一种基于人工智能的数据分类分级方法与流程
- 国知局
- 2024-09-14 14:41:30
本发明涉及数据分类,特别涉及一种基于人工智能的数据分类分级方法。
背景技术:
1、随着医疗领域迅速积累大量数据,这些数据的规模和复杂性超出了传统分析方法的处理能力。采用人工智能技术可以通过自动化特征提取和模式识别来处理这些庞大的数据集,为医疗数据的分类和分级提供高效解决方案。然而,医疗数据分类分级的准确性和一致性对于诊断和治疗至关重要。当前的技术主流是构建能够持续学习和适应的数据分类分级模型,以提供更加可靠的分类分级结果。然而,数据分类分级模型的构建仍然面临许多挑战,其中如何在构建过程中进行调优是需要重点解决的问题。
2、现有方案在处理多样的医疗数据时,一些样本会因为存在缺失值而无法被使用,这就会使本就稀少的数据变得更少。在构建数据分类分级深度神经网络模型的过程中,经常会因为样本类别不均衡,且大量类别中的可训练样本非常少等原因导致模型过拟合,即:模型在训练数据上表现良好,但是在新的未见过的数据上泛化能力差。为了解决在医疗数据中存在的过拟合问题,本发明结合医疗数据的特点,设计了一种k-近邻插补的数据补全方法,以充分利用珍贵的医疗数据。还创新性地提出了一个奖励函数正则化方法,该正则化旨在直接激励模型主动追求理想的状态,如模型简单性、分类置信度等。通过在损失函数中引入奖励项,模型在优化过程中将自主权衡模型复杂度和任务相关性能指标,从而获得更佳的防止过拟合的效果。
技术实现思路
1、本发明的目的在于提供一种基于人工智能的数据分类分级方法,用于解决上述至少一个技术问题,其采用k-近邻插补方法,创新的奖励函数正则化方法,能够在医疗数据多分类场景中解决模型过拟合的问题,提高了数据分类分级模型的准确度。
2、本发明的实施例是这样实现的:
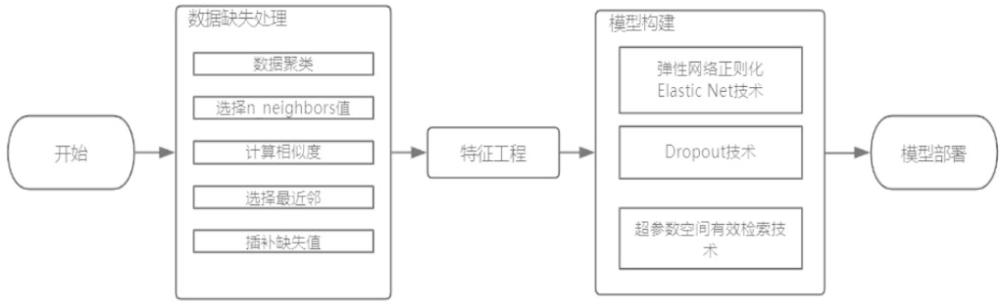
3、一种基于人工智能的数据分类分级方法,其包括:
4、采集原始医疗数据,采用k均值聚类算法对所述原始医疗数据进行预处理,分配到不同的簇中,得到聚类医疗数据集。
5、对所述聚类医疗数据集采用k-近邻插补方法进行数据补全,得到完整聚类医疗数据集。
6、利用卷积神经网络和基于奖励函数的正则化技术,构建医疗数据预测模型。
7、采用所述完整聚类医疗数据集对所述医疗数据预测模型进行模型训练。
8、结合贝叶斯优化算法,对所述医疗数据预测模型进行超参数调优。
9、将待分类分级的医疗数据输入超参数调优后的所述医疗数据预测模型,得到分类分级结果。
10、在本发明较佳的实施例中,上述基于人工智能的数据分类分级方法中,所述采集原始医疗数据,采用k均值聚类算法对所述原始医疗数据进行预处理,分配到不同的簇中,得到聚类医疗数据集包括:
11、从确定的数据源中采集原始医疗数据,所述数据源包括医院数据库、电子健康记录、医学影像数据库和生物标志物数据中的至少一种。
12、对所述原始医疗数据进行数据标准化处理,转换为统一形式的标准医疗数据。
13、确定聚类数目k,将所有所述标准医疗数据分成k个簇。
14、执行距离分配算法,将每个所述标准医疗数据对应的数据点分配到最近的聚类中心。
15、重新计算每个簇的均值,更新聚类中心,直到聚类中心位置的变化小于设定的阈值,使得每个数据点被分配到一个指定的簇中,所有所述数据点对应的所述标准医疗数据根据簇标签进行分类,形成聚类医疗数据集。
16、其技术效果在于:采用k均值聚类算法对标准化后的医疗数据进行聚类处理,通过距离分配算法将每个数据点分配到最近的聚类中心,并迭代更新聚类中心,直至收敛,确保了聚类结果的准确性和稳定性,使得每个数据点都能被分配到一个合适的簇中。最终得到的聚类医疗数据集反映了数据内在的模式和结构,每个簇代表了具有相似特征和属性的数据点的集合,这种集群化的数据集有助于后续的数据分析和模型建立,能够更好地理解和利用医疗数据的内在关联性。
17、在本发明较佳的实施例中,上述基于人工智能的数据分类分级方法中,所述对所述聚类医疗数据集采用k-近邻插补方法进行数据补全,得到完整聚类医疗数据集包括:
18、检查并识别所述聚类医疗数据集的原始数据矩阵x中缺失值的位置。
19、通过交叉验证选择n_neighbors的值。
20、使用每个所述缺失值的n_neighbors个最近邻进行插补,计算得到插补值。
