一种基于改进随机森林算法的学习预警方法
- 国知局
- 2024-08-22 14:54:17
本发明属于计算机数据挖掘以及在线教学,特别涉及一种基于改进随机森林算法的学习预警方法。
背景技术:
1、随着线上线下混合式教育的发展,如何保证学习质量和教学进度成为了关键问题,比如线下教学老师无法获取学生课余时间的学习状况,线上教学老师无法精准获取学生听课情况等问题,针对这些问题,通过学业预警、淘汰、退课机制,让老师从“事后分析”变成“事前预测”,动态检测学生的学习状态,从学生的情绪、听课状态、上课考勤等各方面综合评估学生的学习情况和期末成绩,判断是否有不及格、退课的可能。从而更好地满足在混合式教学模式下对学习者个性化的要求。
2、近年高校对学生成绩的研究大多注重对学生成绩影响因素的挖掘,主要是在学生所学课程门类、学生所处年级以及考试成绩方面进行研究,并主要以机器学习相关技术来对学生学习数据进行挖掘分析。同时也有使用聚类方法和关联性分析算法等其他方法进行挖掘,很多研究者都对数据挖掘算法的设置以及关联性算法进行了一定程度的改进以提高算法效率。就所采集的数据情况来看,文献多使用本校学生成绩信息或者是网上的公开数据集开展研究,但原始数据总体质量较低,或者数据量太少,无法得到可信的学习预警模型,存在数据收集困难的问题。
3、本发明拟解决学习成绩预测研究领域中存在的“特征难以提取”,“数据集不均衡”和“模型易于退化”三个关键问题。
4、(1)特征难以提取问题
5、现有特征提取算法仍存在部分冗余或遗漏重要特征的情况,特征数量的增加极大地提升了模型的复杂性,从而影响了后续检测模型的性能。如何对特征进行有效降维,如何保留相关性强的特征,如何对隐式特征进行挖掘以及如何设计合适的特征选择方法以提高学习效率和检测性能,这些问题的可研究性依然很高,选择合适的特征选择方法可能会比选择合适的包装器提升效率更高。
6、(2)数据不平衡学习问题
7、目前已报道的不平衡学习方法,不完全适用于当代学生学习成绩预测任务,无法兼顾多类课程和不同学生的识别效果。数据不平衡情形下,如何有效区分不同学习课程成绩的特征差异,如何克服数据不平衡带来的不利影响以及如何设计合适的检测方式提高模型的学习效率与预测性能,对这些问题进行系统性研究和评估,可丰富和完善面向不平衡学习的学习成绩预测技术。
8、(3)检测模型退化问题
9、这个问题属于模型持续学习过程中灾难性遗忘问题,也是困扰学习成绩预测研究领域且尚未得到有效解决的难题之一。主要包括:如何设计新的特征表征方式以适应学习成绩及学生个体差异的不断的更新进化,如何有效挖掘学生成绩变化后的特征,增量学习能否应用于解决学习成绩预测中的概念漂移问题以及如何通过优化模型来提升随机森林的检测性能,这些都是该领域极具挑战性的问题,具备较高的研究价值。
技术实现思路
1、为克服上述现有技术的缺点,本发明的目的在于提供一种基于改进随机森林算法的学习预警方法,以解决学习成绩预测研究领域中存在的“特征难以提取”,“数据集不均衡”和“模型易于退化”三个关键问题。
2、为了实现上述目的,本发明采用的技术方案是:
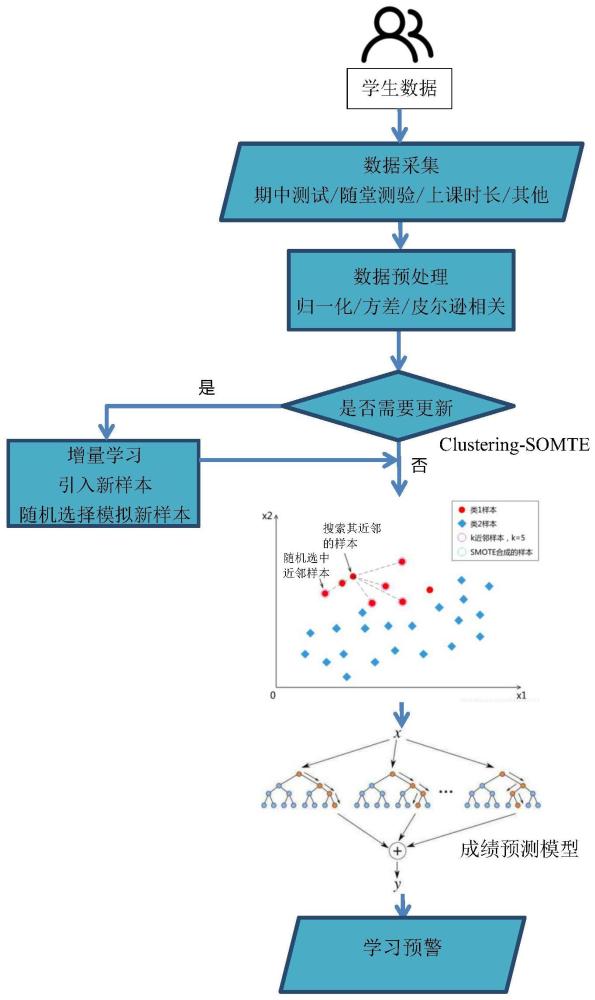
3、一种基于改进随机森林算法的学习预警方法,包括如下步骤:
4、步骤1,采集学生数据,并对异常值和缺失值进行预处理,划分训练集和测试集;所述学生数据包括学生学习数据和校园网在线数据,所述学生学习数据包括学生个人信息、单元测验数据、回答问题次数以及参与课程问卷调查次数;
5、步骤2,采用改进随机森林算法训练成绩预测模型,包括:
6、步骤2.1,对预处理后的学生数据进行基于测量方差和pearson相关系数的特征筛选,剔除冗余和不相关的特征;
7、步骤2.2,对剔除冗余和不相关的特征后的数据集进行聚类处理,形成n个类中心,并生成用于训练成绩预测模型的人工样本,将得到的人工样本的样本集划分为等大小的样本子集,每个决策树基于不同的样本子集进行训练;
8、步骤2.3,从所述样本集中生成n棵决策树,将每个决策树基于不同的样本子集进行训练,单独迭代更新,结合n棵树中的信息进行投票加权预测;
9、步骤3,引入增量学习,使成绩预测模型能够在新的学生成绩数据到来时逐步更新,适应学业表现的动态变化;在每一轮迭代中,新样本被逐步引入到每棵树中,模拟新知识的逐步融入学习过程;
10、步骤4,根据预测结果,将触发的预警发给老师和学生。
