一种基于informer多智能体强化学习的复杂场景电动汽车充电引导方法
- 国知局
- 2024-08-22 14:59:19
本发明涉及电动汽车充电引导的,尤其涉及一种基于informer多智能体强化学习的复杂场景电动汽车充电引导方法。
背景技术:
1、目前随着全球气候变化和污染的加剧,电动汽车作为一种低碳、清洁的交通工具,受到了全世界的高度关注。随着电动汽车充电需求量急剧增加,充电站基础设施与电动汽车数量的比例不足,会导致电动汽车出现找不到合适充电站,产生充电拥堵,且驾驶员的无固定规则决策会加剧充电桩利用的不平衡,导致充电时间成本的增加。因此,智能有效的电动汽车充电引导方法对于提升用户的充电体验和有效利用充电设施资源具有重要意义。此外,随着电力网与交通网逐渐进行着深度耦合,在城市交通网络中大规模电动汽车前往充电站的路径导航也面临着时间不确定性、里程限制等问题。因此采取有效的充电引导为电动汽车合理推荐充电站并规划最优导航路径,可以减少电池容量限制给ev用户带来的行驶里程焦虑,降低电动汽车行驶和充电过程对电网和交通网的冲击。
2、目前对电动汽车充电引导相关领域已经有了不少的研究,电动汽车充电引导通过对推荐电动汽车合适的充电站和电动汽车前往充电站的路径导航两部分进行研究。然而电动汽车充电引导决策的传统算法依赖于数学规划模型,导致在城市规模的网络中计算效率较低,解的性能不稳定。在复杂的动态耦合系统中,很难对充电需求进行快速响应。
3、近年来,强化学习在解决复杂环境中顺序决策问题并引起人们的广泛关注。相对于基于数学模型的求解方法和启发式方法,深度强化学习能够基于当前状态进行实时、在线的决策。由于深度强化学习被认为是构建通用人工智能的重要技术,并且成功地与多智能体系统结合,出现了多智能体深度强化学习。对于电动汽车充电引导需要考虑电动汽车、充电站、交通环境信息复杂的复杂多变,使用多智能体强化学习实现电动汽车充电引导的多目标优化时,多智能体学习过程的不稳定的,同时如何实现多智能体之间的协调与合作也存在巨大的挑战。
4、例如申请号202311096583.8的发明专利公开了一种基于经济调度的电动汽车智能充电策略选择方法,涉及电动汽车技术领域,针对现有技术中方法没有考虑到时变路况的影响,会导致电动汽车无法及时充上电的问题,该申请结合了用户的充电成本和道路拥挤程度来设计最优的充电策略,以缓解交通拥堵并提高用户满意度,该申请可以使电动汽车根据自身的充电需求选择最合适的充电桩进行充电任务。该申请还为电动汽车提供了合适的充电策略,并最大限度地降低了充电成本,减少了道路的拥堵。数值结果表明,本技术在实际场景中具有有效性和优越性,实现了发电成本和碳排放量最小化的目标。该申请可以在最小化电力调度成本和碳排放量的前提下实现电动汽车较低的充电成本。但是,该申请没有考虑电动汽车前往充电站的时间成本,也没考虑前往某充电站的其他电动汽车数量。
技术实现思路
1、针对现有技术中多智能体之间协助难度较大的技术问题,本发明提出一种基于informer多智能体强化学习的复杂场景电动汽车充电引导方法,最小化时间成本、电价成本和充电失败率的多种优化目标,实现高效实时在线的电动汽车充电引导。
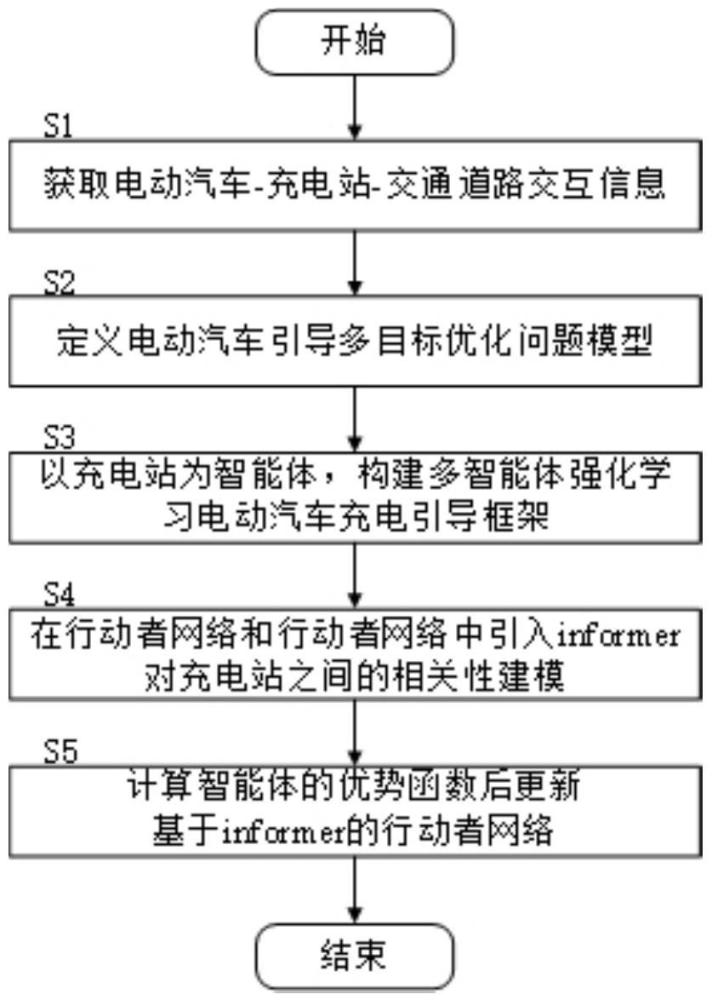
2、为了达到上述目的,本发明的技术方案是这样实现的:一种基于informer多智能体强化学习的复杂场景电动汽车充电引导方法,其步骤包括:
3、s1:综合获取电动汽车-充电站-交通道路交互信息;
4、s2:基于电动汽车-充电站-交通道路交互信息,构建电动汽车引导多目标优化函数;
5、s3:以充电站为智能体,将电动汽车引导多目标优化函数建立为马尔可夫决策问题,构建多智能体强化学习电动汽车充电引导框架;
6、s4:基于多智能体强化学习电动汽车充电引导框架设计基于informer网络的行动者-评论家算法,并通过最小化损失值对行动者-评论家算法更新;
7、s5:计算智能体的优势函数限制行动者-评论家算法的更新幅度,得到复杂场景电动汽车充电引导策略。
