一种基于对比示例学习框架的发电机组典型设备运维知识智能提取方法
- 国知局
- 2024-08-30 15:03:56
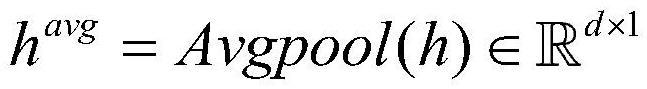
本发明属于设备运维和人工智能,具体涉及一种基于对比示例学习框架的发电机组典型设备运维知识智能提取方法。
背景技术:
1、随着能源需求的不断增长和电力系统规模的扩大,传统的发电机组典型设备运维面临着越来越大的挑战,为了应对这些挑战,发电机组典型设备智能运维逐渐引起人们的关注。智能化运维是指利用先进的信息技术和人工智能等手段,对电力系统的运维过程进行自动化、智能化和高效化的管理和控制。其目标是通过设备实时在线监测、数据预处理、故障诊断和预测技术,实现对发电机组典型设备和系统状态的全面感知、分析和管理,进一步提高电力系统的可靠性、安全性和经济性。
2、知识图谱作为人工智能的基础性技术,具有极强的数据表达能力和建模灵活性,尤其擅长处理关系密集型数据。通过建模数据与数据之间的关联关系,可有效组织碎片化的数据,使分散的数据得到更充分地利用。知识的获取将直接决定输出的准确性,而命名实体识别技术决定知识获取的可靠性。通过将发电机组典型设备的关键信息、历史数据和专业知识以三元组的形式进行整合,使得运维智能决策模型更具有上下文感知能力,提升决策的准确性和适用性。
3、从原始的领域数据到形成高质量知识图谱,需要经过知识抽取、知识融合与知识加工等多个步骤,其中知识抽取是整个过程中的关键环节。目前,实体-关系抽取方法分为流水线法和联合抽取法两大类。流水线法将实体关系抽取分解为实体识别和关系抽取两个独立的子任务,该方法易于实现且灵活性高,但是将实体识别和关系抽取分开处理容易忽视二者之间的联系。此外,实体识别产生的错误会传递到关系分类模型中,进而影响关系抽取的性能。联合抽取法可以有效整合实体和关系信息,从而提高知识抽取性能,但不能有效处理重叠三元组的问题。
4、因此,如何有效提取实体-关系对于发电机组典型设备智能运维发展具有重要作用。为了能够充分挖掘大规模运维文本中蕴含的实体关系知识,减小传统实体关系联合抽取方法引起的误差,本文设计了一种基于对比示例学习框架的发电机组典型设备运维知识智能提取方法,用于从电力系统非结构化数据中自动和同步提取实体和关系,以准确识别实体,从训练集有限的检修相关文档中提取关系,减少错误的传播。
技术实现思路
1、鉴于以上存在的技术问题,本发明提供一种基于对比示例学习框架的发电机组典型设备运维知识智能提取方法,针对发电机组典型设备大规模运维文本数据,快速准确地提取数据蕴含的实体知识和潜在关系。
2、为解决上述技术问题,本发明采用如下的技术方案。
3、一种基于对比示例学习框架的发电机组典型设备运维知识智能提取方法,包括以下步骤:
4、s1、在发电机组典型设备大规模运维文本的基础上,采用数据增强策略对运维文本进行处理,设计运维文本正样本和负样本的生成策略,提高实体关系抽取模型信息提取的准确性和快速性;
5、s2、根据s1生成的运维文本正样本和负样本,采用编码器从样本数据中提取文本特征向量;
6、s3、结合步骤s2提取的特征向量,结合prgc(potential relation and globalcorrespondence based joint relational triple extraction,基于潜在关系和全局对应的联合关系三元组提取)与对比学习,将运维文本的特征映射至对比损失空间,构建发电机组典型设备运维知识提取模型;
7、s4、基于s3构建的发电机组典型设备运维知识提取模型,设置相应的损失函数,采用正样本训练发电机组典型设备运维知识提取模型,使其学习正样本中蕴含的特征向量,并将负样本数据分离至潜在空间;
8、s5、采用s4训练得到的模型,对发电机组典型设备运维知识进行实体-关系联合抽取,得到运维知识中包含的实体对与相对应的关系。