11、本发明通过测量方差和pearson相关系数等规则进行特征选择,过滤掉冗余和不相关的特征,提高模型计算效率,从而解决特征难以提取的问题;本发明利用k均值聚类方法将学生划分为相似的群体,识别学科特征的潜在群体结构。针对每个聚类群体,采用smote技术生成合成的少数类样本,以平衡不同群体间学生成绩的不平衡性,从而解决数据集不均衡的问题;本发明通过引入增量学习技术,逐步引入新的学生成绩数据,实时更新模型。这确保了模型能够更灵活地适应学业表现的动态变化,从而解决模型易于退化的问题。
12、与现有技术相比,本发明在基于目前学习预警研究成果的基础上,引入聚类—smote技术的样本合成方法和基于增量学习技术的样本更新方法设计一个新的学习预警模型。此模型不仅提高了模型的灵活性,还实现了对学生成绩的实时预测。
技术特征:1.一种基于改进随机森林算法的学习预警方法,其特征在于,包括如下步骤:
2.根据权利要求1所述基于改进随机森林算法的学习预警方法,其特征在于,所述步骤1,采集的学生学习数据为表格文件,首先对同一个学生的数据进行组合,并根据学习视频的时长和动作为学生的校园网浏览数据打标签,然后将标签数据引入完成组合的表格,并将表格文件转换成csv格式,对数据进行清洗,剔除无效数据和异常数据,并对缺失值进行补充。
3.根据权利要求2所述基于改进随机森林算法的学习预警方法,其特征在于,所述对同一个学生的数据进行组合,是通过数据整合将同一单元同一学生学习过程的数据整理成一条该学生的数据,再将特征变量拼接在一个表上,得到学生的完整学习数据;所述学生个人信息包括:学生的姓名、学号、班级以及前置数据,所述前置数据,是指学生在学习某一学科之前,与该学科相关的参考成绩数据;所述单元测验数据包括班级编号、班级名称、姓名、用户名、所属分组、提交成绩、题目类型、最终成绩、开始测试时间、提交测试时间以及测试用时。
4.根据权利要求1所述基于改进随机森林算法的学习预警方法,其特征在于,所述步骤22,采用聚类—smote技术进行聚类处理并生成人工样本,方法如下:
5.根据权利要求1所述基于改进随机森林算法的学习预警方法,其特征在于,所述步骤2.2,n为聚类算法误差平方和的拐点对应的聚类数量,类中心数量为4。
6.根据权利要求1所述基于改进随机森林算法的学习预警方法,其特征在于,所述步骤2.3,通过随机森林算法,从样本集中生成n棵决策树;所述结合n棵树中的信息进行投票加权预测的方法是:通过计算每棵树和最终真实期末成绩的误差平方和,计算权值。
7.根据权利要求1所述基于改进随机森林算法的学习预警方法,其特征在于,所述步骤3,引入增量学习的方法是:通过增加决策树的数量,调整参数,进行迭代动态更新。
8.根据权利要求1所述基于改进随机森林算法的学习预警方法,其特征在于,所述步骤4,所述预测结果为预测出最终的课程成绩,触发的预警类型包括单元预警、不及格与退课预警、学业预警和教师预警。
9.根据权利要求8所述基于改进随机森林算法的学习预警方法,其特征在于,所述单元预警,是在每个单元测试结束之前对目前尚未开始答题的学生以及成绩未及格的学生分别发出做题提醒,在测试结束后对本单元最终成绩不及格和预测成绩有不及格风险的学生预警,提醒该学生本知识点掌握不充分;
10.根据权利要求9所述基于改进随机森林算法的学习预警方法,其特征在于,所述预测出最终的课程成绩,公式如下:
技术总结本发明公开了一种基于改进随机森林算法的学习预警方法,采集学生数据,并对异常值和缺失值进行预处理,基于测量方差和Pearson相关系数剔除冗余和不相关的特征,然后进行聚类形成N个类中心,生成用于训练成绩预测模型的人工样本,并划分为等大小的样本子集,每个决策树基于不同的样本子集进行训练,从样本集中生成N棵决策树,将每个决策树基于不同的样本子集进行训练,单独迭代更新,结合N棵树中的信息进行投票加权预测;引入增量学习,使成绩预测模型能够在新的学生成绩数据到来时逐步更新,适应学业表现的动态变化;在每一轮迭代中,新样本被逐步引入到每棵树中,模拟新知识的逐步融入学习过程;根据预测结果,将触发的预警发给老师和学生。技术研发人员:徐宝清,薛星宇,王东昫,李雷孝,马志强受保护的技术使用者:内蒙古工业大学技术研发日:技术公布日:2024/8/20本文地址:https://www.jishuxx.com/zhuanli/20240822/280331.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表