基于深度强化学习算法的风力发电机叶片无人机巡检方法
- 国知局
- 2024-09-11 14:45:19
本发明属于无人机巡检,具体是涉及一种基于深度强化学习算法的风力发电机叶片无人机巡检方法。
背景技术:
1、面对当前全球能源转型的趋势,各国积极支持推动风电行业的发展。但是,由于风力发电机叶片暴露在自然环境中,受到各种自然因素的影响导致叶片损伤,不仅会影响能量输出减少,还可能引起风机失衡,缩短设备寿命。因此,对叶片的维护和检查工作变得尤为重要。
2、近年来,随着无人机技术的飞速发展,使用四旋翼无人机自主巡检风机叶片的方法已经成为主流,如中国专利公开(公告)号为cn116906276a的专利,提供了一种针对风机叶片的智能巡检方法,该发明包括确定无人机的巡检路径、图像信息采集和故障类型判断,但叶片损伤图像的清晰度受到无人机稳定程度的影响,在复杂风场环境下无人机稳定程度有限,在很大程度上会影响图像信息的采集。中国专利公开(公告)号为cn116906276a的专利,公开了一种针对风机叶片的智能巡检方法,根据建立的待巡检风机的模型,确定巡检路径,使用无人机进行自主巡检,但在复杂风场环境下受风场扰动影响,无人机会偏离规划的巡检路径稳定程度有限。
3、为了提高无人机稳定性,降低维护成本,探索以深度强化学习算法用于无人机巡检控制为出发点,研究和改进td3算法用于复杂风场环境下无人机巡检控制具有重要意义。
技术实现思路
1、本发明公开了一种基于深度强化学习算法的风力发电机叶片无人机巡检方法,适用于风力发电机叶片巡检任务,能控制无人机高效稳定巡检,其能够在奖励稀疏的环境下,综合考虑能耗、稳定性等问题,完成无人机对风机叶片的自主巡检任务。
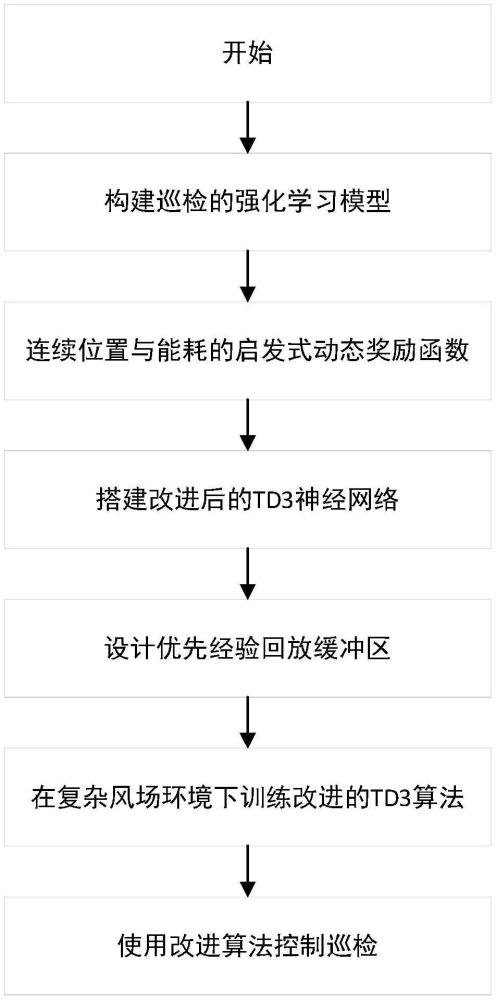
2、一种基于深度强化学习算法的风力发电机叶片无人机巡检方法,其包括以下步骤:
3、步骤1:构建无人机巡检风力发电机叶片任务的强化学习模型;
4、步骤2:定义基于连续位置和能耗的启发式动态奖励函数;
5、步骤3:搭建改进的双延迟深度确定性策略梯度td3算法;
6、步骤4:在复杂风场环境下训练算法以控制无人机实现叶片巡检任务。
7、作为优选,步骤1具体包括以下步骤:
8、步骤1-1:对无人机巡检风力发电机叶片的强化学习模型(s,a,p,r,γ)进行构建,其中s为环境的所有可能集合,在强化学习框架下,s包含无人机巡检所需的全部信息;a为无人机在每个状态下可以采取的所有可能的动作集合;p为状态转移概率,在当前状态下采取动作后转移到另一个状态的可能性;r为奖励函数;γ为折扣因子。无人机在环境中的可行性空间为h×l×w的三维环境空间,h表示该可行性空间的高度;l为该空间的长度,w为该空间的宽度,此区域为无人机巡检叶片的可行性空间;
9、步骤1-2:定义强化学习模型的状态空间;设定状态为:s=[sl,sa,sv,sw,sp],其中,状态sl=[x,y,z]表示无人机在环境中的三维坐标位置;表示无人机的欧拉角,为无人机的翻滚角、θ为无人机的俯仰角、ψ为无人机的偏航角,将无人机的欧拉角限制在合理范围内,超过设定范围代表无人机运动激烈则终止:sv=[vx,vy,vz]表示无人机的运动速度在三维坐标系下的速度分量;sw=[ωx,ωy,ωz]表示无人机的角速度在三维坐标系下的角速度分量;sp=[δx,δy,δz]表示无人机当前位置坐标距离待巡检点三维坐标的坐标差;
10、步骤1-3:定义强化学习模型的动作空间:无人机的输出动作a表示无人机在每个状态下可以采取的所有可能的动作集合;输出动作a=[w1,w2,w3,w4],其中,w1…w4表示无人机四个旋翼的转速;对无人机四个旋翼的转速以及无人机的加速度进行约束,防止无人机激烈运动:wi∈[wmin,wmax],其中,wmin、wmax分别表示无人机旋翼的最低、最高转速;ai∈[amin,amax]分别代表无人机的最小和最大加速度。
11、作为优选,步骤2具体包括以下步骤:
