一种基于先分组的数据配组算法的制作方法
- 国知局
- 2024-08-22 14:24:16
本发明涉及数据配组,具体为一种基于先分组的数据配组算法。
背景技术:
1、伴随着大数据、云计算以及算法的发展,人工智能广泛应用于多个行业和领域,同样,伴随着数据量与数据来源的猛增,数据治理也成为了企业在充分挖掘利用数据价值过程中必不可少的环节,并逐渐发展为企业的核心业务之一;数据治理从概念到技术已经发生了很多变化,特别是数据治理技术和人工智能技术有效的融合在一起,使智能化数据治理成为可能。
2、对于一组数据,按照误差规则删选数据并进行分组,如果仅根据误差规则,两两相互进行比较差值在误差范围内,该条件未免太过于苛刻,只有如下两种情况可以满足:一是:所有的数据都相等,这样两两比较差值肯定是在误差范围内,二是:所有的数据只存在两个值,而且这两个值的差值也在误差范围内,这样无法将局部相对集中的数据划分为一组,因此提出一种基于先分组的数据配组算法。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了一种基于先分组的数据配组算法,通过标识解析技术,对于一组数据根据误差规则进行分组,将数据先进行排序,把相对集中的数据划为一组,使得小组之内的数据两两进行比较差值在误差范围之内,然后再扩大范围比较,进行组与组之间数据比较,如果也满足误差规则,则这两组就可以合并为一组,以此类推,尽可能的把更多的数据划分为一组,方便对数据进行快速处理。
3、(二)技术方案
4、为实现上述目的,本发明提供如下技术方案:
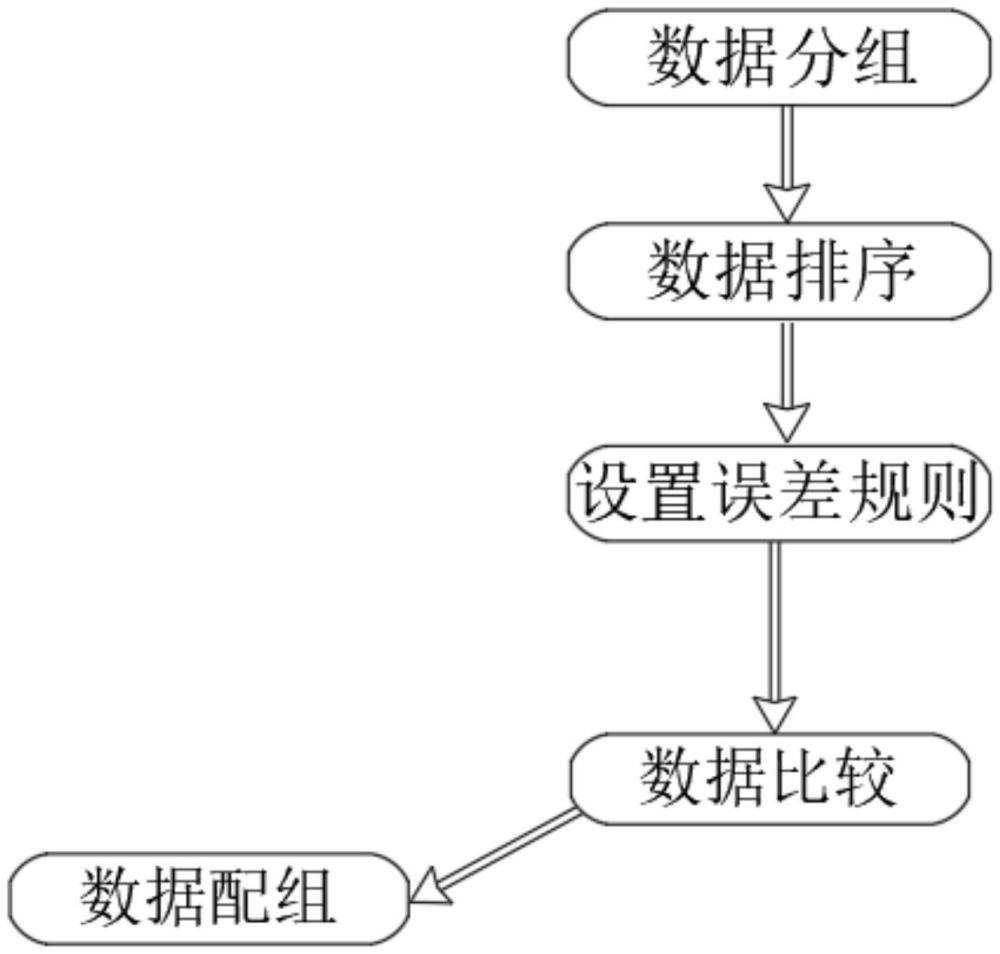
5、一种基于先分组的数据配组算法,包括以下步骤:
6、s1:数据分组:对于一组数据根据误差规则进行分组;
7、s2:数据排序:把分组后的数据进行排序,把相对集中的数据划为一组;
8、s3:设置误差规则:预设误差规则,并根据每个影响因素对应的误差允许范围计算阈值范围;
9、s4:数据比较:把分组后的数据进行组与组之间数据比较,
10、当比较结果在阈值范围,满足误差规则时,则把这两组数据合并为一组;
11、当比较结果不在所述阈值范围内时,则视为不满足误差规则,不进行合并,并进行下一组比较;
12、s5:数据配组,依次类推,把满足误差规则的数据进行合并,把更多的数据划分为一组。
13、作为本发明再进一步的方案,所述s2中包括排序模块,所述s1中包括分组模块,分组模块和排序模块相连接。
14、进一步的,所述s3中预设误差规则为预先制定的针对于不同操作类别下每个影响因素对应的误差允许范围。
15、在前述方案的基础上,所述s4中包括数据比较模块和数据合并模块,数据组经过数据比较模块比较后,满足条件的通过数据合并模块进行合并。
16、进一步的,所述s4中包括信息解析模块,且信息解析模块与模型建立模块相连接。