8、步骤s1所述电动汽车-充电站-交通道路交互信息包括:产生充电需求的电动汽车当前位置、剩余电量、行驶方向、区域内所有充电站充的位置、充电站内充电桩使用信息、前往充电站的电动汽车数量、区域内所有道路信息和交通拥堵情况。
9、步骤s2所述构建电动汽车引导多目标优化函数的方法为:
10、基于电动汽车-充电站-交通道路交互信息得到电动汽车在充电站的行驶能耗成本、行驶时间成本、充电等待时间成本和充电成本,生成电动汽车引导多目标优化的函数,电动汽车引导多目标优化函数表示为:
11、
12、其中,ei,k,t、分别表示t时刻电动汽车i在充电站k的行驶能耗成本、行驶时间成本、充电等待时间成本和充电成本;uk,t表示t时刻充电站k的成功率;ω1,ω2,μ1,μ2,μ3分别表示行驶能耗成本、行驶时间成本、充电等待时间成本、充电成本和电动汽车充电成功率的权重系数,引导多目标优化函数的约束条件为电动汽车剩余能量大于电动汽车i前往充电站k的里程能耗成本ei,k,t。
13、基于电动汽车-充电站-交通道路交互信息得到电动汽车在充电站的行驶能耗成本的方法为:
14、基于产生充电需求的电动汽车当前位置、行驶方向、区域内所有充电站充的位置和区域内所有道路信息得到行驶能耗成本ei,k,t:
15、
16、其中,ε表示单位里程耗电量;表示电动汽车平均充电电价;dl表示行驶路段l的行驶里程;li,k表示电动汽车i到充电站k的行驶路段;
17、基于交通拥堵情况、产生充电需求的电动汽车当前位置、行驶方向、区域内所有充电站充的位置和区域内所有道路信息得到行程时间成本
18、
19、其中,表示电动汽车行程中t时刻电动汽车i前往充电站k行程时间,β>0和γ>0是常数;tl,t表示t时刻电动汽车在路段l的自由通行时间;vl/bl表示路段l的拥堵率,vl为电动汽车在路段l上的行驶速度;
20、基于充电站内充电桩使用信息和前往充电站的电动汽车数量得到充电等待时间
21、
22、其中,tavg表示电动汽车平均充电时长;表示向下取整计算;表示充电站内排队最小充电时间,根据电站内充电桩使用信息,若电动汽车i到达充电站k时,t时刻充电站k中正在充电的电动汽车数量nc,t小于其总充电桩数量ck,则电动汽车i的充电等待时间为0,可以直接充电;
23、基于电动汽车剩余电量得到充电时间
24、
25、其中,ecap为电动汽车额定电池容量,pch为额定充电功率,η为充电效率,为电动汽车达到充电站时的荷电状态。
26、基于电动汽车剩余电量得到充电费用
27、
28、其中,λk,t表示t时刻充电站k的充电电价;
29、充电站成功率uk,t:
30、
31、其中,iall是所有充电需求的电动汽车,is充电成功的电动汽车。
32、步骤s3所述将电动汽车引导多目标优化函数建立为马尔可夫决策问题的方法为:
33、将电动汽车引导多目标优化函数构建为马尔可夫决策过程,构建多智能体强化学习电动汽车充电引导框架,包括n个智能体ck;t时刻智能体ck通过观察电动汽车-充电站-交通道路交互信息得到观测状态ok,t:
34、
35、其中,hi,t和分别表示t时刻有充电需求的电动汽车i的位置和soc;λk,t、mk,t和nk,t分别表示t时刻充电站k的电价、已预订充电的电动汽车数量和正在充电的电动汽车数量;ti,k和ei,k分别表示电动汽车i到达充电站k的行驶时间和电能消耗量;t时刻所有智能体的全局状态为st={o1,t,o2,t,…,on,t};每个智能体ck根据自己的观测状态ok,t选择自己的动作ak,t,将自己推荐给有充电需求的电动汽车i;动作ak,t是每个智能体ck提供竞价值,竞价值属于[0,1];
36、所有智能体的动作构成联合动作ut={a1,t,a2,t,…,an,t};奖励分为两阶段,包括充电路径奖励和充电站充电奖励,充电路径奖励为:
37、
38、其中,电动汽车所剩电量不足以到达充电站受到的惩罚,设置为较大的常数,ti,k,t表示t时刻电动汽车前往充电站k行程时间;
39、充电站充电奖励为:
40、
41、其中,为电动汽车在充电站点等待时间超时受到的惩罚,设置为较大的常数。
