基于可解释模型预测感染性休克者亚甲蓝治疗响应的方法
- 国知局
- 2024-09-11 14:24:45
本发明涉及计算机及医学模型数据处理,具体涉及一种基于可解释模型预测感染性休克者(即感染性休克患者)亚甲蓝治疗响应的方法。
背景技术:
1、感染性休克(septic shock),又称脓毒性休克,是由微生物及其毒素等产物所引起的脓毒病综合征伴休克的病症。感染性休克是重症监护室(intensive care unit,icu)中最为常见的休克原因之一,其临床表现复杂多样,也是导致icu患者死亡的主要原因,其院内死亡率高达50%以上。血管麻痹是感染性休克的主要病理生理机制,联合使用不同机制的升压药物以减少儿茶酚胺类药物的用量是研究热点。
2、目前,治疗感染性休克指南建议首选的升压药物是去甲肾上腺素,但是大剂量长时间的使用可能引起包括肾小管坏死,肝坏死等严重的不良后果。此外,对去甲肾上腺素无应答的患者,常常需要联合其他血管活性药物共同治疗。然而,血管活性药物的大剂量使用会导致不良反应的发生。感染性休克现有的治疗方案并未有效降低患者病死率,仍需寻求新的药物,为治疗感染性休克患者提供新的可能。亚甲蓝(methylene blue,mb)作为选择性一氧化氮合酶抑制剂,部分阻断一氧化氮的血管扩张作用,是一种安全、价廉、容易获得的辅助升压药物,近年来受到越来越多的关注。许多研究表明,亚甲蓝能够显著升高各种血管麻痹性休克的血压,减少去甲肾上腺素的使用,甚至降低患者病死率。然而,由于目前缺乏足够的循证医学证据,无法确定哪些患者能从亚甲蓝治疗中获益,且影响亚甲蓝升压有效性的关键影响因素尚不明确。
3、随着机器学习、人工智能等技术的快速发展,医学与计算机的深度交叉融合促使医学领域不断创新,机器学习模型在药物疗效评估中取得了显著性进展,为个体化治疗提供新的可能性。机器学习预测模型有助于识别有效人群,结合可解释工具可提高模型的可理解性和可信度,辅助医生进行临床决策。从数据驱动的角度运用可解释机器学习算法深入挖掘患者对亚甲蓝药物的个体响应,具有十分重要的意义。
4、综上所述,亚甲蓝作为感染性休克的潜在的升压药物之一,其有效性难以预测,适宜人群亦未知。在临床上,感染性休克患者是否使用亚甲蓝进行升压主要依赖医生的经验,这影响了亚甲蓝药物在临床上的合理使用。目前,尚未发现公开的技术方案涉及使用可解释机器学习方法预测感染性休克者亚甲蓝药物治疗响应。
技术实现思路
1、本发明要解决的技术问题是针对目前感染性休克患者对亚甲蓝药物响应的关键因素未知,采用现有技术无法预测亚甲蓝作为感染性休克者的潜在升压药物之一的有效性,且无法知道适宜人群的问题,提供一种基于可解释模型预测感染性休克者(即感染性休克患者)亚甲蓝治疗响应的方法,通过多方法多重筛选的特征工程构建了两组感染性休克亚甲蓝药物治疗响应的临床数据集,利用不同的机器学习模型预测药物治疗响应,并引入shap(shapley additive explanations)解释器对最优的机器学习模型进行解释,寻找影响亚甲蓝升压有效性的关键因素,预测亚甲蓝作为感染性休克者的潜在升压药物之一的有效性,并找到适宜人群。
2、本发明的技术方案是:
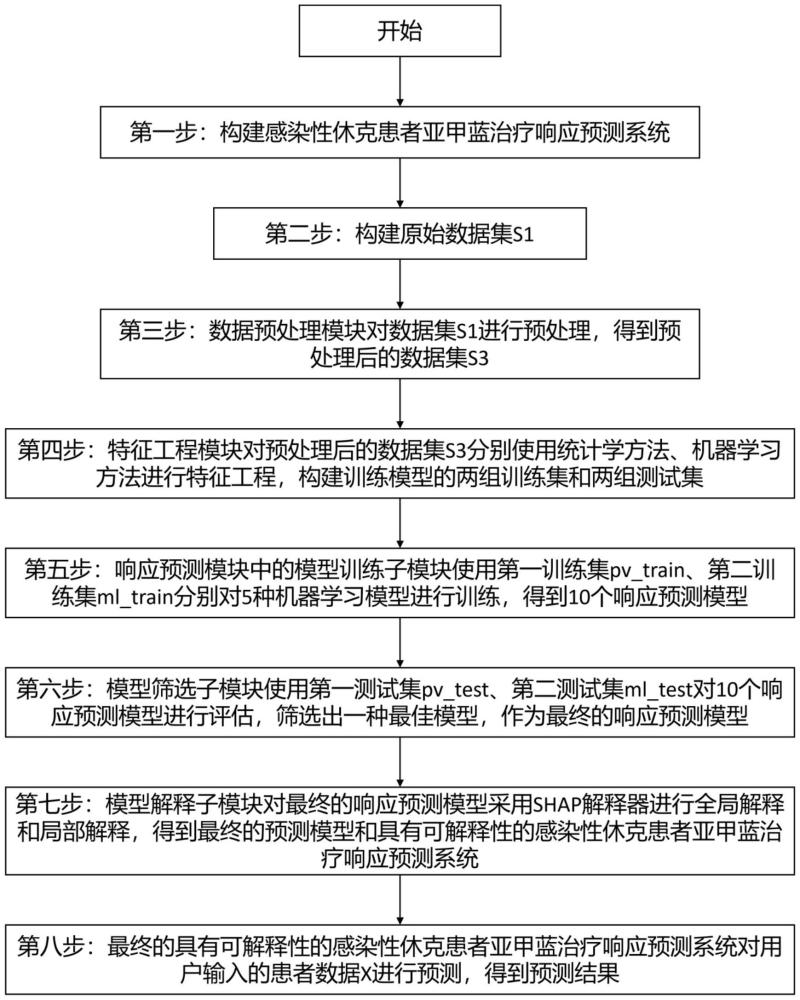
3、第一步,构建感染性休克患者亚甲蓝治疗响应预测系统。感染性休克患者亚甲蓝治疗响应预测系统由数据预处理模块、特征工程模块、响应预测模块组成。
4、数据预处理模块与特征工程模块相连,训练时,数据预处理模块读取原始数据集s1(s1由24个特征构成),对s1中的特征进行数据清理,得到清理后的数据集s2;然后对s2进行数据变换,先对s2中连续型特征进行数据标准化,得到标准化后的数据集s2',再对s2'中分类型特征进行独热编码,得到预处理后的数据集s3,将s3发送给特征工程模块。当对用户输入的感染性休克患者数据x进行预测时,对x进行数据清理,得到清理后的数据x',再对x'进行数据变换,得到预处理后的感染性休克患者数据x”',将x”'发送给响应预测模块。
5、特征工程模块与数据预处理模块、响应预测模块相连。由于本发明的研究对象数据集一般较小,特征数量较多,直接输入全部数据进行模型训练,很容易导致过拟合,因此本发明采用两种方法对s3进行特征工程,一种是基于临床研究常用的统计学方法,另一种是基于机器学习方法。训练时,特征工程模块接收数据预处理模块输入的数据集s3,先使用统计学方法进行显著特征筛选,得到第一数据集pv_data,将pv_data划分为第一训练集pv_train和第一测试集pv_test。然后对s3使用机器学习方法进行特征筛选,得到第二数据集ml_data,将ml_data划分为第二训练集ml_train和第二测试集ml_test。将第一训练集pv_train、第一测试集pv_test、第二训练集ml_train、第二测试集ml_test发送给响应预测模块。
