基于周期最优路径比较的分布式光伏异常数据检测方法与流程
- 国知局
- 2024-08-30 14:35:27
本发明涉及分布式光伏异常检测领域,是一种基于周期最优路径比较的分布式光伏异常数据检测方法。
背景技术:
1、近年来,光伏风电资源产业规模及应用逐步扩大,技术迭代不断更新,太阳电池产业化发展,产业链各环节成本稳步下降,光伏相关技术飞速发展。然而,大量可控负荷和分布式电源本身具有的波动性,其接入电网后对传统配电网单端供电辐射状拓扑结构的改变,为配电网的运行带来了更多不确定性问题,也易受网络攻击而引起配电网信息物理系统不安全运行。目前,在数据异常检测方面已有大量报导,但针对于高比例分布式电源的数据异常检测仍有待于学习研究。首先高比例新能源蓬勃发展,其本身具有的随机性和波动性导致针对于旧有电力网的算法无法准确识别和处理所有的异常情况。其次现有电力数据异常检测相关文献大多只针对配电网,而在高比例分布式电源接入的情况下电力系统处理的数据量急剧增加,因此准确、高效的处理分布式电源接入下的电力系统异常检测数据至关重要。最后,分布式光伏发电数据是典型的时序数据,以等间隔的时间序列形式存储,在对其进行异常检测时必须要考虑到其时序特征,而部分文献构建算法时往往忽略掉了其时序特征。综上,开展高比例新能源下的分布式光伏工控网络异常数据检测方法研究具有十分重要的意义。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种科学合理,实用性强,监测结果准确、可靠,能够智能化,保护电网安全运行的基于周期最优路径比较的分布式光伏异常数据检测方法。
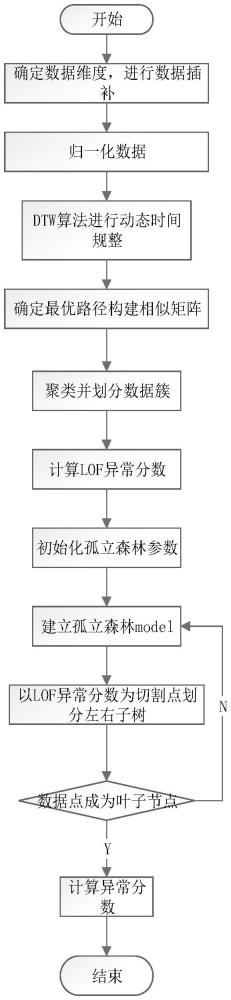
2、本发明所采用的技术方案是:一种基于周期最优路径比较的分布式光伏异常数据检测方法,其特征是,包括:
3、数据预处理,对光伏的运行数据进行清洗,选定合适的特征进行标准化处理,划分组数;
4、基于dtw周期最优路径比较的最优距离计算,使用dtw对每组数据进行线性的时间对齐,以找到它们之间的最佳匹配,获取最优距离矩阵;以最优路径为特征划分相似组,并基于k-means进行数据聚类;
5、基于lof-iforest的分布式光伏异常数据检测,利用lof计算每个数据点的局部离群因子,获取lof异常分数,将其作为iforest选择的随机分割点,以此划分左右子树,构建完整的二叉树,以数据点在树中的路径长度计算异常分数值。
6、进一步地,所述数据预处理具体过程为,
7、定义原始光伏输出数据为
8、x=[x1 x2 x3 λ xn1] (1)
9、式中,x表示光伏输出数据,其中包括电流、电压、功率、温度、辐射度、压强、风力、湿度,n1表示数据对象的维数,以15分钟或30分钟级别光伏输出数据,全天共采集96个或48个负荷数据;
10、将光伏的负荷数据导入matlab绘制图观察数据结构,可知光伏输出功率与辐射度具有近似的线性关系,选择光伏输出功率与辐射度作为训练数据,更新式(1)为:
11、
12、式中,x表示光伏输出数据,xr为辐射度,xp为光伏输出功率;
13、然后进行数据插补。
14、进一步地,所述数据插补具体过程为,
15、按照一天采集的多点的数据量划分组别,以方便计算,采用拉格朗日插值方法对负荷数据进行填补;
16、将原函数数据定义为f(x)函数,在插值点的附近选取给定的n2个节点,格式为(xi,yi)构造一个简单的n次多项式函数n(x),使得对于任意的i,都有n(xi)=yi成立;
