一种基于GNN和DRL的组合设备调度优化方法
- 国知局
- 2024-08-30 14:38:58
本发明涉及半导体加工的,尤其是指一种基于gnn和drl的组合设备调度优化方法。
背景技术:
1、随着电子信息行业的迅速发展,半导体行业正经历着高速增长。半导体制造涵盖了晶圆的生产、加工和测试等阶段。在这个过程中,组合设备被广泛应用于各种半导体制造工艺,包括光刻、刻蚀和化学气相沉积等。
2、在组合设备中,从装载锁卸载的晶片在多个处理模块中经过一系列处理步骤,最终在完成后返回装载锁。通常情况下,一批晶圆(25个)按照预定流程依次访问处理模块。每个晶圆的访问顺序就是该晶圆在组合设备中的加工路线。由于产品定制和小批量晶圆的趋势,需要集群工具同时处理多种类型的晶圆。
3、目前,晶圆的直径已经从200毫米增加到300毫米,甚至达到450毫米。尤其是由于集成电路制造技术的迅猛进展,电路宽度不断减小至14-22纳米,甚至最近降至10纳米以下,使得一个晶圆可以容纳更多的芯片。批次规模往往显著减小,甚至降至5-8。随着消费需求的多样化和个性化导致晶圆批次规模的减小,这使得制造商希望一条生产线可以同时生产多种类型的晶圆。然而,这面临两个重大挑战:(a)不同类型的晶圆需要不同的加工路线,这就要求算法具有很强的通用性,以便在同一条生产线上组合不同类型的晶圆;(b)批量晶圆的生产必须完成所有晶圆的加工。而目前基于人工设计的多项式时间复杂度的算法很大程度依赖于人工经验,当面对多种晶圆类型时一些条件的改变很难快速设计出新的合适的多项式时间复杂度的算法。因此自动学习解决组合设备加工多品种晶圆问题具有重要意义。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供了一种基于gnn和drl的组合设备调度优化方法,可实现对组合设备晶圆加工的有效调度。
2、为实现上述目的,本发明所提供的技术方案为:一种基于gnn和drl的组合设备调度优化方法,包括以下步骤:
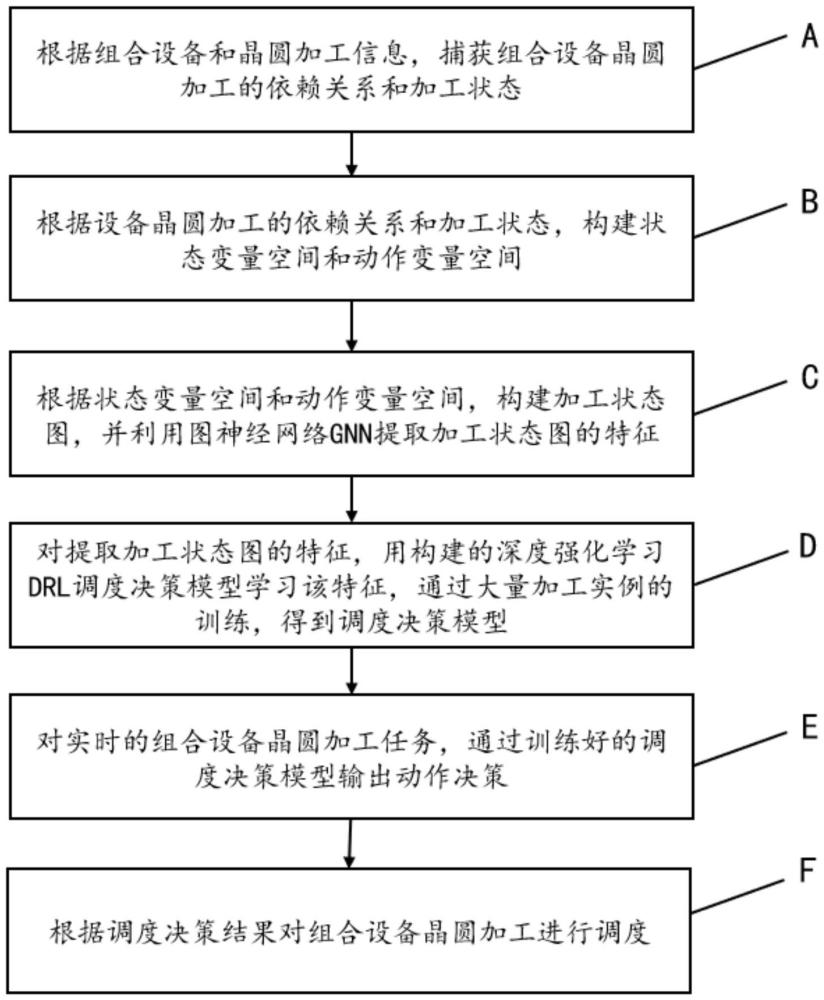
3、1)根据组合设备和晶圆加工信息,捕获组合设备晶圆加工的依赖关系和加工状态;
4、2)根据组合设备晶圆加工的依赖关系和加工状态,构建状态变量空间和动作变量空间;
5、3)根据状态变量空间和动作变量空间,构建加工状态图,并利用图神经网络gnn提取加工状态图的特征;
6、4)对提取加工状态图的特征,用构建的深度强化学习drl调度决策模型学习该特征,通过大量加工实例的训练,得到训练好的drl调度决策模型;
7、5)对实时的组合设备晶圆加工任务,通过训练好的drl调度决策模型输出动作决策,即调度决策结果;
8、6)根据调度决策结果对组合设备晶圆加工进行调度。
9、进一步,在步骤1)中,所述依赖关系包括每种晶圆类型对应的加工路线γ和加工路线对应组合设备中的加工模块pm,假设有第k个晶圆,其有l个加工步骤,即对应加工路线长度为l,则第k个晶圆加工路线γk表示如下:
10、γk=[γk,1,γk,2,γk,3,…,γk,l]
11、式中,γk,l代表第l个加工步骤;
12、每个加工路线中的加工步骤都对应一个加工模块,γk,l对应为第m个加工模块pmm,则有γk,l=pmm;
13、所述加工状态包括组合设备加工模块和机械臂占用情况,其中加工模块每次同时只能加工一枚晶圆,当该枚晶圆加工完成后且被机械臂搬运至下一加工模块后,才能够加工新的晶圆,机械臂每次同时每次只能搬运一枚晶圆,完成一枚晶圆的搬运后,才能够对下一枚晶圆进行搬运。
14、进一步,在步骤2)中,所述状态变量空间包括晶圆数量n,每个晶圆对应加工路线长度为l,在构建矩阵时,矩阵每行表示同一种晶圆,每列表示对应行晶圆加工路线中的一个加工步骤,即对于第i行第j列的γi,j表示第i个晶圆的第j步加工步骤,其中i∈n,j∈l,则待加工矩阵p满足:
15、
16、式中,γn,l表示第n个晶圆的第l步加工步骤;
17、所述状态变量空间还包括每个加工模块的加工时间α、机械臂移动时间μ和装或卸载晶圆时间β,每次搬运晶圆需要机械臂移动到晶圆加工完成的加工模块,然后卸载晶圆,并搬运晶圆至下一加工模块,并将其装载进入下一加工模块,下一模块进行加工,则对应任务时长п计算满足如下:
18、п=2·(μ+β)+α
19、对于矩阵p,每个待加工晶圆步骤都对应相应的任务时长п,在构建矩阵时,矩阵每行表示同一种晶圆,每列表示对应行晶圆加工步骤对应的加工时长,即对于第i行第j列的пi,j表示第i个晶圆的第j步加工步骤的加工时长,则任务时长矩阵r表示为:
20、
21、式中,пn,l表示第n个晶圆的第l步加工步骤的加工时长;
22、所述动作变量空间包括选择候选待加工晶圆步骤,总决策步骤数量s满足s=l×n,对于每个步骤t∈s中的操作是在决策步骤t中的合格操作。
23、进一步,在步骤3)中,用图神经网络gnn学习图特征,对其中图的节点集v=s,边集e即为已决策加工的节点集的连接弧,则对于节点x满足x∈v时,第y次的多层感知机迭代后的结果表示如下:
24、
25、式中,表示第y-1次迭代结果,∈(y)表示第y次迭代可学习的参数,n(x)表示节点x的邻接节点集,并计算全部邻接节点的情况在最终迭代后输出加工状态图的特征。
26、进一步,在步骤4)中,构建的drl调度决策模型包含策略网络和价值网络,所述策略网络用于确定在当前状态下应该采取的动作,在训练过程中,所述策略网络通过最小化总加工时间来调整这些动作的概率分布;所述价值网络用于评估状态的价值,即在给定状态下预期能够获得的长期回报,以便在强化学习中帮助决策。
27、进一步,在步骤4)中,构建的drl调度决策模型的马尔可夫决策过程如下:
28、状态:对于每个步骤t,包括已加工步骤lf以及未加工步骤lw,则当前状态加工状态图g(t)表示为g(t)=(s,lf,lw);当lf为空集时,表示刚开始加工,当lw为空集时,表示已完成加工;对于每个加工步骤,计算其选择后对应的完成时间,假设在步骤t选择第i个晶圆的第j个加工步骤γi,j,则对应加工模块的完工时间pm(γi,j)加上对应的任务时长пi,j实现对pm(γi,j)的更新,即为pm(γi,j)=pm(γi,j)+пi,j;
29、动作:对于步骤t,因为晶圆加工其有固定工艺,连续的工艺对应晶圆的加工路线,只有当前序步骤加工完成才能够进行后一个加工步骤的加工,因此每次决策需要选出合格操作at,其中每个晶圆在步骤t时最多只能有一个晶圆工艺步骤被选择,并且随着越来越多的步骤完成,at会变得越来越小;
30、状态转移:对于步骤t,每次选择合格操作at后,对g(t)=(s,lf,lw)进行更新,重复动作选择过程,直到完成加工;
31、奖励:奖励目标是最小化完工时间,因此在步骤t决策合格操作at时,根据当前加工模块的完工时间pm(at-1)以及选取at后的完工时间pm(at),计算选取每个合格操作的奖励rt(at),为rt(at)=pm(at)-pm(at-1),rt(at)越小意味着当前步骤选择该操作的完工时间最小,即最小化该奖励;
32、策略:对于步骤t的当前状态加工状态图g(t),随机策略θ(g(t))输出合格操作at的动作概率分布p(at)。
33、进一步,在步骤5)中,对实时的组合设备晶圆加工任务,以最小化完工时间为目标,通过gnn提取当前状态图特征,drl调度决策模型输出策略θ(g(t))和动作概率分布p(at),根据该策略θ(g(t))和动作概率分布p(at)进行加工调度。
34、本发明与现有技术相比,具有如下优点与有益效果:
35、1、本发明通过捕获组合设备加工状态之间的依赖关系,能够更好地理解设备加工过程中的动态变化。这有助于更准确地预测加工状态的变化和设备之间的互动,从而提高调度决策的效果。
36、2、本发明利用图神经网络(gnn)提取加工状态图的特征,能够有效地将图形结构中的信息转化为可供深度学习模型理解的形式。这有助于提高模型对加工状态图的理解能力,从而更好地进行决策。
37、3、本发明的深度强化学习(drl)可以根据环境的反馈自主地学习并调整决策策略,从而适应不同的组合设备加工实例。这意味着模型可以处理各种规模和复杂度的加工问题,并在训练过程中不断改进性能。
38、4、本发明通过训练好的drl调度决策模型,对新的加工实例进行自动决策调度,实现了对组合设备对晶圆的加工的自动化管理。这可以大大减轻人工干预的工作量,提高加工效率和组合设备加工模块的利用率
本文地址:https://www.jishuxx.com/zhuanli/20240830/283155.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。