6、响应预测模块与特征工程模块、数据预处理模块相连,响应预测模块由模型训练子模块、模型筛选子模块、模型解释子模块、预测模型构成。模型训练子模块与特征工程模块、模型筛选子模块相连,包含逻辑回归模型(logistic regression,lr)、随机森林模型(randomforest,rf)、支持向量机模型(support vector machine,svm)、可解释提升机模型(explainable boosting machine,ebm)、轻量级梯度提升机模型(light gradientboostingmachine,lightgbm))。训练时,模型训练子模块接收特征工程模块输入的第一训练集pv_train,对5种模型进行训练,并调整5种模型的超参数,得到5个响应预测模型。模型训练子模块还接收特征工程模块输入的第二训练集ml_train,对5种模型进行训练,并调整5种模型的超参数,又得到5个响应预测模型。训练后共得到10个响应预测模型,将10个响应预测模型发送给模型筛选子模块。
7、模型筛选子模块与特征工程模块、模型训练子模块、模型解释子模块相连,训练时,模型筛选子模块接收模型训练子模块输入的10个响应预测模型,在接收特征工程模块输入的第一测试集pv_test时,对基于第一训练集pv_train建立的5个响应预测模型进行评估;在接收特征工程模块输入的第二测试集ml_test时,对基于第二训练集ml_train建立的5个响应预测模型进行评估,对从模型训练子模块接收的10个响应预测模型进行评估,得到最佳的响应预测模型。将最佳的响应预测模型及其使用的数据集发送给模型解释子模块(例如最佳的响应预测模型是基于第一训练集pv_train建立的svm模型,就将第一训练集pv_train和svm模型一起发送给模型解释子模块)。
8、模型解释子模块与模型筛选子模块相连,训练时,模型解释子模块接收模型筛选子模块输入的最佳响应预测模型及其使用的数据集,将其输入到shap解释器中,使用shap解释器对最佳的响应预测模型进行全局解释(获取各个特征对亚甲蓝药物响应预测的重要性程度)和局部解释(获取各个特征是如何影响预测模型对单个患者的预测)。
9、最佳的响应预测模型和shap解释器一起构成了训练得到的最终的预测模型。当对用户输入的单个感染性休克患者数据x进行预测时,预测模型接收数据预处理模块输入的x”',预测模型中的最佳的响应预测模型输出该患者对亚甲蓝药物响应的预测结果(有响应/无响应),预测模型中的shap解释器输出各个特征对该患者响应预测结果的shap值,并可视化这些shap值,显示每个特征对该患者的响应预测结果的贡献程度。
10、第二步,构建原始数据集s1,方法是:
11、2.1初始化原始数据集s1为空,s1的每个表项包括26个域,分别为患者id编号(具有唯一性)、24个用于构建模型的特征、患者对亚甲蓝药物是否响应的标签。
12、2.2从医院的脓毒症专病数据库提取满足以下3个条件的患者id编号:(1)诊断为脓毒性休克;(2)患者年龄≥18岁;(3)接受亚甲蓝作为二线缩血管药物升压治疗(患者接受去甲肾上腺素泵入至少6h后启动亚甲蓝)。若患者多次使用亚甲蓝升压,则只将与第二次使用亚甲蓝的时间间隔>6h的患者纳入s1。
13、将满足以下条件之一的患者id编号从s1中删除:(1)使用亚甲蓝后icu住院时间<24h;(2)不能明确亚甲蓝是否用于升压及因数据缺失无法判断有效性的患者。令此时s1中的患者id编号共有m个,m为正整数,即此时s1共有m个表项,1个表项对应1个患者的样本。
14、2.3根据s1中的患者id编号,从医院的脓毒症专病数据库提取24个用于构建模型的特征,包括患者性别、住院时年龄(岁)、体重(kg)、吸烟史、饮酒史、合并症(高血压、糖尿病、冠心病、房颤、肺部疾病、肾病、肝脏疾病、免疫功能抑制情况)、icu类型(中心icu和其他icu)、是否使用特利加压素、是否使用激素、启动亚甲蓝前6h平均去甲等量(neepre)、氧疗方式(有创呼吸机辅助呼吸和无创辅助呼吸)、氧合指数(oxygenation index,oi)、是否连续性肾脏替代治疗(continuous renal replacement therapy,crrt)、乳酸、中心静脉血氧饱和度(scvo2)、启动亚甲蓝距离首次启动去甲肾上腺素的时间(tne)、启动亚甲蓝距离诊断休克的时间(tshock),将这些内容放到s1的患者id编号对应的表项中。以上24个特征分为连续型特征和分类型特征。连续型特征包括患者住院时年龄(岁)、体重(kg)、neepre、oi、乳酸、scvo2、tne、tshock,分类型特征包括患者性别、吸烟史、饮酒史、高血压、糖尿病、冠心病、房颤、肺部疾病、肾病、肝脏疾病、免疫功能抑制情况、icu类型、是否使用特利加压素、是否使用激素、氧疗方式、是否连续性肾脏替代治疗。