42、步骤s4所述设计基于informer网络的行动者-评论家算法的方法为:
43、s41:通过投影层p将多智能体强化学习电动汽车充电引导框架中原始的观测状态ok,t转换为基于智能体节点的嵌入;
44、s42:通过线性函数将智能体节点的嵌入投影到集中式动作值函数q的输出空间,将每个智能体的动作中输入informer网络中;
45、s43:基于informer网络的函数通过最小化损失对informer网络的行动者-评论家算法更新。
46、步骤s41所述p将多智能体强化学习电动汽车充电引导框架中原始的观测状态ok,t转换为基于智能体节点的嵌入的方法为:
47、通过投影层p将原始的观测状态ok,t转换为基于智能体节点的嵌入,表达式如下:
48、inputk,t={p(o1,t),p(o2,t),…,p(on,t)};
49、将确定观测状态ok,t和联合动作uk,t将确定观测ok,t和联合动作uk,t组合为元组(ok,t,uk,t),利用informer网络对智能体之间的相关性建模,将n个元组(ok,t,uk,t)转换为n个基于智能体节点的嵌入:
50、{e1,t,…,en,t}=informer({(o1,t,u1,t),…,(on,t,un,t)});
51、其中,e1,t,…,en,t表示informer网络将n个元组(ok,t,uk,t)转换为n个嵌入元素,informer为informer网络网络层。
52、步骤s42所述将智能体节点的嵌入投影到集中式动作值函数q的输出空间的方法为:
53、通过线性函数将基于智能体节点的嵌入投影到集中式动作值函数q的输出空间,得到全局动作策略函数
54、
55、其中,lineaar是线性网络层;
56、给定采取行动的智能体的状态sa,t和动作uk,t,则智能体的行为策略μk用期望收益梯度表示为:
57、
58、其中,是求期望函数公式符号,d为所有智能体的经验重放缓冲区记录转换,是智能体的动作ak,t的期望收益梯度。
59、步骤s43所述通过最小化损失值对informer网络的行动者-评论家算法更新的公式为:
60、
61、其中,θq为批评家的可学习参数,和分别是智能体的目标行为者策略和具有延迟参数的目标评价函数,r为总奖励,t+j表示在t时候后的第j时刻。
62、步骤s5所述限制行动者-评论家算法的更新幅度的方法为:
63、计算多个智能体的优势函数公式为:
64、
65、其中,表示在全局状态sa,t下采取动作ak,t的价值,表示在全局状态sa,t下的平均价值;
66、利用clip函数对比更新前的行动者-评论家算法和更新后的行动者-评论家算法:
67、
68、其中,∈是clip幅度的超参数,当rt(θ)超出[1-∈,1+∈]的范围时,clip函数将rt(θ)限制在这个范围内,rt(θ)为更新前的行动者-评论家算法损失值和更新后的行动者-评论家算法损失值的差。
69、本发明的有益效果为:首先获取某区域产生充电需求的电动汽车数据信息(当前位置、剩余电量和行驶方向)、充电站充(地理位置、充电站内充电桩使用信息、前往充电站的电动汽车数量)和交通道路信息。定义电动汽车引导实现最小化电动汽车行驶到充电站的时间、在充电站等待充电的时间、充电成本最低和最大化充电成功率的多目标优化问题模型。其次以充电站为智能体,综合电动汽车和充电站以及两者之间的交通信息,定义电动汽车引导多目标优化问题为多智能体强化学习任务。最后设计了基于informer网络的行动者-评论家算法,在评论家网络引入informer对充电站之间的相关性建模,减少智能体策略学习复杂度,增强智能体之间协调引导;在计算智能体的优势函数后更新行动者网络,提高网络的学习效率。本发明方法充分考虑了电动汽车、充电站以及交通道路的复杂场景下的信息交互,以最小化时间成本、电价成本和充电失败率的多种优化目标,实现高效实时在线的电动汽车充电引导。
本文地址:https://www.jishuxx.com/zhuanli/20240822/280679.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表