12、步骤2-1:定义奖励函数r,利用无人机传感器获取无人机到待巡检点的距离,通过设置连续位置与能耗的启发式动态奖励函数,控制无人机以最少能耗和最稳定的方式对风力发电机叶片进行自主巡检,通过对无人机设置避障奖励和完成任务奖励,加快训练过程;
13、步骤2-2:设置连续位置启发式动态奖励函数rp如下式所示:
14、
15、其中,η是奖励系数,dt是当前状态下无人机到待巡检点的距离,dt+1是下一状态下无人机到待巡检点的距离。当无人机执行当前动作时,如果下一状态更接近待巡检点,则将获得正奖励,如果下一状态远离待巡检点,则给予惩罚,距离越远惩罚越大;
16、步骤2-3:在本技术无人机巡检风机叶片的任务中,由于风机叶片长度较长,且风机塔筒的高度较高一般在100m左右,为了延长无人机的飞行时间,需要减少电池电量的消耗。为此,在本技术无人机巡检任务中,还需设计关于能耗的奖励函数,连续能耗奖励函数re为:re=t+0.3·v2+0.5·a,其中,t为无人机总运动时长,v2与无人机动能成正比,通过调整速度进而鼓励低能耗的运动,a为无人机的加速度,与速度类似,加速度的增加通常会导致能量消耗的增加(例如,通过更多的推力来加速)。因此在奖励函数中,a越大,能耗惩罚越大;
17、步骤2-4:当无人机与待巡检点的距离小于0.5m时,则认为无人机已完成飞行任务,并获得100的正奖励rs;
18、步骤2-5:设置避障奖励函数为rc=0.5-d,其中,d为当前无人机到待巡检点的距离;
19、综合无人机连续位置奖励函数、能耗奖励函数、完成任务奖励与避障奖励得到奖励函数r为:r=rp+re+rs+rc
20、步骤2-6:定义折扣因子γ:折扣因子γ取值范围为(0,1),用于计算奖励累计值,γ越大,表示越注重长期回报。
21、作为优选,步骤3具体包含以下步骤:
22、步骤3-1:改进的双延迟深度确定性策略梯度算法使用6个网络,4个critic网络和2个actor网络,2个actor网络将状态作为输入,4个critic网络将状态和动作作为输入,状态由15个元素构成分别是四旋翼无人机的三维坐标位置、无人机的欧拉角、无人机在3个坐标上的线速度和角速度以及当前坐标与待巡检点位置坐标的坐标差。网络的输出有所不同,对于4个critic网络,采用对决网络结构设计,输出优势值和状态值,而对于2个actor网络,将有4个输出,即四旋翼无人机的四个电机的转速。其中,critic网络,将状态输入经过一个128层的全连接层后分为两个部分一个部分经过64层的全连接层输出为状态值;另一个经过64层的全连接层后与经过128层、64层的全连接层的动作输入相连接输入到64层全连接层后输出为优势值,如图2。actor网络,是由2个具有relu激活的128个节点和64个节点的隐藏层和一个具有tanh激活函数的输出层组成的,
23、步骤3-2:构建优先经验回放缓冲池:引入td_error,决定经验被抽样的概率,高td_error的经验被认为是更有价值的,因为它表示无人机对这些经验的预测有很大的偏差,从这些经验中学习有可能带来更大的价值函数的更新。作为优选,步骤4,在复杂风场环境下训练算法以控制无人机实现叶片巡检任务,具体包含以下步骤:
24、步骤4-1:在ue4和airsim仿真环境下构建风机模型与复杂风场环境,风场环境按照无人机抗风能力国标要求进行设计,由三种风场组成:持续风、阵风和切向风给;在搭建的仿真环境下训练改进的td3算法;
25、步骤4-2:初始化仿真环境和神经网络模型,仿真环境包括风场环境和无人机自主起飞到起始点保持悬停;对于神经网络,critic网络采用了对决网络结构将q值函数分解为状态值函数和优势值函数,数学表达式如下:
26、
27、设置算法的超参数:学习率、单个回合内最大动作步数,最大训练回合数、优先经验池的最大容量、软更新参数以及噪声参数等;
28、步骤4-3:在每个训练步骤中,执行以下操作:
29、选择具有探索噪声的动作,执行动作a并得到奖励r,观察无人机新状态s`:s`,r,done=step(a)
30、为当前转换计算优先级,计算公式如下:
31、td-error=|q1(s,a)-r-γ×min(q1_tar(s',π_tar(s')),q2_tar(s',π_tar(s')))|
32、priority=(td-error+ε)×α
33、其中,td_error用于衡量当前估计值和目标值之间的差异,q1(s,a)critic_1网络对于当前状态s和选择的动作a的估计值,r是执行动作a后得到的奖励,γ是折扣因子用于衡量未来奖励的重要性,min(q1_tar(s',π_tar(s')),q2_tar(s',π_tar(s')))表示下一个状态s`使用目标策略π_tar选择动作时,所估计的critic网络的最小q值;
34、优先级是根据td_error计算的用于指导经验回放时的采样过程,公式中,将td_error加上极小的正数ε确保每个样品都有优先级;
35、随后,将经验元组(s,a,r,s`)存入优先经验回访池,更新当前状态为新状态;
36、进行网络更新,方式如下:
37、从优先经验回放池中根据优先级采样最小批次的样本,如下式所示,进行经验和网络参数的更新:
38、transitions,indices,weights=d.sample(batch_size,β)
39、其中,transitions是采样得到的经验样本,包含状态转换的元组,indices是索引用于后续更新经验的优先级,weights是重要性权重,batch_size是批量大小,β是重要性采样参数,用于调整经验采样时的权重;
40、更新critic网络:
41、其中,lcritic表示critic网络的损失函数,n是批量大小,wi是样本i的重要性采样权重,用于调整每个样本对损失函数的贡献,表示样本i的td_error平方,衡量网络的预测误差;
42、采用延迟更新actor网络和目标网络:
43、
44、其中,▽θl表示损失函数关于actor网络参数的梯度,e表示期望,表示critic网络关于动作a的梯度,表示actor网络关于参数θ的梯度;
45、φ'i←τφi+(1-τ)φ'i
46、θ′←τθ+(1-τ)θ′
47、其中,τ决定了当前参数和目标参数的权衡,用于控制滑动平均更新的超参数,φi是当前critic网络的参数,φ'i是目标critic网络的参数,θ是当前actor网络的参数,θ′是目标actor网络的参数,通过滑动平均更新策略网络和价值网络的目标参数,以提高训练的稳定性和效率;
48、更新经验的优先级:
49、new_priorities=|y-q1(s,a)|+ε
50、d.update_priorities(indices,new_priorities);
51、步骤4-4:设置超参数并在设计的仿真环境下控制无人机实现巡检风机叶片任务,对比改进的td3算法和td3算法的控制效果。
52、本发明的有益效果是:
53、针对目前无人机在复杂环境下巡检风力发电机叶片不稳定的问题,本技术提出了一种基于深度强化学习算法的无人机控制方法,在复杂环境下具有更好的适应性和稳定性,其设计思路是先创建无人机巡检风力发电机叶片的强化学习模型,定义无人机在环境中的可行性空间;状态空间,包含了无人机在环境中的三维坐标位置、欧拉角、速度、角速度和距离这15个元素;以及无人机的动作空间,为防止无人机采取激进运动,限制无人机的欧拉角、速度、加速度的取值范围。其次针对巡检任务需求设计了连续位置和能耗的启发式动态奖励函数以及完成任务和避障的奖励函数控制无人机以最稳定、最少能耗路径对风力发电机叶片进行自主巡检。针对风机巡检任务,改进td3深度强化学习算法的神经网络结构、优先经验回放技术,加速训练过程。最后,在搭建的风机和风场仿真环境下,对比td3算法和改进的td3算法的控制效果,实验结果证明,在受到复杂风场扰动时,基于改进td3算法控制无人机巡检的方式具有更好的稳定性和鲁棒性,路径的平滑性更好、偏离程度更小且修正动作更少。
本文地址:https://www.jishuxx.com/zhuanli/20240911/292032.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。