15、其中,启动亚甲蓝前6h平均去甲等量(neepre)是计算启动亚甲蓝前6h内去甲等量(nee)的用量(假设所有药物使用都是匀速的),nee的计算公式(见文献“kotani,y.,digioia,a.,landoni,g.et al.an updated“norepinephrine equivalent”score inintensive care as amarker of shock severity[j].crit care重症监护,2023,27(1):29.”,kotani,y.等人的论文:重症监护中更新的“去甲肾上腺素等量”评分作为休克严重程度的标志)为:nee=norepinephrine dose(μg/kg/min)+1/100×dopamine dose(μg/kg/min)+0.06×phenylephrine dose(μg/kg/min)+10×terlipressin特利dose(μg/kg/min)+0.2×methylene blue亚甲蓝dose(mg/kg/h)+8×metaraminol间羟胺dose(μg/kg/min)+0.02×hydroxocobalamin维生素b12dose(g)+0.4×midodrine米多君dose(μg/kg/min)。。氧合指数oi=pao2/fio2,其中pao2为动脉血氧分压,fio2为吸入氧浓度百分比,oi的正常值为400-500mmhg。乳酸主要是用于检测血液中的乳酸盐含量,正常值一般为0.5~1.7mmol/l。中心静脉血氧饱和度(scvo2)是指人体中心静脉血液中的氧气饱和度水平,是评估患者氧供需平衡的重要指标之一,scvo2正常值在70%~75%之间。
16、2.4根据以下条件得出s1中m个患者对亚甲蓝是否响应的标签(有响应时标签为1,无响应响应时标签为0)。
17、患者对亚甲蓝有响应(即升压有效)定义为满足以下2个条件之一:(1)nee下降>10%(即nee%<-10%)且平均动脉压(map_avg_post)≥65mmhg;(2)nee下降、不变、或增加<10%(即10%>nee%≥-10%)但平均动脉压改变值(map_avg%)上升≥10mmhg。具体来说,满足以上2个条件之一时,认为亚甲蓝升压有效,将s1中患者id编号对应的标签赋值为1,两项条件均不符合时定义亚甲蓝升压无效,将s1中患者id编号对应的标签赋值为0。
18、其中,nee的改变值(nee%)=(neepost-neepre)/neepre×100%,neepost为启动亚甲蓝后6h平均去甲等量(同neepre可以通过公式计算得到)。平均动脉压(map)=[收缩压+(舒张压×2)]/3,正常成年人平均动脉压正常值为70~105mmhg。分别计算启动亚甲蓝前6h和后6h内平均动脉压的平均值(map_avg)得到map_avg_pre和map_avg_post,map_avg的改变值(map_avg%)=(map_avg_post-map_avg_pre)。此时,s1中有响应的患者为m_1位,无响应的患者为m_0位。
19、第三步,数据预处理模块对数据集s1进行预处理,得到预处理后的数据集s3。
20、3.1对s1进行数据清理,方法是:
21、3.1.1使用箱线图(boxplot)对s1进行异常值(被记录错误的数据值或反常的数据值)检测,删除异常值或者使用该特征的平均值对异常值进行填充,得到数据集s1',s1'中患者id编号共有m2个,m2≤m且m2为正整数。
22、3.1.2删除s1'中数据缺失比例(某个特征(如体重,年龄)数据中缺失数据的数量占数据总体数量m2的比例)超过30%的特征,对于数据缺失比例<30%的特征,使用多重knn插补法(见文献“thomas t,et al.addressing missing data in a healthcare datasetusing an improved knn algorithm[c].2021”thomas t等人的论文:使用改进的knn算法解决医疗保健数据集中的缺失数据)进行插补,具体步骤是:
23、3.1.2.1将s1'拆分为有缺失值的部分s11和完整的部分s12,s11是需要进行插补的特征。
24、3.1.2.2对s11进行插补处理,得到k(k为正整数,优选为20)个插补后的数据集s111,…,s11k,…,s11k(1≤k≤k且k为正整数),s111,…,s11k,…,s11k中患者id编号都是m2个,与s11的区别是数据缺失比例<30%的特征都已插补完整,且不含有≥30%的特征,并基于s111,…,s11k,…,s11k随机划分训练集和测试集并进行模型训练和评估,得到avg_accuracy1,…,avg_accuracyk,…,avg_accuracyk,和avg_rmse1,…,avg_rmsek,…,avg_rmsek,avg_accuracyk为对s11k的评估指标平均准确度,avg_rmsek为对s11k的评估指标平均均方根误差;具体过程是:
