一种无人艇群的数据通信和协同方法
- 国知局
- 2024-09-11 15:00:13
本发明属于通信,尤其涉及一种无人艇群的数据通信和协同方法。
背景技术:
1、多智能体(如无人机、无人艇)间的通信尤为重要。2016年,j.n.foerster等人最先提出基于通信机制的多智能体强化学习交互方式rial,先将智能体的决策网络一分为二,动作选择网络和消息网络。之后,作者又提出dial算法,增加了反馈循环以提升鲁棒性。2016年,facebook ai research团队提出了commnet,使用了集中训练集中执行框架,给出了分层分组广播消息的想法。2017年,peng等人使用双向rnn作为通信通道,使用基于策略梯度的更新方法进行参数更新,提出了bicnet算法,但是该算法要求获取全局状态进行训练,在真实场景中有一定的困难性。2018年,北京大学团队提出了atoc算法,该算法不同于上述预定义式的通信方式,最先放松了限制,让智能体决定是否通信、何时通信和与哪一个智能体通信。算法采用了actor-critic框架,更新过程基于ddpg算法。2019年,d.kim等人又再次对atoc算法进行改进,考虑了真实场景中通信的信道是有限性,引入了通信领域的medium access control对智能体间发送的信息进行了约束;2019年,facebook airesearch团队提出了tarmac算法,该算法引入了多头注意力机制对发送信息进行融合,基于局部状态和历史信息分别生成查询向量和键值对信息,对发送信息进行基于自注意机制的高效选取。2020年,哈佛大学研究团队提出了tmc算法,引入了信息增益值得概念,开始尝试避免不必要的收发操作,进而做到高效的通信。
2、上述方法只能针对已有的信息进行基于注意力机制的高效选取,缺乏对信息的对抗观测和基于自身观测对于整个智能系统关系的图建模,进而生成更加准确和表达力强的信息。另一方面,在多智能体的通信交互过程中,缺乏对于真实场景下间断通信,通信中断保障等问题的研究,只能在特定的仿真平台中运行,更缺乏到真实场景中的迁移能力。
技术实现思路
1、针对开放环境细节众多、任务繁杂、难以从简单仿真环境进行直接迁移的问题,本申请在构建多智能体系统图模型的基础上将智能实体间的信息融合,并根据动作价值函数计算反馈值,通过决策函数模拟出实体针对所接受的不同信息做出不同的决策,然后对决策进行反馈,计算决策的奖励期望,构建面向环境突变的多智能体不确定图模型和动态环境下的多智能体时序图模型。
2、为实现上述目的,本申请公开的无人艇群的数据通信和协同方法,包括以下步骤:
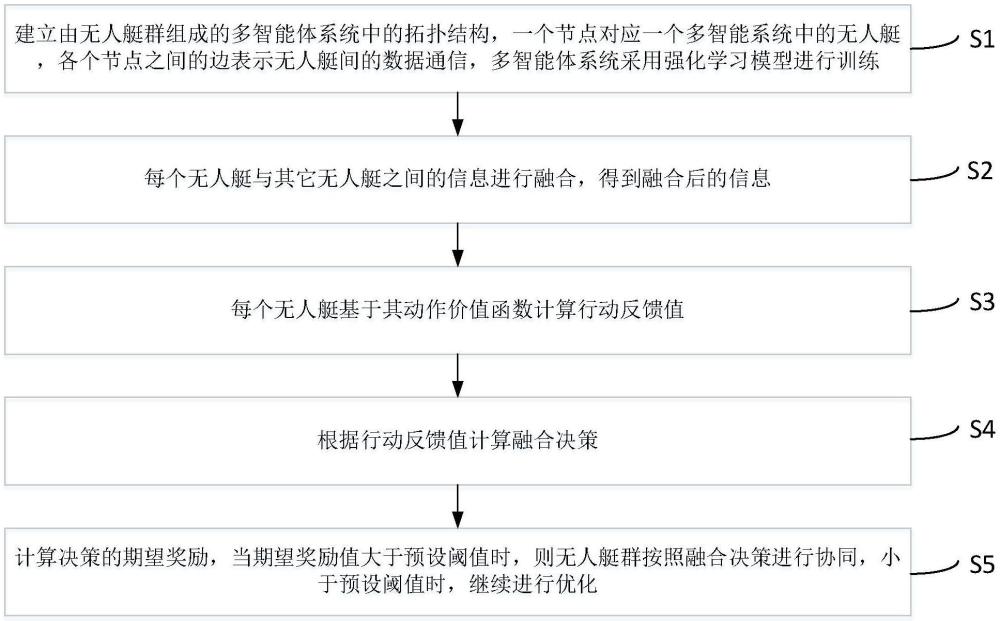
3、建立由无人艇群组成的多智能体系统中的拓扑结构,一个节点对应一个多智能系统中的无人艇,各个节点之间的边表示无人艇间的数据通信;
4、每个无人艇与其它无人艇之间的信息进行融合,得到融合后的信息;
5、每个无人艇基于其动作价值函数计算行动反馈值;
6、根据行动反馈值计算融合决策;
7、计算决策的期望奖励,当期望奖励值大于预设阈值时,则无人艇群按照融合决策进行协同,小于预设阈值时,继续进行优化。
8、进一步地,计算无人艇i与无人艇j的融合信息fij如下:
9、
