一种基于强化学习MPC的车辆轨迹跟踪与控制方法
- 国知局
- 2024-09-11 14:24:06
本发明涉及自动驾驶,具体涉及一种基于强化学习mpc的智能车辆轨迹跟踪与稳定性协同控制方法。
背景技术:
1、轨迹跟踪控制是自动驾驶车辆在行驶过程中比较常见的一种方案。在自动驾驶车辆的轨迹跟踪控制中,通过控制航向角误差和横向位置误差来保证轨迹跟踪的精度。而实际行驶过程中,由于外界环境以及车辆系统内部的干扰因素会对控制效果产生较大的影响,导致车辆稳定性的降低,严重时甚至会产生道路安全问题。因此,在设计自动驾驶车辆轨迹跟踪控制方法时,需要考虑稳定性控制因素。基于以上的分析,很有必要进行自动驾驶车辆的轨迹跟踪与稳定性协同控制方法的研究。
2、现有的轨迹跟踪方法只考虑了轨迹跟踪,而没有考虑车辆的横向稳定性控制。这导致智能车辆在中高速情况下的转向过程中可能无法确保横向稳定性,从而导致不稳定或失控。或者,另一种方案则是将轨迹跟踪控制和横向稳定性控制放置在两个独立的控制器中。这种情况下,控制器之间的相互干涉可能会影响轨迹跟踪精度和横向稳定性。
技术实现思路
1、基于上述问题,本发明公开了一种基于强化学习调节mpc的智能车辆轨迹跟踪与稳定性协同控制方法,将智能车的轨迹跟踪控制和横向稳定性控制相融合于一个mpc控制中,实现轨迹跟踪控制和横向稳定性控制的协调控制。
2、技术方案如下:
3、本发明的一种车辆轨迹跟踪与稳定性协同控制方法,包括如下步骤:
4、步骤1):建立车辆整车动力学模型以及参考模型;
5、步骤2):设计基于模型预测控制的轨迹跟踪和稳定性协调控制器,将步骤1)中建立的动力学模型作为模型预测控制算法的预测模型,建立预测方程,对车辆的理想的状态量(即参考模型计算得出的理想侧向位置、理想航向角、理想质心侧偏角和理想横摆角速度)进行跟踪,优化求解出得最优控制量;
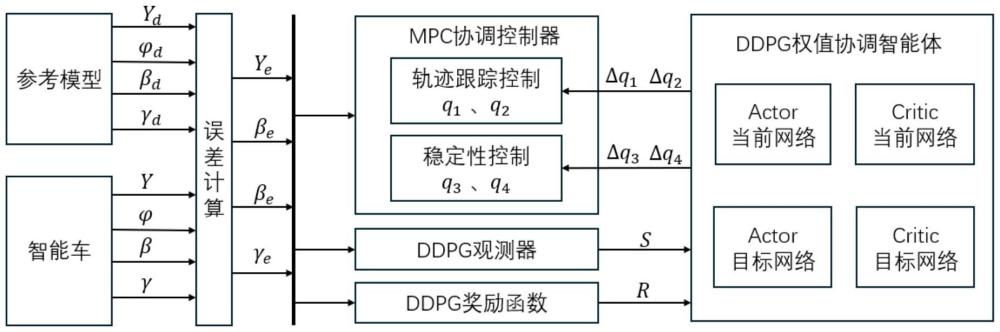
6、步骤3):使用强化学习中的deep deterministic policy gradient(ddpg)算法作为控制mpc的控制权值调节算法,完成轨迹跟踪与稳定性控制的协调控制目标。通过训练得到能够根据车辆状态实时调节mpc控制权值从而完成轨迹跟踪控制和稳定性控制协调控制的ddpg智能体。
7、进一步地,所述步骤1)具体包括:
8、建立车辆整车动力学状态方程:式中,状态量控制量u=[δfl,δfr,δrl,δrr]t,输出量状态矩阵
9、
10、控制矩阵输出矩阵c=i4×4,d=04×4。
11、式中u为车速,分别为四个车轮的侧偏刚度,由pacejka魔术轮胎公式推导得到,a为车辆质心到前轴的距离;b为车辆质心到后轴的距离;iz为车辆绕z轴的转动惯量。
12、进一步地,整车参考模型表示为:
13、理想侧向位置yd由参考路径直接得到,理想质心侧偏角:βd=0,理想航向角:理想横摆角速度:
14、进一步地,步骤2中,首先使用向前欧拉法将整车动力学模型离散化;其次,为了使四个状态量的跟踪误差尽量小,同时使车轮角度尽量小以及其变化尽量平滑,定义评价函数:j=(y-yd)tq(y-yd)+δu(t)trδu(t)+εtρε,
15、式中,为状态量的参考值,