17、根据已有给定取值点,求每个取值点对应的牛顿插值多项式n(x);其对应的表达式为:
18、
19、根据已知的n2个取值点,求出的取值点对应的牛顿插值,其误差表达式为:
20、r(x)=f[x0,x1,λ,xn]πn(x-xi) (4)
21、构造牛顿插值多项式后即可对指定数据进行插值;
22、光伏输出数据完成数据填补后行归一化处理,采用z-score归一化,其公式如下:
23、
24、式中,xnorm为归一化后的数据,x为原始数据,xmean为原始数据的均值、xstd为原始数据集的标准差。
25、进一步地,所述基于dtw周期最优路径比较的最优距离计算,使用dtw对每组数据进行线性的时间对齐,以找到它们之间的最佳匹配,获取最优距离矩阵的具体过程为,
26、所述光伏输出数据xnorm,其组数计n3,每组数据共m个,则光伏输出数据表示为:
27、
28、以xnorm每一行为首要判断对象,查询光伏输出数据的空值区间并截取实值区间,将每组数据即xnorm中的每一列实值区间作为一个新的实值时序序列;
29、采用dtw算法进行动态时间规整,时间规整和距离规整,其中时间规整是将输入的两个序列长度拉伸压缩一致为止;距离规整就是将复杂全局优化问题转化为若干个局部最优问题后再进行决策,以此确定最优路径;
30、将截取的实值序列定义为pi和qi,i=1,2,…n4,采用欧式距离构建序列之间的距离矩阵d;在矩阵d中,找到一条由左下角到右上角或右上角到左下角的路径,该路径所通过的元素值之和为最小,即求解规整路径w可表示为:
31、w=w{w1,w2,w3,…,wk}(7)
32、式中,wk=(i,j)k表示两个序列中第i个点和第j个点的对应距离;
33、根据规整路径w可求解2个序列的累积距离d,,最终找到一条最优规整路径w,使得累积距离最小,即
34、dmin=∑d′(i,j)(8)
35、计算出每个序列与其他序列的累计距离之后,将累计距离转换为一个相似度矩阵ds,基于相似矩阵进行聚类;
36、进一步地,所述以最优路径为特征划分相似组,并基于k-means进行数据聚类的具体过程为,
37、对于相似度矩阵ds,选取初始聚类中心,对数据集x中每个数据xi定义其密度值density(xi),并将xi按照其密度值的大小从小到大依次排列;其中,密度值density(xi)的定义为:
38、
39、选择密度值最小的数据,并计算其到其他数据的欧式距离d(xi,xj);
40、定义对象的m邻域,其定义为xi以m倍的r为半径的圆,与m-1倍的r为半径的圆所围成的环形区域所包含的数据,表示为:
41、δm={xj|(m-1)×r<d(xi,xj)<m×r}
42、 (10)
43、式中,m=1,2…,mmax,j=1,2…,n6;
44、
45、将xmin的m邻域中的数据进行降序排列,并根据所包含样本的数量,选取包含数量最多的前k个邻域δl,l=1,2…,k;
46、选取δl中密度最小的k个数据对象,将这k个对象作为选取的初始聚类中心;根据传统k-means算法计算误差平方和函数,并不断更新聚类中心,找到最优解,
47、得到k个聚类后的数据簇di,i=1,2,…,k。
48、进一步地,所述基于lof-iforest的分布式光伏异常数据检测,利用lof计算每个数据点的局部离群因子,获取lof异常分数,具体过程是:
49、基于收集到聚类后的数据簇,对每一簇的数据di,i=1,2,…,k分别进行异常值的检测;
50、设置初始孤立树数量n,子采样大小为256,构建孤立森林框架进而构建孤立树框架,并计算lof异常分数;
