一种基于深度强化学习和动作协同的目标抓取方法与系统
- 国知局
- 2024-08-30 14:26:01
本发明涉及机器人控制,特别是涉及一种基于深度强化学习和动作协同的目标抓取方法与系统。
背景技术:
1、抓取是多功能机器人任务的基础动作。研究人员提出了许多机器人抓取方法,这些方法通常利用深度学习和/或强化学习来生成抓取策略,并在无遮挡场景中表现出良好的能。然而,在现实世界的抓取场景中,物体往往是随机放置在遮挡场景中的,这给抓取动作来了困难。为了解决这个问题,许多研究者都对抓取前协同进行了研究,其中大多数方法将非理解性推动动作扩展到了动作空间。有些方法将推和抓策略结合起来进行连续操作,因为推可以帮助重新排列物体,使抓取更容易。这些方法主要针对与目标无关的抓取任务,无法根据用户的要求进行抓取。
2、面向目标的抓取旨在抓取用户指定的物体。对于遮挡的场景来说,这尤其具有挑性。这是因为仅凭部分观测数据就想准确找到并抓住目标对象并非易事。现有的目标导向抓取方法大多采用双分支q网络结构来学习推-抓协同作用,以促进在遮挡场景中的目标导向抓取。例如,xu等人将rgb-d高度图和目标分割掩码作为输入,并训练了两个独立的q网络来学习推和抓动作之间的协同作用。yu等人没有使用目标分割掩码,而是设计了一个目标相似性网络(tsn)来估计目标定位。他们还将视觉特征传入两个深度q网络,以做出推或抓的决策。li等人采用了类似的双分支深度q网络来估计q值分布,同时解耦位置和角度预测。
3、上述方法的一个重要假设是,在每个训练步骤中,机器人应选择q值较大的动作(推或抓)。然而,这一假设的可解释性较差,而且并不总是可靠的。此外,现有的大多数方法都是通过将堆叠的物体推向特定的方向来解决遮挡场景中的抓取难题,而推的动作有时不能有效地解决面向目标的抓取任务,甚至会进一步扰乱抓取场景。
4、现有的目标导向抓取方法可分为两类:无动作协同的目标导向抓取和有动作协同的目标导向抓取。
5、关于无动作协同的目标导向抓取,一些学者提出了通过单一抓取动作获取目标物体的方法。本发明将这些方法分为两阶段和一阶段。两阶段指的是目标指定和抓取检测不是融合在一起的,而是首先进行与任务无关的抓取检测,然后使用合适的启发式进行目标过滤。murali等人使用目标物体的二进制掩膜对场景点云进行裁剪,然后在目标物体点云上进行6-dof抓取检测。liri等人使用语音从物体检测结果中指定目标物体,然后将其转发给抓取检测模块。另一种方法是根据输入的目标信息以图像和语言指令的形式直接生成抓取建议,这种方法被称为单级方法,建议使用草图来表示目标对象,并设计了一个端到端网络来学习生成面向目标的抓取。yang等人设计了一种多目标密集描述器,通过drl学习目标导向的抓握能力,目标由rgb图像定义。然而,由于动作空间有限,上述方法在遮挡场景中表现不佳。在一些闭塞和杂乱的场景中,通过单一抓取动作获得目标对象几乎是不可能的。因此,有必要探索动作协同算法,以解决遮挡场景中面向目标的抓取任务。
6、关于有动作协同的目标导向抓取,许多研究探索了抓取前操作(如推和抓)的协同作用,以提高抓取目标的成功率。xu等人提出了一种目标条件分层强化学习方法,包括目标重标记策略和替代训练,以处理样本低效问题并加速训练。yang等人提出了一种基于贝叶斯的探索目标策略,以及一种基于分类器的推抓协同策略。为了解决大状态空间下的学习问题,li等人将动作空间解耦,分别学习抓取的位置和角度,即使用额外的分支来预测抓取角度。此外,一些新方法也逐渐问世。其中,zuo等人采用了基于图的深度强化学习模型代替经典的dqn来探索隐形物体,从而获得了更好的推抓协同性能。
7、目前,现有的面向目标机器人抓取的动作协同方法主要基于推和抓。然而,通过对这些方法的实验测试,本发明发现在一些常见的遮挡情况下,推抓协同并不能有效处理。首先,对于堆叠场景,智能体很难执行有效的推送动作,这是由推送动作的定义决定的。其次,对于推抓协同,在某些情况下需要多个动作步骤才能成功抓住目标物体,这非常耗时。
技术实现思路
1、为了解决现有技术的不足,本发明提供了一种基于深度强化学习和动作协同的目标抓取方法与系统,本发明通过构建三分支动作协同网络来扩展动作空间维度。此外,本发明还将方法建模为一个分层框架,以提高策略学习的效率。