21、将计算得到的所述插补值补入所述原始数据矩阵x中,,得到完整聚类医疗数据集。
22、其技术效果在于:k-近邻插补方法能够有效地填补原始数据矩阵中的缺失值,通过分析每个缺失值周围的n_neighbors个最近邻来计算插补值,保持数据集的完整性,确保所有数据都可以被纳入分析和建模中,避免了因数据缺失而导致的信息损失和偏差;通过插补缺失值,可以减少数据集中的偏差和不完整性对分析结果的影响,为后续建立预测模型提供了更加准确和全面的数据基础,能够更稳定地支持数据分析和模型构建过程。
23、在本发明较佳的实施例中,上述基于人工智能的数据分类分级方法中,所述使用数据集中每个缺失值的n_neighbors个最近邻进行插补,计算得到插补值包括:
24、计算所述聚类医疗数据集中所有样本之间的n×n的距离矩阵d,矩阵中的每个元素表示样本和样本之间的距离,计算公式为,其中,n为样本的数量,m是特征的数量,是样本i在第k个特征上的值,是样本j在第k个特征上的值。
25、对于每个缺失值,找到其在特征j上非缺失值样本的最近邻样本集合。
26、计算最近邻样本和之间的权重值,计算公式为。
27、计算最近邻样本的加权均值,计算公式为,其中,为最近邻样本在特征j上的值。
28、对最近邻样本的值乘以对应权重,除以所有权重之和,得到插补值。
29、其技术效果在于:基于数据集中每个缺失值的n_neighbors个最近邻进行插补的方法,通过充分利用样本间的相似性和权重信息,有效提高了插补过程的准确性和数据的完整性。
30、在本发明较佳的实施例中,上述基于人工智能的数据分类分级方法中,所述利用卷积神经网络和基于奖励函数的正则化技术,构建医疗数据预测模型包括:
31、定义医疗数据预测模型的神经网络结构,包括输入层、第一卷积层、第一最大池化层、第二卷积层、第二最大池化层、第一全连接层、第一dropout层、第二全连接层、第二dropout层和输出层。
32、所述输入层的大小为医疗数据包含的特征数量。
33、所述第一卷积层应用多个滤波器提取输入数据的低级特征,采用relu激活函数,输出与输入相同的张量维度,通道数根据滤波器数目增加。
34、所述第一最大池化层的步幅与池化窗口的大小相同,输出张量的高度和宽度减半,通道数保持不变。
35、所述第一dropout层在训练过程中随机断开指定比例的神经元连接,防止过拟合。
36、所述第一全连接层的输入为经过所述第一dropout层处理的一维向量,激活函数使用relu。
37、所述第二卷积层提取高级特征,采用relu激活函数,输出张量的维度不变,增加通道数。
38、所述第二最大池化层的步幅与池化窗口的大小相同,输出张量的高度和宽度减半,通道数保持不变。
39、所述第二dropout层在训练过程中随机断开指定比例的神经元连接。
40、所述第二全连接层的输入为经过所述第二dropout层处理的一维向量,采用relu激活函数,输出张量的维度不变,增加通道数。
41、所述输出层的输入为经过所述第二全连接层处理的一维向量,采用softmax激活函数,输出的特征数量为分类的类别数目。
42、在训练损失函数中加入基于奖励函数的正则化项,得到修正后的医疗数据预测模型。
43、其技术效果在于:在损失函数中引入的奖励函数,旨在直接激励模型主动追求理想的状态,如模型简单性、分类置信度等。具体而言,我们将原有损失函数中的惩罚项替换为奖励项,从而得到新的损失函数形式。通过在训练过程中对医疗数据预测模型进行主动纠偏,提升泛化能力。
44、在本发明较佳的实施例中,上述基于人工智能的数据分类分级方法中,在训练损失函数中加入基于奖励函数的正则化项包括:计算标准损失函数,其中,是分类损失函数,是对模型权重w的惩罚项,是惩罚项的权重。
45、用奖励函数函数替换惩罚项,得到综合损失函数,是控制奖励项的权重。
46、奖励函数定义为,其中,为控制稀疏性和分类清晰度权重的超参数,度量模型的稀疏性,定义为,度量模型对当前样本分类结果的置信度,定义为。
47、计算综合损失函数对每一层权重的梯度。
48、得到最终的权重更新公式,其中,η为学习率。
49、其技术效果在于:当模型的稀疏性较好,且预测输出的清晰度越高时,reward(w,y_pred)的值越大,导致损失函数越小。通过这种奖励函数的设计,我们不仅鼓励模型获得简单的稀疏解,同时也直接奖励了模型对样本的"高置信度"分类预测。这种机制有望提高模型在分类任务上的表现,防止过度拟合。