9、进一步地,步骤s1包括以下分步骤:
10、s11、通过翻译工具将发电机组典型设备大规模运维文本翻译成英文,再将英文翻译中文,从而将原运维文本表达成新的句式,在原运维文本的基础上扩展正样本;
11、s12、在大规模运维文本的基础上,随机替换单句文本中两个名词为同义词,对文本进行形式上的扩展;
12、s13、采用随机掩码的思路,随机掩盖运维文本中五分之一的词语,在内容上进行裁剪,从而生成新的正样本;
13、s14、设计一个与发电机组典型设备大规模运维文本中实体相关的负样本生成策略,以发电机组典型设备安全报告为标准,生成负样本。
14、进一步地,步骤s2包括以下分步骤:
15、s21、采用prgc的bert编码器对文本进行处理,采用bert将输入文本转换成由token embedding、segment embedding和position embedding三部分组成的字向量;
16、s22、segment embedding部分识别不同的标志符号,对文本中的句子进行区分;
17、s23、初始化一个position embedding模块,通过对其进行训练,从而识别出文本中实体的位置;
18、s24、利用bert的三个模块,提取设备运维样本中的字特征向量,用于后续提取三元组和优化实体关系抽取模型。
19、进一步地,步骤s3包括以下分步骤:
20、s31、根据s2提取的文本特征向量,将bert编码器的输出传输至prgc模型和对比损失空间两个部分;
21、s32、其中,bert输出的特征向量一方面用来计算h[cls]对比损失值,并将bert编码器嵌入至prgc模型中,为后续模型的实体-关系联合抽取提供理论基础;
22、s33、bert输出的特征向量另一方面以对比损失函数值为标准,调整bert编码器的超参来影响三元组的提取;
23、s34、基于步骤s32的prgc模型,结合步骤s33的对比学习部分对模型进行优化,建立cl-prgc(contrastive learning-prgc)模型,完成发电机组典型设备运维知识提取模型的构建。
24、更进一步地,步骤s34包括以下分步骤:
25、s341、将s2得到文本特征向量输入至prgc的潜在关系预测部分,提取所有可能存在关系并进行权重分析,选取大于阈值的关系为候选关系;
26、s342、同时,将文本特征向量输入至框架中的主宾语对齐矩阵中,对不同候选关系进行概率预测,确定整个实体,并完成头尾实体首词的匹配;
27、s343、将s2提取的文本特征向量和s321生成的候选关系输入至框架的实体提取部分,该部分利用两个特定关系的序列标签组件来分别提取主体和客体,以处理主客体重叠问题;
28、s3444、列举所有预测的实体对,采用全局对应矩阵并优化组合目标函数,共享prgc编码器参数,构建实体-关系联合抽取的cl-prgc模型。
29、进一步地,步骤s4包括以下分步骤:
30、s41、构建对比损失函数并应用于训练bert编码器的参数,将正样本与负样本的差异性进一步扩大;
31、s42、构建三重提取损失函数,训练bert编码器和prgc模型的参数,进一步提升发电机组典型设备运维知识的提取能力。
32、采用本发明具有如下的有益效果:
33、该设计方法针对发电机组典型设备运维知识规模大、实体与关系抽取可靠性难以保证的问题,在大规模发电机组典型设备运维文本的基础上,结合对比学习与实体关系联合抽取模型,在扩展运维文本正样本和负样本的基础上,提高实体与关系匹配的准确性,有效提升实体和关系抽取速率,为实体-关系的高效抽取提供了一个有效的方法思路。
本文地址:https://www.jishuxx.com/zhuanli/20240830/285347.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表