16、式中,为状态量的控制权值矩阵,为控制量的控制权值矩阵,q1、q2为轨迹跟踪状态量控制权值,q3、q4为稳定性状态量控制权值,r1、r2、r3、r4为四个车轮的输出量控制权值,ρ为松弛因子。
17、进一步地,将评价函数转化为二次型形式:式中,x0、h和f为二次型参数矩阵,由评价函数推导计算得到,δu为控制序列;求解j得到最优控制量:u(k)=u(k-1)+δu*(k),δu*(k)为控制序列δu的第一个元素。
18、进一步地,步骤3中,使用ddpg算法训练得到能够根据车辆状态实时调节模型预测控制器控制权值的ddpg智能体,其设计过程包括:
19、设置状态空间:其中,ye=y-yd,βe=β-βd,γe=γ-γd;
20、设置动作空间:a=(δq1,δq2,δq3,δq4),对控制权值矩阵q做修订,
21、设置奖励函数:r。
22、进一步地,步骤3中,根据横向位置误差、航向角误差、质心侧偏角误差和横摆角速度误差的不同影响设计四种不同的奖励函数;当误差在允许误差范围内时,奖励为1;当误差超出允许误差范围时,奖励为一个随误差增大而增大的负值。
23、进一步地,设置侧向位置误差奖励函数:
24、航向角误差奖励函数:
25、质心侧偏角误差奖励函数:
26、横摆角速度误差奖励函数:
27、其中,ay,aβ,aγ为强度参数,dy,dβ,dγ为允许的误差范围;总奖励:
28、本发明还公开了一种基于强化学习mpc的车辆轨迹跟踪与控制系统,包括:
29、参考模型和智能车模块,输出智能车状态量的参考值,与智能车的状态量进行误差计算,得到车辆的侧向位置、质心侧偏角、航向角和横摆角速度的跟踪误差值;
30、mpc协调控制器模块,基于模型预测控制方法完成轨迹跟踪控制和稳定性控制,得到智能车四个车轮转角的最优控制量,控制智能车辆对四个状态量的参考值进行跟踪;
31、ddpg权值协调智能体模块,包括actor当前网络、critic当前网络、actor目标网络、critic目标网络、ddpg观测器和ddpg奖励函数,基于深度确定策略梯度算法,根据智能车的跟踪误差,对mpc协调控制器模块中的控制权值进行实时调节,调整轨迹跟踪控制和稳定性控制的权重。
32、进一步地,参考模型和智能车模块中,智能车的状态量:控制量:u=[δfl,δfr,δrl,δrr]t,输出量:状态空间表示为:式中,
33、
34、c=i4×4,d=04×4;
35、mpc协调控制器模块中,定义性能评价函数为系统的最优控制量为u(k)=u(k-1)+δu*(k)。
36、本发明的有益效果:
37、1.本发明公开了一种基于强化学习调节mpc的智能车轨迹跟踪与稳定性协调控制方法,特别是四轮分布式线控转向智能车辆。现有的智能车轨迹跟踪控制方法未考虑到车辆的横向稳定性,而本发明将智能车的轨迹跟踪控制和横向稳定性控制相融合于一个mpc控制中,实现轨迹跟踪控制和横向稳定性控制的协调控制。
38、2.本发明通过ddpg算法训练得到的一个智能体,能够根据车辆的实时状态对轨迹跟踪控制和横向稳定性控制二者的控制权值进行实时调节,使得智能车的轨迹跟踪和横向稳定性性能得到提升。
39、本发明的方法简单,为解决智能车系统控制拓宽了研究思路。