50、在本发明较佳的实施例中,上述基于人工智能的数据分类分级方法中,所述采用所述完整聚类医疗数据集对所述医疗数据预测模型进行模型训练包括:
51、读取完整聚类医疗数据集,其中,为第i个样本的特征向量,为第i个样本的标签。
52、将所述完整聚类医疗数据集分为训练集和验证集。
53、重复使用所述训练集进行前向传播、计算损失、反向传播和参数更新的步骤,直至损失函数收敛或达到预定的训练次数。
54、使用所述验证集评估模型的性能并调整模型参数,保存训练好的模型。
55、其技术效果在于:采用完整聚类医疗数据集进行模型训练,能够优化数据利用、提高泛化能力、增强模型适应能力。
56、在本发明较佳的实施例中,上述基于人工智能的数据分类分级方法中,所述结合贝叶斯优化算法,对所述医疗数据预测模型进行超参数调优包括:
57、定义超参数空间中需要调优的超参数, 使用随机选择或拉丁超立方采样法,从超参数空间中选择初始点,训练模型并计算所述初始点的目标函数值。
58、构建高斯过程代理模型,使用初始点的超参数值和对应的目标函数值来拟合高斯过程模型,训练高斯过程模型。
59、选择获取函数,在超参数空间中找到使获取函数最大的点作为新超参数组合,在新超参数组合下训练所述医疗数据预测模型,计算所述获取函数的目标函数值,更新数据集和高斯过程模型,并使用更新后的数据集和高斯过程模型重复训练所述医疗数据预测模型,直至模型收敛。
60、其技术效果在于:贝叶斯优化算法通过高斯过程代理模型(gaussian process)来建模目标函数(通常是验证集的损失函数),从而在超参数空间中进行高效的搜索。相比于传统的网格搜索或随机搜索方法,贝叶斯优化能够根据已有的超参数取值和对应的模型性能,动态地调整下一个尝试的超参数组合,从而更快地找到性能最优的超参数组合。结合贝叶斯优化算法对医疗数据预测模型进行超参数调优,能够有效提升模型的性能表现,加速模型的收敛过程,从而为医疗数据的分类和分级提供更为精确和可靠的预测结果。
61、在本发明较佳的实施例中,上述基于人工智能的数据分类分级方法中,所述将待分类分级的医疗数据输入超参数调优后的所述医疗数据预测模型,得到分类分级结果包括:
62、采集待分类分级的医疗数据,将所述待分类分级的医疗数据处理为与所述完整聚类医疗数据集格式一致。
63、将处理后的所述待分类医疗数据输入超参数调优后的所述医疗数据预测模型中。
64、使用所述医疗数据预测模型对待分类数据进行推断,通过前向传播计算输出层的预测结果,输出类别标签或类别概率。
65、根据所述医疗数据预测模型的输出结果,确定待分类医疗数据的分类分级。
66、其技术效果在于:通过将医疗数据预测模型应用于待分类的医疗数据,可以在实际临床或健康管理场景中发挥重要作用。
67、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如前所述的基于人工智能的数据分类分级方法。
68、本发明实施例的有益效果是:
69、对所述聚类医疗数据集采用k-近邻插补方法进行数据补全,得到完整聚类医疗数据集。减少了珍贵的医疗数据的浪费,同时也降低了模型过拟合的概率。
70、本发明在医疗数据预测模型的构建过程中,引入了基于奖励函数的正则化方法,它为模型留有更大的自由度,引导模型主动追求简单性和决策清晰度等理想状态,而不是被动地受到惩罚和压制。同时,奖励函数的设计也可以灵活地融入领域知识和模型解释性等先验信息,使得正则化过程更加合理自然。
71、本发明通过贝叶斯优化算法对医疗数据预测模型的超参数进行调优,能够更快地找到最优的超参数组合,进一步提高了模型的性能表现和预测准确性。相比传统的网格搜索或随机搜索方法,本发明的贝叶斯优化能够在有限的计算资源下,有效地优化模型的性能。
72、通过将优化后的医疗数据预测模型应用于待分类的医疗数据,本发明能够快速且准确地输出分类或分级结果。可以直接应用于实际的临床决策和健康管理中,帮助医护人员更好地理解和利用医疗数据,指导个性化的治疗方案和健康干预措施。
本文地址:https://www.jishuxx.com/zhuanli/20240914/295542.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表