25、3.1.2.2.1令k=1:
26、3.1.2.2.2对s11中每个特征的缺失值进行第k次knn插补:
27、3.1.2.2.2.1计算s11中有特征缺失值的样本与s12中每个样本的距离;
28、3.1.2.2.2.2选择距离最近的k个样本;
29、3.1.2.2.2.3对于s11中的连续型特征,通过加权平均计算k个样本的平均值来填充缺失值;对于s11中的分类型特征,通过投票选取分类型特征中出现最频繁的类别来填充缺失值,得到插补后的s11';
30、3.1.2.2.2.4将插补得到的s11'与s12合并,得到第k次插补后的数据集s11k。
31、3.1.2.2.3对s11k进行n(n为正整数,优选为20)次评估,得到n个对s11k的评估指标准确度accuracy-1,…,accuracy-n,…,accuracy-n和n个均方根误差rmse-1,…,rmse-n,…,rmse-n(1≤n≤n且n为正整数);accuracy-n为第n次对s11k的评估指标准确度,rmse-n为第n次对s11k的评估指标均方根误差,方法是:
32、3.1.2.2.3.1令n=1;
33、3.1.2.2.3.2对s11k按照3:1的比例进行随机划分,得到训练集n_train和测试集n_test(每一次的划分都是随机的,得到的n_train和n_test也不相同);
34、3.1.2.2.3.3基于n_train训练随机森林模型,并基于n_test评估建立的随机森林模型,计算随机森林模型的第n次训练后的准确度accuracy-n和第n次训练后的均方根误差rmse-n;
35、3.1.2.2.3.4令n=n+1,若n≤n,转3.1.2.2.3.2继续随机划分训练集和测试集并进行模型训练和评估,否则,得到了accuracy-1,…,accuracy-n,…,accuracy-n和rmse-1,…,rmse-n,…,rmse-n,转3.1.2.2.4。
36、3.1.2.2.4计算accuracy-1,…,accuracy-n,…,accuracy-n的平均值,得到s11k的平均准确度avg_accuracyk,计算rmse-1,…,rmse-n,…,rmse-n的平均值,得到s11k的平均均方根误差avg_rmsek;
37、3.1.2.2.5令k=k+1,若k≤k,转3.1.2.2.1,否则得到avg_accuracy1,…,avg_accuracyk,…,avg_accuracyk,和avg_rmse1,…,avg_rmsek,…,avg_rmsek,转3.1.2.3。
38、3.1.2.3比较avg_accuracyk,…,avg_accuracyk,…,avg_accuracyk和avg_rmse1,…,avg_rmsek,…,avg_rmsek,选择平均准确度最大且平均均方根误差相对较小的k值对应的数据集s11k作为清理后的数据集s2。s2中特征数量共有t个,其中连续性特征有t1个,分类型特征有t2个,t1+t2=t,t≤24且t为正整数。
39、3.2对s2进行数据变换,方法是:
40、3.2.1对s2中m2个患者的t1个连续型特征数据使用z-score标准化法进行数据标准化(分类型特征数据不做处理),得到数据标准化后的数据集s2',方法是:
41、3.2.1.1将s2分为包含t1个连续型特征数据的部分s21和包含t2个分类型特征数据的部分s22。
42、3.2.1.2对s21中的特征进行标准化,得到标准化后的数据集s21',方法是:
43、3.2.1.2.1令变量i=1(i值从1~t1,i为正整数)
44、3.2.1.2.2计算s21中第i个连续型特征的均值μi和标准差σi;
45、3.2.1.2.3对s21中m2个患者的第i个连续型特征进行数据标准化,得到m2个标准化后的第i个连续型特征的值,方法是:
46、3.2.1.2.3.1令变量j=1(j值从1~m2,j为正整数);
47、3.2.1.2.3.2对第i个连续型特征的第j个患者的特征值xj进行标准化,得到xj′,计算公式为:
48、
49、其中,xj是第j个患者的原始特征值,xj′是标准化后的特征值。
50、3.2.1.2.3.3使用标准化后的特征值xj′替换原始的特征值xj。
51、3.2.1.2.3.4令j=j+1,如果j≤m2,转3.2.1.2.3.2,否则转3.2.1.2.4。
52、3.2.1.2.4.令i=i+1,如果i≤t1,转3.2.1.2.2,否则,得到标准化后的特征数据集s21',转3.2.1.3。
53、3.2.1.3将s21'与s22合并,得到标准化后的特征数据集s2'。
