基于ORS面向硬标签输出深度学习模型鲁棒性评估方法
- 国知局
- 2024-09-11 14:21:23
本发明涉及基于ors面向硬标签输出深度学习模型鲁棒性评估方法,属于鲁棒性评估。
背景技术:
1、大语言模型(large language model,llm)在生产和生活中的应用日益广泛。与传统的深度学习模型不同,llm的参数往往能够达到十亿的数量级。海量的参数使得llm相比于传统深度学习模型具有更强的自然语言处理(natural language processing,nlp)能力,能够完成更多种类、更高难度、更加多元的任务。chatgpt作为llm发展过程中的里程碑式的模型,其在多种nlp任务中都达到了最先进的水平。
2、然而,各种主流的深度神经网络(deep neural network,dnn)在受到对抗攻击时都会显露出不同程度的脆弱性。受到对抗攻击的深度学习模型被称为目标模型。逃逸攻击是一种最常见的对抗攻击方式,其作用于目标模型训练后的测试阶段,敌手往往通过构造对抗样本(adversarial example,ae)来实现逃逸攻击。ae是一种向原始良性样本中添加人类难以察觉的微小扰动后得到的恶意样本,其能够触发深度学习模型的错误预测。
3、当前大部分对抗文本生成方法的目标模型均为cnn类、rnn类以及基于transformer结构的深度学习模型,很少有工作研究当前流行的llm在对抗攻击条件下的鲁棒性并量化其评估标准。
技术实现思路
1、在下文中给出了关于本发明的简要概述,以便提供关于本发明的某些方面的基本理解。应当理解,这个概述并不是关于本发明的穷举性概述。它并不是意图确定本发明的关键或重要部分,也不是意图限定本发明的范围。其目的仅仅是以简化的形式给出某些概念,以此作为稍后论述的更详细描述的前序。
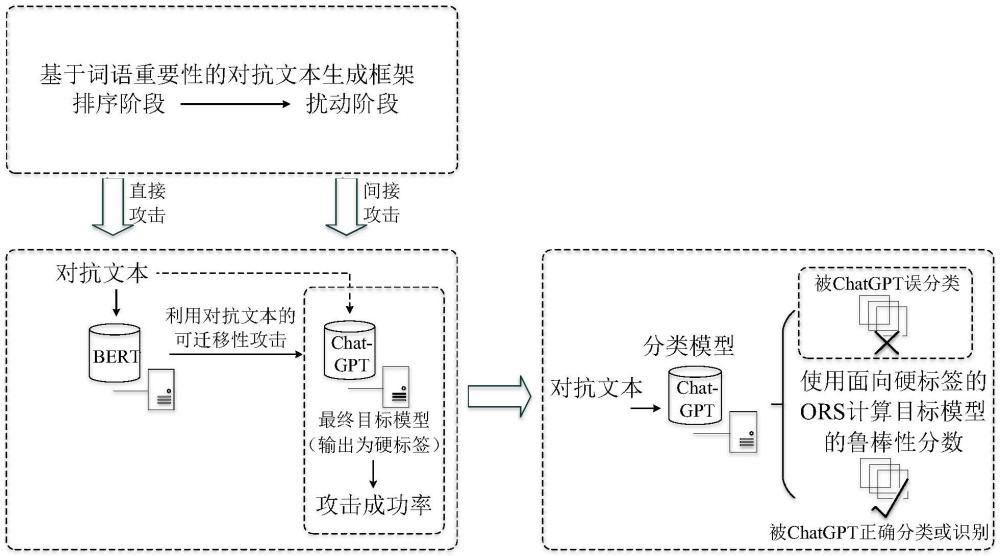
2、鉴于此,为解决现有技术中存在的缺少对llm在对抗攻击条件下的鲁棒性评估的问题,并量化其鲁棒性评估标准,本发明针对llm中的代表模型chatgpt,提出了基于ors面向硬标签输出深度学习模型鲁棒性评估方法。由于chatgpt的输出为硬标签,即它的输出仅包含预测标签,因此本发明根据这一特点,基于ors设计了一种面向硬标签输出深度学习模型鲁棒性评估方法,并对其鲁棒性进行量化。本发明将chatgpt作为目标模型进行文本对抗攻击,引入了一个新的数学概念,偏移平均差(offsetaverage difference,oad),并利用面向中文文本分类任务的多种对抗文本生成方法对目标模型的攻击有效性,基于oad设计了一种llm鲁棒性打分方法oad-based robustness score(ors)。该方法全面考量了黑盒场景下9种基于词语重要性的中文对抗文本生成方法对chatgpt的攻击有效性;不仅包含所有主流的中文对抗文本生成方法,同时也包含从英文对抗攻击方法中迁移的方法;ors利用攻击成功率,基于oad计算出chatgpt在每种方法下的鲁棒性得分,最终得到chatgpt在对抗文本攻击下的平均鲁棒性分数。
3、方案一、基于ors面向硬标签输出深度学习模型鲁棒性评估方法,生成对抗文本,并使用对抗文本攻击目标模型,利用ors计算目标模型的鲁棒性分数,评估鲁棒性。
4、优选的,对抗文本基于词语重要性框架生成,词语重要性框架包括排序阶段和扰动阶段。
5、优选的,排序阶段为文本中每个词语的重要性打分,并将词语按照重要性分数由高到低进行排序,扰动阶段为词语依次添加扰动。
