基于语音识别及人工智能的影像报告自动生成方法及系统
- 国知局
- 2024-08-22 14:33:38
本发明涉及医学影像报告生成,特别是涉及一种基于语音识别及人工智能的影像报告自动生成方法及系统。
背景技术:
1、随着医疗行业的快速发展,医学影像在临床诊断和治疗中发挥着越来越重要的作用。医学影像报告是医生根据患者的影像资料,对病情进行描述和分析的重要文档,对于诊断和治疗具有至关重要的作用。然而,传统的影像报告撰写方式耗时耗力,且容易受到主观因素的影响,导致报告的质量和准确性受到影响。为了提高医学影像报告的生成效率及准确性,迫切需要将人工智能技术引入到这一领域。
2、近年来,人工智能技术取得了显著的进步,特别是在语音识别、自然语言处理和深度学习等方面,在医疗领域的应用日益广泛,尤其是在医学影像报告的自动生成方面展现出巨大的潜力,这使得利用人工智能辅助医生完成医学影像报告的编写成为可能。然而,目前用于影像科室的人工智能产品大多数是针对医学图像的分割、检测、诊断的产品,解决医师文本输入效率低、准度低的产品尚未报道。因此,如何利用人工智能技术实现医学影像报告的自动生成,提高医生的工作效率,降低人工误差,成为了一个重要的研究方向。
技术实现思路
1、本发明的目的是提供一种基于语音识别及人工智能的影像报告自动生成方法及系统,通过集成语音识别技术、文本预处理、多场景训练集构建、人工智能大模型训练及基于人类反馈的强化学习技术,实现了医生口述内容的高效、准确转录与影像报告的自动化生成。
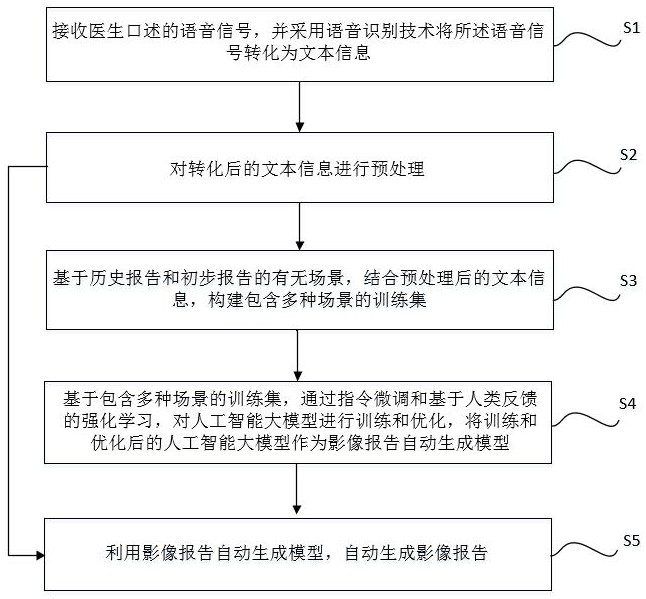
2、为实现上述目的,本发明提供了一种基于语音识别及人工智能的影像报告自动生成方法,包括以下步骤:
3、s1,接收医生口述的语音信号,并采用语音识别技术将所述语音信号转化为文本信息;
4、s2,对转化后的文本信息进行预处理;
5、s3,基于历史报告和初步报告的有无场景,结合预处理后的文本信息,构建包含多种场景的训练集;
6、s4,基于包含多种场景的训练集,通过指令微调和基于人类反馈的强化学习,对人工智能大模型进行训练和优化,将训练和优化后的人工智能大模型作为影像报告自动生成模型;
7、s5,利用影像报告自动生成模型,自动生成影像报告。
8、进一步地,所述步骤s1中,接收医生口述的语音信号,并采用语音识别技术将所述语音信号转化为文本信息,具体包括:
9、接收来自特定方向或特定半径范围的医生口述的语音信号,并进行即时存储;
10、采用语音识别技术将所述语音信号实时转化为文本信息,并同步显示文本信息,供医生在线查看及编辑;
11、对语音信号和转化后的文本信息进行加密处理。
12、进一步地,步骤s2,所述预处理,具体包括:
13、文本清洗与结构优化:剔除非关键信息、分段和格式化;
14、标准化处理:采用自然语言处理算法,将转化后的文本信息规范为医学专业术语。
15、进一步地,所述步骤s3中,基于历史报告和初步报告的有无场景,结合预处理后的文本信息,构建包含多种场景的训练集,具体包括:
16、针对无历史报告、无初步报告的场景,构建的训练集中,模型输入包括患者基本信息、预处理后的文本信息和提示词,模型输出包括经过放射科专家审核后的正式报告;
17、针对有历史报告、无初步报告的场景,构建的训练集中,模型输入包括患者基本信息、历史报告、预处理后的文本信息和提示词,模型输出包括经过放射科专家审核后的正式报告;
18、针对无历史报告、有初步报告的场景,构建的训练集中,模型输入包括患者基本信息、初步报告、预处理后的文本信息和提示词,模型输出包括经过放射科专家审核后的正式报告;
19、针对有历史报告、有初步报告的场景,构建的训练集中,模型输入包括患者基本信息、历史报告、初步报告、预处理后的文本信息和提示词,模型输出包括经过放射科专家审核后的正式报告。
20、进一步地,所述步骤s4,基于多种场景的训练集,通过指令微调和基于人类反馈的强化学习,对人工智能大模型进行训练和优化,将训练和优化后的人工智能大模型作为影像报告自动生成模型,具体包括:
21、基于包含多种场景的训练集,使用指令数据对人工智能大模型进行有监督微调,得到初始的影像报告自动生成模型;
