基于非结构化彩色点云的大型城市场景表面与纹理重建
- 国知局
- 2024-09-05 14:25:57
本发明属于地理信息加工服务,具体涉及基于非结构化彩色点云的大型城市场景表面与纹理重建。
背景技术:
1、随着深度传感器以及激光扫描技术的快速发展,实现了多视角、多平台、多分辨率的数据采集,人们可以更加容易地获取大量高精度点云数据。这些点云数据可以更加立体、直观地展现真实地理空间,能够同步获取几何和纹理信息,极大地推动了真实地理场景三维表达与感知技术的发展。同时,随着计算机视觉与深度学习技术的日益成熟,三维数据成为了包括自动驾驶、虚拟现实、机器人导航等应用研究的首选数据类型。常见的三维类型数据有三维点云、三维网格、三维体素、多视角图像等。其中,高质量三维表面网格是一种重要的数据产品,但这种三维数据通常难以通过传感器直接获取,因此由更易直接获取的三维点云数据转化为三维表面网格成为了当下主流的三维视觉处理任务之一。
2、中国专利cn112489202a一种基于多视角深度学习的路面宏观纹理重建方法。采集路面多视角图像和路面宏观纹理三维点云数据作为路面信息数据集;建立基于单视角路面图像的深度学习结构s,用于基于单一视角图像的路面宏观纹理重建;建立多视角融合单元mu,用于融合基于不同路面视角图像的路面宏观纹理重建模型;使用路面信息数据集对深度学习结构s和多视角融合单元mu进行端对端训练,获得训练完成的多视角深度学习结构;采用训练完成的多视角深度学习结构生成待检测沥青路面区域的宏观纹理模型。但是上述专利需要采集多视角图像和路面宏观纹理三维点云数据,这需要大量的时间和精力,而且可能受到天气、光照等因素的影响,导致数据质量不稳定,同时模型复杂度高,该专利涉及到多个深度学习模型和融合单元,需要大量的计算资源和时间进行训练和优化,同时需要人工参与模型的调整和优化,成本较高。
3、中国专利cn117745967a公开了基于神经辐射场的精细纹理地图的实时建图方法及系统,方法包括:首先通过激光雷达输入场景深度信息,通过相机输入场景纹理信息,以及获取设备状态量,构建输入数据集;对所述输入数据集进行点云去畸变后输入slam算法中;输入数据集经过处理后得到目标数据;然后通过光流跟踪判断方法对目标数据进行关键帧插入,并将部分稀疏深度图片采样的光线存入关键帧数据库中;最后经过外参细化和逆仿射纹理重建策略对颜色进行针对性细化后,进行隐式神经建图得到有精细纹理的地图,本发明能够提升基于外参优化对长时间大尺度测量的纹理清晰度,并且在对目标对象的实时重建中能够尽可能避免光照变换影响,可广泛应用于地图构建技术领域。但是,神经辐射场建图方法需要实时处理地图上的大量数据,这可能会对硬件性能提出较高的要求,如较高的计算能力和内存容量,从而限制了其在一些设备上的应用,同时在精度问题:神经辐射场建图方法主要依赖于神经网络的训练和优化,如果训练数据的质量和数量不足,可能会导致建图精度下降。
4、因此上述专利无法对古建筑、文物保护和城市三维建筑等领域的高质量的表面和纹理重建发挥作用。由于点云数据已成为表达三维空间信息的重要手段,因此利用点云数据进行表面重建和纹理重建非常重要。
5、随着技术的发展,卷积占用网络被提出,作为一种体积表示方法,该方法不能捕获全局形状信息,且基于体积的表示对于3d数据生成仍然需要存储器,这使得数据存储不便。对于上面的技术缺陷,一种从输入点云重构曲面网格的技术诞生,采用一种利用自先验来检测自相似性的方法。
