一种适应丘陵山地无人作业底盘的姿态协同控制方法
- 国知局
- 2024-09-14 14:58:01
本发明涉及底盘姿态控制,尤其涉及一种用于丘陵山地等复杂路况的无人作业底盘的姿态协同控制方法。
背景技术:
1、由于丘陵山地复杂的工作环境,农业与林业的生产机械化面临着严峻的挑战。在丘陵山地复杂恶劣的工况下,无人作业底盘工作稳定性差,工作效率低。这类地区的路况表面,多有岩石与坑洼,对底盘的动力与悬架系统性能要求高。而传统的被动悬架系统多适用于平坦的路况环境,对于丘陵山地表面坑洼不平的路况环境,被动悬架系统性能不足,难以保证作业底盘的工作平顺性与稳定性。相较之下,主动悬架系统能通过传感器实时检测路况,并通过算法控制作动器,以适应复杂路况并显著提升无人作业底盘工作的平顺性、操作稳定性及安全性。因此,主动悬架系统对于提高复杂路况无人作业底盘行驶的稳定性与作业效率至关重要。
2、近年来,深度强化学习(drl)在解决传统控制方法对数学模型精度的依赖问题上展现了显著优势,特别是在优化控制问题上。深度强化学习算法已开始应用于主动和半主动悬挂系统的控制,以此提高作业底盘的工作稳定性。
3、对于主动悬架的控制,现有研究主要是针对1/4主动悬架系统进行的。虽然对车辆的垂向加速度起到了很好的抑制作用,提高了车辆平顺性,但未对整机进行分析,忽略了整机的俯仰角、侧倾角、垂向位移等姿态指标和不同自由度对整机工作平稳性带来的影响。针对1/4模型的局限性,一些学者建立了七自由度的悬架振动模型,采用不同控制策略进行整机姿态优化。有的算法简单易实现,如pid、lqr算法等,但其控制效果受限于模型的精度,且鲁棒性较差;而鲁棒性好,控制精度高的控制算法,往往控制器的设计相对复杂,且对算法的依赖性大。多自由度的整机悬架振动模型考虑了整机姿态,但其动力学模型较为复杂,存在多种耦合关系,从数学模型上手设计控制器十分困难。最近,随着深度强化学习算法的发展,深度强化学习在解决传统控制方法对数学模型精度的依赖问题以及优化控制问题方面,体现了显著的优势。国内外许多学者也基于深度强化学习算法,针对主动和半主动悬架系统的控制,取得了诸多成果,提高了车辆底盘工作的稳定性。这些研究证实了深度强化学习算法在主动悬架控制上的有效性与实用性,但目前这些应用多基于1/4悬架模型,整机姿态的优化控制应用十分少见。
技术实现思路
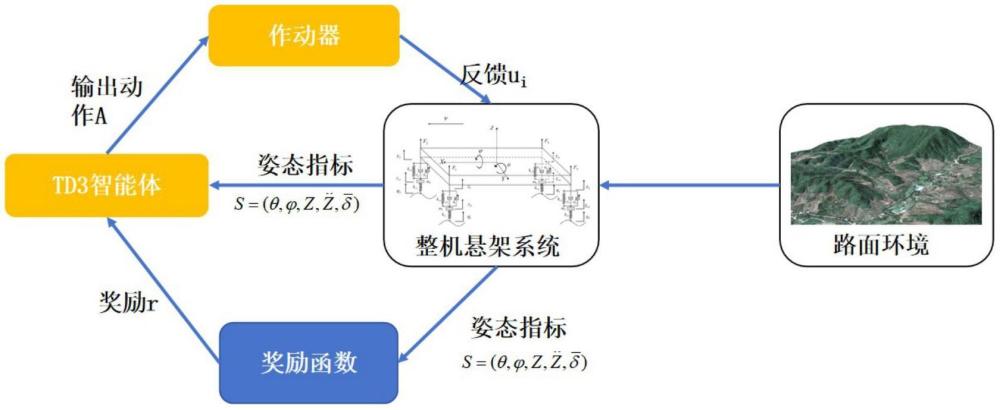
1、本发明拟提出一种适应丘陵山地无人作业底盘的姿态协同控制方法,以无人作业底盘作为研究对象,基于深度强化学习中的双延迟深度确定性策略梯度(twin delayeddeep deterministic policy gradient,td3)算法,设计无人作业底盘的整机主动悬架姿态控制技术,实现无人作业底盘能自适应丘陵山地恶劣的复杂工况。
2、本发明的技术方案为:
3、一种适应丘陵山地无人作业底盘的姿态协同控制方法,具体步骤如下:
4、智能体通过观测环境状态,获得环境数据s,
5、通过所述环境数据s获得最优的控制策略,包括:收到奖励函数给予的奖励r;
6、根据所述奖励r调整自身动作策略,输出动作a,实现通过主动悬架的作动器来控制底盘姿态;
7、其中,最优的控制策略由智能体通过不断循环训练获得,用于实现整机姿态优化;
8、所述环境数据为智能体观测的状态集为包括俯仰角、侧倾角、垂向位移、垂向加速度、动载荷均值;
9、所述输出动作a为智能体的动作集为a=(u1,u2,u3,u4),包括四个主动悬架的控制力,其大小范围为[-2000n,2000n]。
10、奖励函数决定了智能体将如何解释其所处环境的反馈,并据此调整其策略以达成目标,所述奖励函数具体包括:
11、根据主动悬架和深度强化学习的特性,设计模块化的奖励函数,包括密集函数、即时奖励、稀疏奖励三个模块,基于所述的三个模块来构造奖励函数,总体的奖励函数定义为:
12、r=rn+ri+rs。
13、所述密集函数为奖励函数的基础部分,用于实现推动智能体调整策略的基本规则,包括:如果俯仰角θ、侧倾角垂向位移z、垂向加速度动位移均值的数据数值过大,则会受到更多的惩罚;所述密集函数其定义为:
14、
15、式中k1,k2,k3,k4,k5分别为对于优化目标的权重参数。