22、对初始的影像报告自动生成模型,采用基于人类反馈的强化学习方法进行迭代优化,得到优化后的影像报告自动生成模型。
23、进一步地,所述人工智能大模型为开源大模型。
24、本发明还提供一种基于语音识别及人工智能的影像报告自动生成系统,执行上述的基于语音识别及人工智能的影像报告自动生成方法,包括:
25、语音采集与识别模块,用于接收医生口述的语音信号,并采用语音识别技术将所述语音信号转化为文本信息;
26、文本预处理模块,用于对转化后的文本信息进行预处理;
27、训练集构建模块,用于基于历史报告和初步报告的有无场景,结合预处理后的文本信息,构建包含多种场景的训练集;
28、模型训练与优化模块,用于基于包含多种场景的训练集,通过指令微调和基于人类反馈的强化学习,对人工智能大模型进行训练和优化,将训练和优化后的人工智能大模型作为影像报告自动生成模型;
29、影像报告生成模块,用于利用影像报告自动生成模型,自动生成影像报告。
30、进一步地,所述语音采集与识别模块,包括:
31、定向、定范围麦克风,用于接收来自特定方向或特定半径范围的医生口述的语音信号;
32、录音存储设备,用于对语音信号进行即时存储;
33、语音识别模块,用于采用语音识别技术将所述语音信号实时转化为文本信息;
34、显示模块,用于显示转化中的文本信息,供医生在线查看及编辑;
35、数据加密模块,用于对语音信号和转化后的文本信息进行加密处理。
36、进一步地,所述系统的部署方式包括以下任一种或多种:
37、容器化部署:使用容器化技术将系统打包,确保在不同环境中的一致性和可移植性;
38、云服务部署:利用云服务提供商的虚拟机或服务器托管服务进行部署;
39、无服务器架构:采用无服务器架构,让云服务提供商自动管理运行环境;
40、kubernetes集群:对于需要高可用性和自动扩展的系统,使用kubernetes进行容器编排,管理和调度容器化的应用;
41、微服务架构:将系统拆分为多个独立的微服务,每个微服务负责特定的功能;
42、本地化部署:对于对数据隐私和安全性有特殊要求的机构,在本地服务器上部署系统,对数据进行本地存储和管理;
43、混合部署:结合云服务和本地服务器的优势,创建混合部署环境;
44、边缘计算:在数据源附近部署ai模型;
45、ci/cd流程:建立持续集成和持续部署的流程,自动化测试、构建和部署过程;
46、监控和日志系统:部署全面的监控和日志系统,实时监控系统性能和健康状态,及时发现和解决问题。
47、本发明还提供一种电子设备,包括:至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述的基于语音识别及人工智能的影像报告自动生成方法。
48、本发明的技术效果为:
49、本发明提出一种基于语音识别及人工智能的影像报告自动生成方法及系统,首先,采用高效的语音识别技术,将医生的口述内容实时转化为文本信息;其次,通过文本预处理技术,对转化后的文本信息进行清洗、结构优化、标准化等处理,提高后续处理的准确性;进而,基于历史报告和初步报告的有无场景,构建多场景训练集,对人工智能大模型进行训练,使其能够适应不同场景下的口述内容;在训练过程中,引入基于人类反馈的强化学习技术,不断优化模型性能,提高影像报告生成的质量。本发明旨在利用人工智能技术,提高放射科医生的工作效率,减少认知负担,降低人工误差,并确保报告的专业性和临床适用性,为患者提供更加准确、及时的影像报告。本发明通过基于人类反馈的强化学习技术实现自我进化的机制,不断收集医生的使用反馈,并结合强化学习算法,自动调整和优化报告生成模型,以适应临床实践中不断变化的需求和场景。这一机制显著提升了系统的灵活性和适应性,确保即使在面对复杂病例时,也能生成高质量、符合临床要求的报告。本发明具备多语言和方言支持、数据安全保障、便捷交互体验以及持续升级优化等特点。在未来的发展中,本发明有望成为医疗行业中的一个重要工具,助力提升医疗服务质量,造福广大患者。
本文地址:https://www.jishuxx.com/zhuanli/20240822/279123.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。