54、3.2.2对s2'中m2个患者的t2个分类型特征数据进行独热编码(见文献“liangjie,etal.one-hot encoding and convolutional neural network based anomalydetection[j].journal of tsinghua university(science and technology),2019,59(7):523-529.”梁杰等人.基于独热编码和卷积神经网络的异常检测),得到预处理后的数据集s3,s3中也有m2个进行了独热编码的患者的样本。将s3发送给特征工程模块。
55、第四步,特征工程模块对预处理后的数据集s3分别使用统计学方法、机器学习方法进行特征工程,构建训练模型的两组训练集和两组测试集。
56、4.1特征工程模块使用统计学方法对s3进行特征工程,得到第一数据集pv_data,pv_data中包含t1个特征,将pv_data划分为第一训练集pv_train和第一测试集pv_test,pv_train中包含m'位患者,pv_test中包含m”位患者,m'+m”=m2,方法是:
57、4.1.1根据患者对亚甲蓝是否响应的标签将s3分为两个组,分别为有响应组和无响应组。
58、4.1.2基于假设检验方法(见文献“jia junping,et al.statistics[m].北京:中国人民大学出版社,2018”贾俊平等人的著作的p156~p184:统计学)进行有响应组和无响应组的各个特征的组间差异性分析。本发明用到的假设检验方法包括卡方检验方法、独立样本t检验方法和wilcoxon秩和检验方法,在进行检验时需要计算p值来判断假设检验的结果。具体来说,使用卡方检验方法比较分类型特征在有响应和无响应两个组间的差异(计算p值,根据p值判断分类型特征在有响应和无响应两个组之间的差异是否显著)。针对连续型特征,对于符合正态分布的连续型特征使用独立样本t检验方法比较其在有响应和无响应两个组之间的差异(计算p值),对于不符合正态分布的连续型特征使用wilcoxon秩和检验方法比较其在有响应和无响应两个组之间的差异(计算p值)。在统计学中,通常认为p值<0.05的特征在两个组之间具有显著差异。然而,由于使用亚甲蓝治疗的感染性休克患者较少,本发明的数据集通常较小,导致一些重要因素可能不显著。为了有效地避免漏掉一些重要因素,需要重新设定p值(见文献“kang sj,et al.predictors for functionallysignificant in-stent restenosis:an integrated analysis using coronaryangiography,ivus,and myocardial perfusion imaging[j].jacc cardiovasc imaging,2013,6(11):1183-1190.”kang sj等人.功能显著的支架内再狭窄的预测因素:使用冠状动脉照影、ivus和心肌灌注成像的综合分析),尽可能纳入较多的变量。经过多次实验,发现通过筛选p值<0.3的特征,可以有效地避免漏掉一些重要因素,因此,p值设置为<0.3。
59、4.1.3通过皮尔森相关系数检验探究4.1.2中筛选出来的特征之间的相关性,去除冗余特征后,得到第一数据集pv_data,pv_data中包含t1个特征。
60、4.1.4将pv_data按照3:1的比例划分为第一训练集pv_train和第一测试集pv_test,将pv_train发送给响应预测模块中的模型训练子模块,将pv_test发送给响应预测模块中的模型筛选子模块。
61、4.2特征工程模块使用机器学习方法对s3进行特征工程,得到用于最终建模的数据集ml_data,ml_data中包含t2个特征,将ml_data划分为第二训练集ml_train和第二测试集ml_test,ml_train中包含mm'位患者,ml_test中包含mm”位患者,mm'+mm”=m2,方法是:
62、4.2.1使用随机森林作为基模型,采用递归特征消除与交叉验证(rfecv)(见文献“staartjes v e,et al.foundations of feature selection in clinical predictionmodeling[c].2022”staartjes v e等人的论文:临床预测建模中特征选择的基础)的方法对s3进行特征筛选,通过逐步移除特征并利用交叉验证来确定最佳特征子集,得到用于最终建模的数据集ml_data,ml_data中包含t2个特征。
63、4.2.2将ml_data按照3:1的比例划分为第二训练集ml_train和第二测试集ml_test,将ml_train发送给响应预测模块中的模型训练子模块,将ml_test发送给响应预测模块中的模型筛选子模块。