2、一方面,提供了一种基于深度强化学习和动作协同的目标抓取方法;
3、一种基于深度强化学习和动作协同的目标抓取方法,包括:
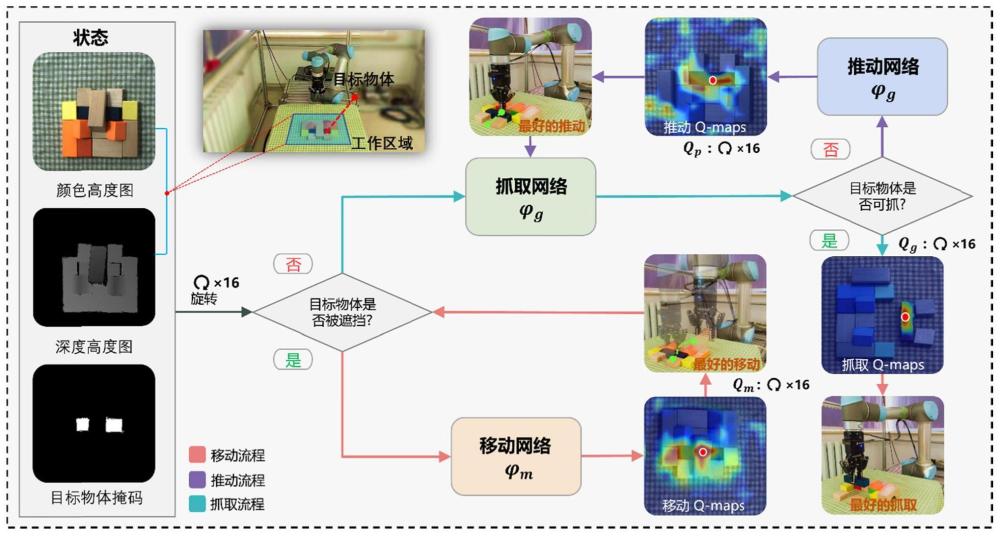
4、s101:将彩色高度图像、深度高度图像和目标物体掩膜图像作为输入图像;将输入图像输入到三分支深度q网络的第一判断模块中,判断出目标物体是否被遮挡住,如果被遮挡住,则将输入图像均输入到移动动作评价网络中,得到移动动作价值;根据移动动作价值,对机器人进行控制,以完成对目标物体的移动,进入s102;如果未被遮挡住,则进入s103;
5、s102:重复s101,直至目标物体不再被遮挡住,进入s103;
6、s103:将输入图像均输入到抓取动作评价网络中,得到抓取动作价值;根据抓取动作价值,对机器人进行控制,以完成对目标物体的抓取;
7、s104:三分支深度q网络的第二判断模块,判断物体抓取是否成功,如果抓取成功,则结束;如果抓取失败,则将输入图像均输入到推动动作评价网络中,得到推动动作价值,根据推动动作价值,对机器人进行控制,以完成对目标物体的推动;
8、s105:将推动后的目标物体图像再次输入到抓取动作评价网络中,得到抓取动作价值,根据抓取动作价值,对机器人进行控制,以完成对目标物体的抓取,返回s104。
9、另一方面,提供了一种基于深度强化学习和动作协同的目标抓取系统;
10、一种基于深度强化学习和动作协同的目标抓取系统,包括:
11、判断模块,其被配置为:将彩色高度图像、深度高度图像和目标物体掩膜图像作为输入图像;将输入图像输入到三分支深度q网络的第一判断模块中,判断出目标物体是否被遮挡住,如果被遮挡住,则将输入图像均输入到移动动作评价网络中,得到移动动作价值;根据移动动作价值,对机器人进行控制,以完成对目标物体的移动,进入重复模块;如果未被遮挡住,则进入抓取模块;
12、重复模块,其被配置为:重复判断模块,直至目标物体不再被遮挡住,进入抓取模块;
13、抓取模块,其被配置为:将输入图像均输入到抓取动作评价网络中,得到抓取动作价值;根据抓取动作价值,对机器人进行控制,以完成对目标物体的抓取;
14、第二判断模块,其被配置为:三分支深度q网络的第二判断模块,判断物体抓取是否成功,如果抓取成功,则结束;如果抓取失败,则将输入图像均输入到推动动作评价网络中,得到推动动作价值,根据推动动作价值,对机器人进行控制,以完成对目标物体的推动;
15、再抓取模块,其被配置为:将推动后的目标物体图像再次输入到抓取动作评价网络中,得到抓取动作价值,根据抓取动作价值,对机器人进行控制,以完成对目标物体的抓取,返回第二判断模块。
16、再一方面,还提供了一种电子设备,包括:
17、存储器,用于非暂时性存储计算机可读指令;以及
18、处理器,用于运行所述计算机可读指令,
19、其中,所述计算机可读指令被所述处理器运行时,执行上述第一方面所述的方法。
20、再一方面,还提供了一种存储介质,非暂时性存储计算机可读指令,其中,当非暂时性计算机可读指令由计算机执行时,执行第一方面所述方法的指令。
21、再一方面,还提供了一种计算机程序产品,包括计算机程序,所述计算机程序当在一个或多个处理器上运行的时候用于实现上述第一方面所述的方法。
22、上述技术方案具有如下优点或有益效果:
23、(1)本发明提出了一种新颖的三分支深度q网络,即mpgnet,它可以学习移动、推动和抓取动作之间的协同,从而在隐蔽场景中实现面向目标的抓取。据本发明所知,所提出的方法是第一种通过移动、推动和抓取动作的协同作用来解决模糊场景中面向目标抓取这一具有挑战性任务的方法。
24、(2)本发明设计了一种多阶段训练mpgnet的策略,即先对每个动作进行单独训练,然后再进行联合训练,以有效地学习移动-推-抓的协同。
25、(3)本发明在仿真环境中进行了大量实验来评估mpgnet,并进一步证明了真实世界中的机器人系统能够在遮挡场景中可靠地完成面向目标的抓取任务。
本文地址:https://www.jishuxx.com/zhuanli/20240830/281981.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表