的带宽确定发送速率的方式,包括:
13、在每个数据包传输窗口期的初始时刻,根据估计的带宽计算初始的发送速率;
14、在每个数据包传输窗口期内,监测梯度数据包的丢失情况;当连续多个往返时延内都没有丢包时,提高发送速率;当检测到丢包时,按照如下过程调整发送速率:
15、若所述实际丢包率低于拥塞控制的目标丢包率,提高发送速率;
16、若所述实际丢包率高于所述目标丢包率且低于所述bubble-filling丢包率阈值时,维持当前的发送速率。
17、若所述实际丢包率高于所述bubble-filling丢包率阈值,将当前的发送速率降低至一半。
18、可选的,所述目标丢包率的计算方式包括:
19、训练节点根据历史平均吞吐量和历史平均时延,利用最小二乘法拟合出平均吞吐量关于丢包率的第一函数和平均时延关于丢包率的第二函数;基于所述第一函数和所述第二函数计算当前的目标丢包率。
20、可选的,所述跨数据中心分布式机器学习通信方法还包括:
21、当参数服务器接收到的梯度数据包中,高优先级的梯度数据包的比例达到预设比例时,向训练节点发送反馈,以通知该训练节点进入下一个数据包传输窗口期。
22、可选的,所述梯度数据包中携带有梯度张量的元信息;所述梯度张量为该梯度数据包中所含梯度数据形成的张量;所述元信息至少包括该梯度数据包中高优先级的梯度数据的稀疏度;
23、参数服务器对高优先级的梯度数据进行修复,包括:
24、参数服务器根据所述元信息对高优先级的梯度数据进行修复。
25、第二方面,本发明提供了一种跨数据中心分布式机器学习通信系统,所述系统包括多个训练节点和至少一个参数服务器:
26、训练节点,用于对训练模型时计算出的梯度数据进行封装处理,得到多个梯度数据包后,进行带宽估计,并根据估计的带宽确定发送速率;按照所述发送速率将所述多个梯度数据包发送至与自身建立rudp连接的参数服务器;所述梯度数据包的包头中携带了梯度数据的优先级,所述优先级包括高优先级和低优先级;其中,高优先级的梯度数据采用fec编码;
27、参数服务器,用于对高优先级的梯度数据进行修复,并在实际丢包率高于bubble-filling丢包率阈值时,对丢失的低优先级的梯度数据利用bubble-filling机制进行填充;对修复和填充后的梯度数据进行梯度数据聚合,得到聚合梯度数据,并将所述聚合梯度数据发送至训练节点;
28、训练节点,用于根据所述聚合梯度数据更新模型参数,继续训练,直至训练完成。
29、可选的,训练节点,进行带宽估计包括:
30、在每个往返时延内,通过调整拥塞窗口大小,触发网络队列的积累和耗尽来测量出当前带宽。
31、可选的,训练节点,根据估计的带宽确定发送速率的方式,包括:
32、在每个数据包传输窗口期的初始时刻,根据估计的带宽计算初始的发送速率;
33、在每个数据包传输窗口期内,监测梯度数据包的丢失情况;当连续多个往返时延内都没有丢包时,提高发送速率;当检测到丢包时,按照如下过程调整发送速率:
34、若所述实际丢包率低于拥塞控制的目标丢包率,提高发送速率;
35、若所述实际丢包率高于所述目标丢包率且低于所述bubble-filling丢包率阈值时,维持当前的发送速率。
36、若所述实际丢包率高于bubble-filling丢包率阈值,将当前的发送速率降低至一半。
37、可选的,所述目标丢包率的计算方式包括:
38、训练节点根据历史平均吞吐量和历史平均时延,利用最小二乘法拟合出平均吞吐量关于丢包率的第一函数和平均时延关于丢包率的第二函数;基于所述第一函数和所述第二函数计算当前的目标丢包率。
39、可选的,参数服务器,还用于当接收到的梯度数据包中,高优先级的梯度数据包的比例达到预设比例时,向训练节点发送反馈,以通知该训练节点进入下一个数据包传输窗口期。
40、可选的,所述梯度数据包中携带有梯度张量的元信息;所述梯度张量为该梯度数据包中所含梯度数据形成的张量;所述元信息至少包括该梯度数据包中高优先级的梯度数据的稀疏度;
41、参数服务器,对高优先级的梯度数据进行修复,包括:
42、参数服务器根据所述元信息对高优先级的梯度数据进行修复。
43、第三方面,本发明提供一种电子设备,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;
44、存储器,用于存放计算机程序;
45、处理器,用于执行存储器上所存放的程序时,实现上述任一种跨数据中心分布式机器学习通信方法所述的方法步骤。
46、第四方面,本发明提供了一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现上述任一种跨数据中心分布式机器学习通信方法所述的方法步骤。
47、在本发明的又一方面中,还提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述任一种跨数据中心分布式机器学习通信方法所述的方法步骤。
48、本发明提供的一种跨数据中心分布式机器学习通信方法,通过训练节点对训练模型时计算出的梯度数据进行封装处理,得到多个梯度数据包;训练节点进行带宽估计,并根据估计的带宽确定发送速率;训练节点按照发送速率将多个梯度数据包发送至与自身建立rudp连接的参数服务器;梯度数据包的包头中携带了梯度数据的优先级,优先级包括高优先级和低优先级;其中,高优先级的梯度数据采用fec编码;参数服务器对高优先级的梯度数据进行修复,并在实际丢包率高于bubble-filling丢包率阈值时,对丢失的低优先级的梯度数据利用bubble-filling机制进行填充;参数服务器对修复和填充后的梯度数据进行梯度数据聚合,得到聚合梯度数据,并将聚合梯度数据发送至训练节点;训练节点根据聚合梯度数据更新模型参数,继续训练,直至训练完成。
49、通过对梯度数据进行优先级的划分,且对高优先级的梯度数据采用fec编码,提供了差异化的可靠性保证,避免了高优先级的梯度数据的丢失。而对于丢失的低优先级的梯度数据仅在实际丢包率高于bubble-filling丢包率阈值时,对其利用bubble-filling机制进行填充,容忍了一定的低优先级的梯度数据的丢失,显著提高了训练效率,同时也避免了因丢失的低优先级的梯度数据过多而导致训练效果不佳的情况出现。
50、此外,通过利用估计的带宽从而确定梯度数据包的发送速率,充分保证了对于网络资源的利用。
51、以下将结合附图及对本发明做进一步详细说明。
本文地址:https://www.jishuxx.com/zhuanli/20240822/278386.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。