51、设簇di,i=1,2,…,k中计算点为p,k最近邻的最大距离表示为k_dist,计算k距离邻域:
52、nk_dist(p)={q|p∈d∩d(p,q)≤k_dist(p)} (12)
53、式中,点q为点p的k近邻对象,d为数据簇,k_dist(p)为指点p到它的k最近邻的最大距离;
54、再计算点p关于点o的可达距离:
55、r_dist(p,o)=max{k_dist(o),dist(p,q)}(13)
56、式中,点o为点p的当前计算对象,k_dist(p)为指点p到它的k最近邻的最大距离,dist(p,q)示数据点p到数据点q的欧式距离;
57、最后计算数据点的局部可达密度:
58、
59、式中,nk_dist(p)是点p的k邻域中的对象集合,r_dist(p,o)是点p关于点o的可达距离;
60、基于公式(12)-(14),计算局部异常因子:
61、
62、式中,lrd(p)为数据点p的局部可达密度,lrd(o)为数据点o的局部可达密度,nk_dist(p)是点p的k邻域中的对象集合;
63、基于公式(12)-(15),完成各簇内的lof异常分数计算,并标记异常分数较高的点的索引;
64、进一步地,所述将获取lof异常分数作为iforest选择的随机分割点,以此划分左右子树,构建完整的二叉树,以数据点在树中的路径长度计算异常分数值的具体过程为,
65、从数据集中随机选择特征,并随机选择lof异常分数较高的点作为孤立森林中建立的树的切割点,将数据点划分到左右两个子树,继续递归建立树,直到每个数据点都成为叶子节点,构建多棵树,形成孤立森林;
66、对于给定的数据点,计算它在孤立树中的路径长度。路径长度表示从根节点到数据点所经过的分割步骤次数;通过式(16)计算多棵孤立树中的路径长度平均值,得到数据点的异常分数:
67、s(x,t)=2-e(h(x))/c(t) (16)
68、式中,e(h(x))为单个数据点xi在所有树中达到深度的平均值,c(t)为归一化因子,为在一个二叉搜索树中不成功搜索的平均深度:
69、c(t)=2h(t-1)-(2(t-1)/t)
70、=2[ln(t-1)+0.5772156649]-2(t-1)/t(17)
71、式中,h(i)为谐波数,由欧拉常数估计,t为构造树的点数;
72、标记真实离群点被正确检测为离群点(tp)、真实正常点被正确检测为正常点(tn)、真实正常点被错误检测为离群点(fp)以及真实离群点被错误检测为正常点(fn),选用精确率(p)、召回率(r)、f1以及准确率a这4个指标来评估模型的测试性能:
73、
74、本发明的一种基于周期最优路径比较的分布式光伏异常数据检测方法的有益效果是:
75、(1)基于周期最优路径比较的数据聚类,能够适应不同规模和复杂度的光伏系统数据,加快异常检测的速度和响应时间,在进行异常检测时更加精确、快速,可靠性更高,检测精度更好;
76、(2)基于lof-iforest的数据异常检测方法,提升光伏数据的监测识别准确率,减少误报和漏报的情况,从而降低对光伏系统运行的干扰和风险,促进数据异常检测的深度挖掘与应用;
77、(3)在考虑光伏数据时序特征的基础上进行异常检测,可以更好地捕捉到时间相关性的变化模式,提取数据中隐藏的规律和模式,发现和识别周期性异常,从而提高异常检测的准确性,证明其检测的有效性。
本文地址:https://www.jishuxx.com/zhuanli/20240830/282866.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表