6、但是,该方法有其局限性,仅适用于水密和简单的模型,需要一个初始网格模型,对于具有复杂结构的小物体,它也需要相当多的训练时间来收敛,而不能收敛到精确的结果。
7、针对于上述技术的不足,在初始网络中引入了一种2d-3d联合自先验重建方法,但仅适用于水密的小物体,不适用于大型场景重建。此外,迭代优化过程相对复杂和耗时,纹理恢复的质量也受到自先验迭代次数的限制。
8、对于上述的缺点,引入了一种基于双轮廓(dc)的数据驱动网格重建方法。这种纯数据驱动的方法不能处理数据丢失,而且对噪声很敏感。这可能会导致重建结果中存在空隙和异常表面。此外,在给定的大型场景的非结构化点云中,模拟mvs方法从多个角度观察点云,得到多视图虚拟视图。良好的虚拟视图应具有以下特征:视图中投影点的密度适中,占一定比例,点云被多视图综合覆盖。这种虚拟视图采样过程通常用于计算机视觉领域各种研究。然而,这种方法通常只适用于特定的场景,而不是通用的。
9、综上所述,基于深度学习的室内外场景重建任务主要面临三大挑战,第一:由三维点云非结构化及无序性的本质特点造成,这样的数据特点使模型在提取有用的特征信息变得非常困难;第二:室外场景点云数据集通常具有庞大的点数和广泛的空间范围,而计算机难以同时处理数量与体积庞大的点云数据,因此造成不能扩展到室外大场景中使用的弊端;第三:由于室外场景的尺度不同以及训练数据集的影响,模型容易出现低泛化性问题。
技术实现思路
1、为解决上述问题,本发明设计了基于非结构化彩色点云的大型城市场景表面与纹理重建。
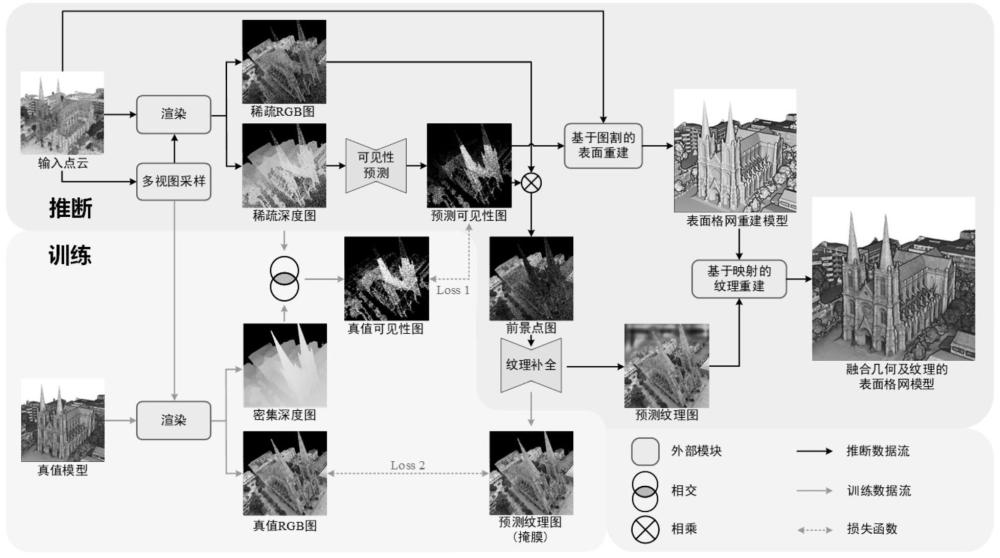
2、基于非结构化彩色点云的大型城市场景表面与纹理重建,其特征在于,包括以下步骤:
3、步骤s1:输入点云,进行多视虚拟视点选择,对视点进行渲染;
4、步骤s2:构建可见性预测网络,设计“u”型网络框架;
5、步骤s3:构建纹理修复网络;
6、步骤s4:表面重建与纹理重建。
7、优选的,所述步骤s1中的多视虚拟视点选择,首先通过指定叶节点包含点的个数,将空间进行划分,构建八叉树;其次,设置初始虚拟视点位置位于八叉树中不同深度的子节点以及根节点的中心位置,为了优化这些视点位置,将位于建筑物内部与距离地面较远的视点位置进行去除;然后,通过在每个视点位置添加一组预先设置的姿态来获得初始虚拟视点;最后,采用筛选策略有选择地细化视角,得到最终的虚拟视点。
8、优选的,所述虚拟视点的选择,通过一种鲁棒的视点选择的策略,为每个虚拟视点进行打分,并最终选择分数最高的虚拟视点作为最终选择;将初始虚拟视点作为渲染点云的参数,得到初始虚拟视图;通过隐藏点去除算法计算每个虚拟视图的粗略可见性,从而识别每个虚拟视图内的前景点pfore;利用下面提供的公式,计算sfv,它表示前景点pfore占有效像素pvalid的比例,sfa表示前景点占图像整体像素的比例;最后,通过适当的加权计算每个虚拟视点的综合得分,记为sview;
9、
10、
11、sview=λfvsfv+λfasfa。
12、其中,sum(pfore)和sum(pvalid)分别表示虚拟视图中前景点的个数和有效像素的个数;w、h分别表示虚拟视图的宽度和高度;而λfv和λfa表示权重系数;对于每个视点位置,选择两个分数最高的虚拟视点,从而获得一组虚拟视点;将所有上述未被选中的虚拟视点进行排序,并选择一定数目的高分视点,得到一组视点;这两个集合共同组成最终用于执行重建任务的虚拟视点集,记为vfinal;最终,利用opengl渲染器在每个虚拟视点上进行渲染,得到输入点云的稀疏深度图与稀疏rgb图。