6、优选的,为文本中每个词语的重要性打分的方法是:利用文本对应的真值标签上的置信度计算重要性分数,若重要性分数大于0,则说明文本中的词语对真值标签有正向影响,即词语为文本中重要词语,反之词语为文本中非重要词语;挑选重要性分数大于0的所有词语,并按重要性分数大小由高到低对词语进行排序。
7、优选的,为词语依次添加扰动方法是以下扰动方法的一种或任意组合;
8、扰动方法一:将文本中的简体字转化为对应的繁体字;
9、扰动方法二:在原文本中随机选择一个汉字,将汉字直接替换为对应的拼音形式;
10、扰动方法三:将一个汉字拆分成组成它的偏旁部首;
11、扰动方法四:使用一个汉字的形近字替换原汉字;
12、扰动方法五:将一个中文词语中包含的汉字打乱顺序;
13、扰动方法六:将原词语基于其中文拼音扰动为它的谐音词;
14、扰动方法七:基于专家构造的同义词词典寻找原词的同义词,并用挑选出的同义词对原词进行替换;
15、扰动方法八:在词嵌入空间中寻找离原词语的词向量最接近的前k个词向量,将词向量对应的词语作为原词语的候选替换词;
16、扰动方法九:利用bert模型中的mlm机制基于文本上下文生成原词语的候选替换词。
17、优选的,为词语依次添加扰动时有多个候选替换词构成候选词集,从候选词集中选择一个词语替换原词语时,选择替换前后目标模型置信度变化最大的词语替换原词。
18、优选的,利用ors计算目标模型的鲁棒性分数,评估鲁棒性方法是:量化一组离散的实数与某个给定的正常数的平均偏差,给定一组包含n个实数的离散的数值和一个正常数,计算离散数据与正常数c的oad值λ,oad为偏移平均差;
19、计算第i(i=1,...,n)个目标模型面对第j(j=1,...,m)种攻击时,在任意扰动率αk下的攻击成功率uij(αk);
20、计算离散数据与正常数c的oad值λ时引入放大系数β,将β设置为正整数,引入超参数q,并将q值设定为100;计算第i个目标模型在第j种攻击下的oad的值λij;
21、引入控制分制的超参数η,将η的取值设置为10;计算第i个目标模型在第j种攻击下的最终的鲁棒性得分rsij;
22、引入决策函数h(z),给参数β找到一个值,自变量z为β的取值,h(z)为面向所有模型的所有攻击方法中对应的oad取值最小的λij(z),将z从1开始代入h(z)中,若计算后得到的h(z)大于0,则将z加1后继续代入h(z)中,直至h(z)的值不大于0,即得到β的值为z减1,若直至z取到100时,h(z)的值仍大于0,则最终β的取值为100。
23、方案二、一种电子设备,包括存储器和处理器,存储器存储有计算机程序,所述的处理器执行所述计算机程序时实现方案一所述的基于ors面向硬标签输出深度学习模型鲁棒性评估方法的步骤。
24、方案三、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现方案一所述的基于ors面向硬标签输出深度学习模型鲁棒性评估方法。
25、本发明的有益效果如下:本发明提出了一种基于ors面向硬标签输出深度学习模型鲁棒性评估方法,该方法填补了当前对于以chatgpt为代表的llm鲁棒性评估的研究空白;该方法能够对目标模型的鲁棒性进行可量化的评估,以便在相同的评价标准下比较不同模型的鲁棒性;该方法引入扩大系数β,使得在允许范围内尽可能扩大不同模型之间的鲁棒性分数的差距,更加直观地对目标模型的鲁棒性进行评估。
本文地址:https://www.jishuxx.com/zhuanli/20240911/290372.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。