64、第五步,响应预测模块中的模型训练子模块使用第一训练集pv_train、第二训练集ml_train分别对5种机器学习模型进行训练,得到10个响应预测模型。
65、5.1使用模型训练方法,采用第一训练集pv_train对lr模型、rf模型、ebm模型、svm模型和lightgbm模型进行训练。为了得到最佳的模型性能,采用网格搜索和5折交叉验证方法调整模型的超参数组合,得到5个基于第一训练集建立的响应预测模型,具体如下:
66、5.1.1采用第一训练集pv_train对lr模型进行训练,使用网格搜索和5折交叉验证方法调整模型的超参数组合,以模型的准确度作为评估标准选择最佳的超参数组合得到响应预测模型pv_lr。
67、5.1.2采用第一训练集pv_train对rf模型进行训练,使用网格搜索和5折交叉验证方法调整模型的超参数组合,以模型的准确度作为评估标准选择最佳的超参数组合得到响应预测模型pv_rf。
68、5.1.3采用第一训练集pv_train对ebm模型进行训练,使用网格搜索和5折交叉验证方法调整模型的超参数组合,以模型的准确度作为评估标准选择最佳的超参数组合得到响应预测模型pv_ebm。
69、5.1.4采用第一训练集pv_train对svm模型进行训练,使用网格搜索和5折交叉验证方法调整模型的超参数组合,以模型的准确度作为评估标准选择最佳的超参数组合得到响应预测模型pv_svm。
70、5.1.5采用第一训练集pv_train对lightgbm模型进行训练,使用网格搜索和5折交叉验证方法调整模型的超参数组合,以模型的准确度作为评估标准选择最佳的超参数组合得到响应预测模型pv_lightgbm。
71、5.2采用5.1所述模型训练方法,使用第二训练集ml_train对lr模型、rf模型、ebm模型、svm模型和lightgbm模型进行训练,得到5个基于第二训练集建立的响应预测模型,分别为ml_lr、ml_rf、ml_ebm、ml_svm、ml_lightgbm。
72、5.3将5个基于第一训练集建立的响应预测模型和5个基于第二训练集建立的响应预测模型发送给模型筛选子模块。
73、第六步,模型筛选子模块使用第一测试集pv_test、第二测试集ml_test对10个响应预测模型进行评估,筛选出一种最佳模型,作为最终的响应预测模型。
74、6.1初始化混淆矩阵a(2×2的一张表)为空,混淆矩阵a包含4个元素,分别为a11,a12,a21,a22,初始都为0。a11存放模型预测标签为1真实标签也为1(真阳性)的数量tp,a12存放模型预测标签为1真实标签为0(假阳性)的数量fp,a21存放模型预测标签为0真实标签为1(假阴性)的数量fn,a22存放模型预测标签为0真实标签为0(真阴性)的数量tn。
75、混淆矩阵a
76、
77、6.2基于第一测试集pv_test,采用响应预测模型评估方法对5.1得到的5个基于第一训练集的响应预测模型进行评估,得到一个最佳的基于第一训练集的响应预测模型,方法是:
78、6.2.1基于第一测试集pv_test分别计算5个响应预测模型的准确率(acc)、灵敏度(sensitivity)、特异度(specificity)、f1score、阳性预测值(ppv)、阴性预测值(npv)、auc值、布里尔(brier)分数这8个评价指标。
79、6.2.1.1采用指标计算方法计算pv_lr模型的8个评价指标:
80、6.2.1.1.1将第一测试集的m”位患者输入5.1.1建立的pv_lr模型中,pv_lr预测模型输出m”位患者对亚甲蓝药物响应的结果(有响应1,无响应0),以及m”位患者对亚甲蓝药物响应的概率值,通过统计实际标签与预测标签,对6.1的混淆矩阵a进行填充,得到填充后的混淆矩阵a,即a11=tp,a12=fp,a21=fn,a22=tn,得到如表2所示的填充后的混淆矩阵表a:
81、填充后的混淆矩阵a
82、
83、其中,tp表示pv_lr模型对m”位患者中实际对亚甲蓝有响应被正确预测为有响应的患者数量;fp表示pv_lr模型对m”位患者中实际对亚甲蓝无响应被错误预测为有响应的患者数量;fn表示pv_lr模型对m”位患者中实际对亚甲蓝有响应被错误预测为无响应的患者数量;tn表示pv_lr模型对m”位患者中实际对亚甲蓝无响应被正确预测为无响应的患者数量,tp+tn+fp+fn=m”。
84、6.2.1.1.2基于填充后的混淆矩阵a,计算8种评价指标:
85、6.2.1.1.2.1计算准确率(acc):分类模型正确预测的样本数占总样本数的比例:
86、
87、6.2.1.1.2.2计算灵敏度(sensitivity):分类模型正确预测为正例的样本数占所有正例样本数的比例:
88、
89、6.2.1.1.2.3计算特异度(specificity):分类模型正确预测为反例的样本数占所有反例样本数的比例:
90、
91、6.2.1.1.2.4计算f1-分数f1score:精确度(precision)和召回率(recall)的调和平均值:
92、
93、6.2.1.1.2.5计算阳性预测值(ppv):分类模型预测为正例的样本中真正为正例的比例:
94、
95、6.2.1.1.2.6计算阴性预测值(npv):分类模型预测为反例的样本中真正为反例的比例:
96、
97、6.2.1.1.2.7计算auc(area under curve):受试者工作特征曲线(roc曲线)下面积,roc曲线是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(敏感性)为纵坐标,假阳性率(1-特异性)为横坐标绘制的曲线。其计算公式为:
98、
99、6.2.1.1.2.8计算布里尔分数(brier score):衡量分类问题中模型预测结果与实际结果之间的差距,取值范围在0~1之间,值越小表示模型的预测准确性越高。
100、
101、其中,m”表示pv_test中样本量,fj是响应预测模型对pv_test中患者j的预测概率,oj是pv_test中患者j的实际类别标签,通常取0或1。
102、6.2.1.2采用6.2.1.1步所述指标计算方法计算pv_rf模型的8个评价指标:
103、6.2.1.3采用6.2.1.1步所述指标计算方法计算pv_ebm模型的8个评价指标:
104、6.2.1.4采用6.2.1.1步所述指标计算方法计算pv_svm模型的8个评价指标:
105、6.2.1.5采用6.2.1.1步所述指标计算方法计算pv_lightgbm模型的8个评价指标:
106、6.2.2准确率(accuracy)、灵敏度(sensitivity)、特异度(specificity)、f1score、阳性预测值(ppv)、阴性预测值(npv)、auc值都是越大越好,布里尔(brier)分数是越小越好,根据这8个评价指标来评估5个模型的表现。5个模型中,若这些指标达到最优值的数量相同,则优先选择accuracy和auc值更好的模型,得到5.1得到的5个模型中最佳的基于第一训练集的响应预测模型,简称第一最佳模型。
107、6.3基于第二测试集ml_test,采用6.2步所述响应预测模型评估方法对5.2得到的5个基于第二训练集的响应预测模型进行评估,得到一个最佳的基于第二训练集的响应预测模型,简称第二最佳模型。
108、6.4基于第一训练集pv_test绘制第一最佳模型的3种可视化曲线(roc曲线、校准曲线、临床决策曲线dca),基于第二训练集ml_test绘制第二最佳模型的3种可视化曲线。比较第一最佳模型和第二最佳模型在3种可视化曲线中的表现,选择在可视化曲线中表现更好的数量较多的模型,即为最终的响应预测模型。将最终的响应预测模型及其使用的训练集(训练集中包含t个特征,t=t1或t2)发送给模型解释子模块。
109、第七步,模型解释子模块对最终的响应预测模型采用shap解释器(见文献“jiaxiao-yao,.breast cancer prediction and feature analysis model based oncatboost and shap[j].computer and modernization,2023,0(10):32-38.”贾潇瑶的论文:融合catboost和shap的乳腺癌预测及特征分析)进行全局解释和局部解释,得到最终的预测模型和具有可解释性的感染性休克患者亚甲蓝治疗响应预测系统。
110、7.1模型解释子模块是采用python开发的一个“模型解释包”shap实现的shap解释器,使用时需要先安装shap包,通过import shap语句导入shap库。
111、7.2使用“shap.explainer”类初始化shap解释器,将最终的响应预测模型使用的训练集和最终的响应预测模型输入shap解释器中,完成shap解释器的初始化,得到初始化后的shap解释器。
112、7.3通过shap解释器中的“shap_values”函数计算最终的响应预测模型使用的训练集中t个特征的shap值,并计算最终的响应预测模型使用的训练集中的t个特征的shap值的绝对值的平均值avg_shap_1,…,avg_shap_f,…,avg_shap_t,f为正整数且1≤f≤t。
113、7.4对最终的响应预测模型进行全局解释,以avg_shap_1,…,avg_shap_f,…,avg_shap_t作为t个特征对亚甲蓝药物响应预测的重要性程度。通过shap解释器中的“summary_plot”可视化函数得到一张t个特征对模型预测重要性的排序图。找到avg_shap_1,…,avg_shap_f,…,avg_shap_t中小于阈值threshold的特征,(threshold是根据特征重要性分布选择的,threshold=(avg_shap_1+…+avg_shap_f+…+avg_shap_t)/(2×t)),令avg_shap_1,…,avg_shap_f,…,avg_shap_t中小于threshold的特征个数为t3,则这t3个特征是对亚甲蓝药物响应的关键特征,t3<t,t3为正整数。