10、其中,σ是激活函数,k是通信链路总数,表示无人艇i与无人艇j之间在通信链路k上的信息传递概率,表示无人艇i与无人艇j之间在通信链路k上传递的共享信息,是无人艇i的局部观测矩阵,n是矩阵的维数。
11、进一步地,根据动作价值函数计算反馈值如下:
12、
13、表示无人艇i根据t时刻与无人艇j之间在通信链路k上的通信信息基础上的动作价值函数,ai,t表示无人艇i在时刻t的动作,si,t表示无人艇i在时刻t的状态,表示无人艇i根据t-1时刻与无人艇j之间在通信链路k上的通信信息基础上的动作价值函数,ai,t―1表示无人艇i在时刻t-1的动作,si,t―1表示无人艇i在时刻t-1的状态,q(,)是q函数,r(,)是奖励,当y(i)>1时,为正反馈,当y(i)<1时,为负反馈。
14、进一步地,根据正反馈、负反馈融合计算决策;
15、
16、为正反馈,为负反馈,μ0和μ1分别是负反馈和正反馈的均值,σ0和σ1分别是负反馈和正反馈的方差,aggregate为融合函数。
17、进一步地,得到决策的期望奖励为:
18、e[rt|st=s,dt=d](ai,t)
19、ai,t表示无人艇i在t时刻的动作,上式表示转移到状态st下且采取决策dt时获得的期望奖励。
20、本申请的有益效果如下:
21、本申请在构建多智能体系统图模型的基础上将智能实体间的信息融合,并根据动作价值函数计算反馈值,通过决策函数模拟出实体针对所接受的不同信息做出不同的决策,然后对决策进行反馈,计算决策的期望奖励,利用期望奖励来评估和融合不同特征的重要性,使得模型能够更有效地处理不完全或不确定的信息。
技术特征:1.一种无人艇群的数据通信和协同方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的无人艇群的数据通信和协同方法,其特征在于,计算无人艇i与无人艇j的融合信息fij如下:
3.根据权利要求2所述的无人艇群的数据通信和协同方法,其特征在于,根据动作价值函数计算反馈值如下:
4.根据权利要求3所述的无人艇群的数据通信和协同方法,其特征在于,根据正反馈、负反馈融合计算决策;
5.根据权利要求4所述的无人艇群的数据通信和协同方法,其特征在于,得到决策的期望奖励为:
技术总结本发明公开了一种无人艇群的数据通信和协同方法,包括步骤:建立由无人艇群组成的多智能体系统中的拓扑结构;每个无人艇与其它无人艇之间的信息进行融合,得到融合后的信息;每个无人艇基于其动作价值函数计算行动反馈值;根据行动反馈值融合计算决策;计算决策的期望奖励,当奖励期望值大于预设阈值时,则无人艇群按照融合决策进行协同,小于预设阈值时,继续进行优化。本申请将智能实体间的信息融合,并根据动作价值函数计算反馈值,通过决策函数模拟出实体针对所接受的不同信息做出不同的决策,然后对决策进行反馈,计算决策的奖励期望,利用奖励期望来评估和融合不同特征的重要性,使得模型能够更有效地处理不完全或不确定的信息。技术研发人员:黄金才,宋惟韬,程光权,黄魁华,杜航,张勇受保护的技术使用者:中国人民解放军国防科技大学技术研发日:技术公布日:2024/9/9本文地址:https://www.jishuxx.com/zhuanli/20240911/292828.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表