技术特征:1.一种基于强化学习mpc的车辆轨迹跟踪与控制方法,其特征在于,包括如下步骤:步骤1,建立车辆整车动力学模型以及参考模型;
2.根据权利要求1所述的车辆轨迹跟踪与控制方法,其特征在于,步骤1中,车辆整车动力学模型表示为:式中,状态量控制量u=[δfl,δfr,δrl,δrr]t,输出量式中,y为车辆侧向位置,β为车辆质心侧偏角,为车辆航向角,γ为车辆横摆角速度,δfl、δfr、δrl、δrr分别为四个车轮的车轮转角,下标fl代表左前轮,fr代表右前轮,rl代表左后轮,rr代表右后轮;
3.根据权利要求2所述的车辆轨迹跟踪与控制方法,其特征在于,整车参考模型表示为:
4.根据权利要求3所述的车辆轨迹跟踪与控制方法,其特征在于,步骤2中,首先使用向前欧拉法将整车动力学模型离散化;其次,为了使四个状态量的跟踪误差尽量小,同时使车轮角度尽量小以及其变化尽量平滑,定义评价函数:j=(y-yd)tq(y-yd)+δu(t)trδu(t)+εtρε,
5.根据权利要求3所述的车辆轨迹跟踪与控制方法,其特征在于,将评价函数转化为二次型形式:式中,x0、h和f为二次型参数矩阵,由评价函数推导计算得到,δu为控制序列;
6.根据权利要求1-5任意一项所述的车辆轨迹跟踪与控制方法,其特征在于,步骤3中,使用ddpg算法训练得到能够根据车辆状态实时调节模型预测控制器控制权值的ddpg智能体,其设计过程包括:
7.根据权利要求6所述的车辆轨迹跟踪与控制方法,其特征在于,步骤3中,根据横向位置误差、航向角误差、质心侧偏角误差和横摆角速度误差的不同影响设计四种不同的奖励函数;当误差在允许误差范围内时,奖励为1;当误差超出允许误差范围时,奖励为一个随误差增大而增大的负值。
8.根据权利要求7所述的车辆轨迹跟踪与控制方法,其特征在于,
9.一种基于强化学习mpc的车辆轨迹跟踪与控制系统,其特征在于,包括:
10.根据权利要求9所述的车辆轨迹跟踪与控制系统,其特征在于,参考模型和智能车模块中,智能车的状态量:控制量:u=[δfl,δfr,δrl,δrr]t,输出量:状态空间表示为:式中,
技术总结本发明公开了一种基于强化学习MPC的车辆轨迹跟踪与控制方法,包括S1,建立车辆整车动力学模型以及参考模型;S2,设计基于模型预测控制的轨迹跟踪和稳定性协调控制器,将所述动力学模型作为预测模型,跟踪车辆参考模型得到的理想状态量,优化求解出最优控制量;S3,使用强化学习中的DDPG算法作为控制MPC的控制权值调节算法,完成轨迹跟踪与稳定性控制的协调控制目标;通过训练得到能够根据车辆状态实时调节MPC控制权值从而完成轨迹跟踪控制和稳定性控制的协调控制的DDPG智能体。本发明将智能车的轨迹跟踪控制和横向稳定性控制相融合于一个MPC控制中,实现轨迹跟踪控制和横向稳定性控制的协调控制,为解决智能车系统控制拓宽了研究思路。技术研发人员:张寒,刘开华,湛嘹旸,许可,李源浩受保护的技术使用者:南京航空航天大学技术研发日:技术公布日:2024/9/9本文地址:https://www.jishuxx.com/zhuanli/20240911/290580.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表