17、作为本发明再进一步的方案,所述s4中,对不满足误差规则的数据组,计算阈值范围内的每个值与计算结果的差值,选择差值的绝对值最小的值作为最终计算结果;若所述最终计算结果与所述计算结果的差值的绝对值超过预设值,则不合并,不超过预设值,则进行合并。
18、(三)有益效果
19、与现有技术相比,本发明提供了一种基于先分组的数据配组算法,具备以下有益效果:
20、1、本发明,通过将分组后的数据进行排序,把相对集中的数据划为一组,使得小组之内的数据两两进行比较差值在误差范围之内。
21、2、本发明,对于一组数据根据误差规则进行分组,将数据先进行排序,把相对集中的数据划为一组,然后再扩大范围比较,进行组与组之间数据比较,如果也满足误差规则,则这两组就可以合并为一组,以此类推,尽可能的把更多的数据划分为一组,方便对数据进行快速处理。
技术特征:1.一种基于先分组的数据配组算法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于先分组的数据配组算法,其特征在于,所述s2中包括排序模块,所述s1中包括分组模块,分组模块和排序模块相连接。
3.根据权利要求2所述的一种基于先分组的数据配组算法,其特征在于,所述s3中预设误差规则为预先制定的针对于不同操作类别下每个影响因素对应的误差允许范围。
4.根据权利要求1所述的一种基于先分组的数据配组算法,其特征在于,所述s4中包括数据比较模块和数据合并模块,数据组经过数据比较模块比较后,满足条件的通过数据合并模块进行合并。
5.根据权利要求1所述的一种基于先分组的数据配组算法,其特征在于,所述s4中包括信息解析模块,且信息解析模块与模型建立模块相连接。
6.根据权利要求1所述的一种基于先分组的数据配组算法,其特征在于,所述s4中,对不满足误差规则的数据组,计算阈值范围内的每个值与计算结果的差值,选择差值的绝对值最小的值作为最终计算结果;若所述最终计算
技术总结本发明涉及数据配组技术领域,且公开了一种基于先分组的数据配组算法,包括以下步骤:S1:数据分组:对于一组数据根据误差规则进行分组;S2:数据排序:把分组后的数据进行排序,把相对集中的数据划为一组;S3:设置误差规则:预设误差规则,并根据每个影响因素对应的误差允许范围计算阈值范围;S4:数据比较:把分组后的数据进行组与组之间数据比较。本发明对于一组数据根据误差规则进行分组,将数据先进行排序,把相对集中的数据划为一组,然后再扩大范围比较,进行组与组之间数据比较,如果也满足误差规则,则这两组就可以合并为一组,以此类推,尽可能的把更多的数据划分为一组,方便对数据进行快速处理。技术研发人员:刘鹏,黄羿衡,李啸,许伟娟受保护的技术使用者:江苏苏云信息科技有限公司技术研发日:技术公布日:2024/8/20本文地址:https://www.jishuxx.com/zhuanli/20240822/278598.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。