114、7.5对最终的响应预测模型进行局部解释,即解释t个特征如何影响预测模型对单个患者的预测结果。通过shap解释器中的“waterfall”可视化函数,对7.3步计算的任意一个患者(令为x1)的t个特征的shap值进行可视化,生成一张x1的瀑布图,在x1的瀑布图中,e[f(x1)]表示模型的初始预测偏差(在没有任何特征信息的情况下,模型预测的平均结果),f(x1)表示模型对于给定样本x1的预测输出值,每个特征对于模型输出的影响以柱状图的形式展现,红色条形表示特征对预测起正向作用,蓝色条形表示特征对预测起负向作用。每个特征的柱状图的高度表示了该特征对于模型输出的影响的大小。x1的瀑布图展示各个特征对患者x1响应预测结果的贡献。
115、7.6最终的响应预测模型与初始化后的shap解释器一起构成响应预测模块中最终的预测模型,此时得到最佳的具有可解释性的感染性休克患者亚甲蓝治疗响应预测系统。
116、第八步,最终的具有可解释性的感染性休克患者亚甲蓝治疗响应预测系统对用户输入的患者数据x进行预测,得到预测结果,方法是:
117、8.1数据预处理模块对用户输入的患者数据x进行预处理,方法是:
118、8.1.1对x进行数据清理。检查x中特征是否存在缺失值或异常值,如果存在,使用最终的响应预测模型的训练集中该特征的平均值进行填充,得到清理后的数据x'。
119、8.1.2对x'进行数据变换。对于x中的连续型特征,基于最终的响应预测模型的训练集中对应特征的均值和方差,使用z-score标准化法对特征进行数据标准化得到标准化后的数据x”;对x”中的分类型特征进行独热编码,得到预处理后的感染性休克患者数据x”',将x”'发送给响应预测模块中的预测模型。
120、8.2响应预测模块的预测模型中最终的响应预测模型对x”'进行预测,得到该患者对于亚甲蓝药物有无响应的预测结果(有响应或无响应)。
121、8.3响应预测模块的预测模型中的shap解释器计算x”'中各个特征对亚甲蓝药物响应预测的shap值,采用7.5步所述的“waterfall”可视化函数对shap值进行可视化,生成x的瀑布图,x的瀑布图中,e[f(x)]表示模型的初始预测偏差,f(x)表示模型对于x的预测输出值,每个特征对于模型输出的影响以柱状图的形式展现,红色条形表示特征对预测起正向作用,蓝色条形表示特征对预测起负向作用。x的瀑布图展示各个特征对该患者响应预测结果的贡献,帮助医生了解和信任模型,以辅助医生对x进行决策。
122、采用本发明可以达到以下技术效果:
123、1.本发明第四步特征工程模块综合运用了多种方法进行特征工程,针对感染性休克亚甲蓝药物治疗响应的临床数据集构建了两组数据集,并将其分别划分为训练集和测试集。通过特征工程模块能够筛选出更相关的特征,从而提升模型预测的性能和准确度。亚甲蓝作为一种治疗感染性休克患者的二线升压药被使用,因此面向该研究的数据集通常较小,过多的特征可能会导致模型过拟合的问题。特征工程模块通过使用多种方法进行特征工程,避免了模型过度依赖于单一特征工程方法,降低模型过拟合的风险,进而提升了模型的泛化能力。
124、2.本发明第五步利用五种不同的机器学习模型预测药物治疗响应,通过比较不同模型的预测结果,选择性能最优的模型,并引入shap(shapley additive explanations)可解释器对最优的机器学习模型进行解释。一方面,可以增强模型的鲁棒性,提升预测的准确度;另一方面,通过解释器挖掘感染性休克患者对亚甲蓝药物治疗响应的潜在影响因素,有助于医生理解模型的预测过程和结果,提升医生对预测模型的信任度,促进新的治疗方法的发现。
125、3.在临床上,感染性休克患者是否使用亚甲蓝进行升压主要依赖医生的经验,有比较大的主观性,本发明第一步构建的感染性休克患者亚甲蓝治疗响应预测系统,在实施例中医院的数据中达到了较好的预测效果,预测患者对亚甲蓝响应的整体准确性达到了76%,其中预测患者对亚甲蓝无响应的准确率达到了94%,能够准确识别出对亚甲蓝无响应的患者,减少该药错误使用造成的风险。将这一预测模型应用于临床实践中,可以有助于更好的识别出受益于亚甲蓝药物的脓毒性休克患者,帮助优化该疾病的治疗方案,探索病理生理机制,改进临床实践。
本文地址:https://www.jishuxx.com/zhuanli/20240911/290625.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表