13、优选的,所述“u”型网络采用全局特征融合模块gff和多尺度特征融合模块设计。
14、优选的,所述“u”型网络的全局特征融合模块分为两个分支:上方的卷积分支和下方的注意力分支;在卷积分支中,通过卷积操作从输入特征图中提取局部特征xconv;在下层分支中,通过计算全局注意力权重得到全局特征xatt,然后与局部特征、输入特征x和上层特征xupper进行集成,形成最终的聚合特征xca;因此,该模块可以使用较少的参数捕获局部和全局信息,在空间和通道维度上产生显著的特征,从而在稀疏图像分类中获得了较高的精度和有效性,公式如下:
15、
16、其中,表示拼接操作;
17、所述gff模块中的卷积分支由几个步长为1的卷积块堆叠而成;每个卷积块包含一个卷积层、一个批归一化层和relu(rectified linear unit)层;两个卷积的输入和输出通道数量保持在512不变,该设计有效地捕获了输入图像中的局部特征;
18、所述注意力分支中,采用类似于mobilevit模块的设计来进行全局特征提取;标准卷积通常可以分解为三个部分:展开、用于学习局部表示的矩阵乘法和折叠;在注意力结构设计中,采用了类似卷积的设计;所述卷积中的矩阵乘法利用多个transformer堆栈替代,从而能够获得全局特征;因此,该设计在提取全局特征时表现出类似卷积的特性,同时保留了卷积的优势。
19、优选的,所述“u”型网络的多尺度特征融合模块,通过引入多尺度特征融合,形成多层多尺度连接;在相隔的编码、解码块之间进行跨尺度的连接,使用线性投影进行维度变换,使其维度一致,将其与学习到的残差进行拼接,利用线性变换将两种特征融合,得到多层多尺度特征编码。
20、优选的,所述纹理修复网络的设计采用“u”型网络设计,在网络构建中对图像修复任务包含待修复的图像,也包含代表整个待修复区域的二值掩码;在编码器-解码器网络中使用了更大的深度来增强纹理修复网络的性能。
21、优选的,所述纹理修复网络结合加权重建损失、总变差损失、感知损失和风格损失来训练;所述纹理修复网络采用这些损失进行加权求和作为最终的图像修复损失函数;
22、所述输入数据为待修复图像iin和一个二进制掩码m来描述缺失区域,其中在掩码m中1表示有效像素,0表示缺失像素;所述网络输出的修复图像表示为iout。利用加权的l1范数来估计逐像素重建的损失:
23、
24、
25、其中,igt是真值rgb图像,⊙为逐元素乘法运算,sum(m)是m中非零元素的数量,1为与矩阵m相同形状,元素值均为1的矩阵;
26、逐像素重建损失函数可以表示为:
27、lr=lvalid+λhlhole
28、其中lvalid表示有效像素的损失,lhole表示缺失像素的损失。λh为平衡因子。
29、在计算加权重建损失后,将网络输出图像与输入图像进行融合,从而计算总变差损失、感知损失和风格损失;
30、所述融合公式如下:
31、imer=igt⊙m+iout☉(1-m)
32、所述融合图像imer将输入图像的有效像元区域与网络输出生成的修复区域相结合,然后利用融合后的图像计算总变差损失ltv,作为平滑约束来增强整体图像质量,总变差损失ltv公式为:
33、ltv=||imer(i,j+1)-imer(i,j)||1+||imer(i+1,j)-imer(i,j)||1
34、其中i和j分别表示图像中像素的行数和列数;
35、所述特征空间中结合感知损失lper和风格损失lsty计算可以增强结构信息的恢复;所述vgg-16网络用于从真值图像、修复图像和融合图像中提取特征,以计算感知损失和风格损失;感知损失公式如下:
36、
37、其中表示预训练的vgg-16网络中第i层的特征图(i∈(5,10,17));
38、所述风格损失定义如下:
39、
40、其中是格拉姆矩阵;
41、综上所述,纹理修复网络优化的总损失如下:
42、l=lvaitd+λhlhote+λtvltv+λperlper+λstylsty
43、优选的,所述步骤s4中的表面重建是基于图割的表面重建,能够处理非水密的点云以及对大场景的可扩展性,利用最小s-t割算法进行解决,分割能量计算公式如下:
44、e(s)=evis(s,v)+λqleq(s)
45、
46、其中,重建的有向表面记为s,evis(s,v)表示所有视线v限制下,表面s中冲突和错误方向惩罚的总和;所述有向表面的三角形表面加了一个额外的平滑项表示为eql(s),以约束实际表面上不存在的小三角形表面;所述在图割方法中,es(v)表示外层空间的数据项,et(v)表示内部空间的数据项;最后,eij(v)表示平滑项。
47、优选的,所述步骤s4中的纹理重建是基于纹理映射的纹理重建,通过考虑虚拟视图及其对应的虚拟视点参数,为每个重建的三角表面确定最优纹理视图;所述选择视图的索引号用标签记录下来,将具有相同标签的三角形面片合并为一个面片,并计算其边界;然后从对应的视图中提取该区域并存储在地图册中以保留纹理信息,所述每个顶点对应的纹理坐标也被记录下来。
48、对于现有技术,本技术的技术方案具有如下的优点和效果:
49、1、本发明构建了一个完整的表面与纹理重建框架,通过设计一个可见性预测网络与一个纹理修复网络,利用卷积模拟了神经网络的稀疏输入,并利用注意机制和跨尺度特征融合增强了特征提取能力,分别预测视图内点的可见性信息与完整纹理图,最终使用基于图割的方法进行表面重建与基于纹理映射的方法进行纹理重建,与基于端到端学习的表面重建方法相比,我们的方法使用了直接和易于理解的二维可见性信息,以提供在不同场景中的通用性。
50、2、本发明设计了一种更灵活的虚拟视点选择方法,自动地对点云进行虚拟视点选取从而克服人工方法与规则方法选取虚拟视点的弊端,能够根据不同点云的特点自适应地选取高质量虚拟视点,从而获得更高质量的重建效果,此外,我们的方法不仅能够有效地利用点云的颜色信息进行纹理重建,也可以处理强度信息。
51、上述仅是本技术技术方案的概述,为了能够更清楚了解本技术的技术手段从而可依照说明书的内容予以实施,并且为了让本技术的上述和其他目的、特征和优点能够更明显易懂,以下以本技术的较佳实施例并配合附图详细说明如后。
52、根据下文结合附图对本技术具体实施例的详细描述,本领域技术人员将会更加明了本技术的上述及其他目的、优点和特征。
本文地址:https://www.jishuxx.com/zhuanli/20240905/286457.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。