16、所述即时奖励用于实现满足条件时提供较小的奖励,具体为:在奖励函数中加入即时奖励r1,表示为:
17、
18、只要当前时刻θi,zi,数值的绝对值大于上一时刻θi-1,zi-1,数值的绝对值,就提供一个较小的奖励δrj;式中k6为即时奖励的权重参数;i为指示函数,其定义为:
19、
20、所述稀疏奖励,旨在给予智能体一个θ,z,参数优化的最终目标,如下:
21、
22、式中k1,k2,k3,k4,k5分别为对应参数的权重系数;
23、只要θ,z,的数值绝对值减少到最初θ′,z′,数值绝对值的10%,即被动悬架条件下各项参数的10%,就会获得一个较大的奖励δrj,累计获得的奖励即为稀疏奖励rs。
24、所述调整自身动作策略前,建立整机主动悬架振动模型:
25、假设整机机体为长方体,初始状态为水平状态,质心位于长方体中心,以质心为原点建立x、y、z轴;x轴方向为速度方向,z轴为机身垂直位移方向,向上为正,向下为负;各轮悬架系统可根据1/4主动悬架振动模型建立,表达式如下:
26、
27、式中mi——簧下质量,zti——车轮上方车身垂直位移,qi(t)——各轮路面激励幅值,kti——轮胎刚度,kui——悬架刚度,ci——悬架阻尼,ui——主动悬架控制力。
28、所述整机主动悬架振动模型用于对各悬架的受力情况、整机姿态以及整机的动力学情况进行分析。
29、对各悬架进行受力分析,可得各悬架对机身施加的作用力fi如下所示:
30、
31、对整机姿态进行分析,定义绕x轴旋转的角度为机身侧倾角绕y轴旋转的角度为机身俯仰角θ,姿态表达式如下所示:
32、
33、式中z——整机机身垂向位移,向上为正,θ——机身俯仰角,——机身侧倾角,l1——前后车轮轮距,l2——左右车轮轮距;
34、对整机进行动力学分析,表达式如下所示:
35、
36、式中iy——整机绕y轴的转动惯量,ix——整机绕x轴的转动惯量,f1、f2、f3、f4——左前、右前、左后、右后轮悬架对机身的作用力。
37、所述调整自身动作策略前,还需对整机姿态协同过程进行mdp建模,具体包括:
38、将整机姿态优化控制过程建模成马尔科夫决策(mdp)模型,通过在matlab/simulink中搭建无人作业底盘主动悬架振动模型来作为td3算法的学习环境。
39、对所述mdp模型进行训练,具体包括以下步骤:
40、基于td3算法,通过actor网络与critic网络相互作用,输出连续的动作决策值;
41、同时td3算法采用经验回放机制,通过建立一个经验池来存储样本;
42、在每个训练回合中,智能体与环境的交互产生的样本保存到经验池中;
43、训练时,critic与actor网络参数的更新都是通过对经验池样本的采样进行。
44、为确保智能体在训练过程中不会出现危险行为,对悬架部件产生损坏,设计所述训练过程的终止条件:
45、将悬架动行程|z1-zt1|约束在0.2m范围内,训练终止条件如下:
46、
47、式中zi,zui分别为各车轮上方机身垂直位移、车轮垂直位移。
48、本发明的有益效果在于:
49、现有一少部分研究是将深度强化学习td3算法应用于1/4主动悬架模型,虽然对机身的垂向加速度起到了很好的抑制作用,提高了车辆平顺性,但未对整机进行分析,从而忽略了整机的俯仰角、侧倾角、垂向位移等姿态指标和不同自由度对底盘平稳性带来的影响。
50、本发明提供一种新型的适应丘陵山地无人作业底盘的姿态协同控制方法。本发明的研究对象无人作业底盘,在丘陵山地等恶劣复杂的地形下工作,对动力和悬架系统性能要求更高,为了保证无人作业底盘能适应丘陵山地路面,确保无人作业底盘能安全、稳定、平顺地工作,整机的俯仰角、侧倾角、垂向位移等姿态指标和不同自由度可能对底盘作业带来的影响是不可忽略的。故本发明将深度强化学习td3算法应用于七自由度整机主动悬架模型,设计基于td3算法的无人作业底盘的姿态协同控制系统,并针对整机的主动悬架模型设计了奖励函数,将整机的姿态指标和不同自由度的影响都考虑了进去,从而能更好地适应丘陵山地复杂的工作环境,提高无人作业底盘工作安全性、稳定性与行驶平顺性,提高作业效率。
51、对比分析整机的俯仰角、侧倾角、垂向位移、垂向加速度、动载荷各方面性能指标,本发明相较于被动悬架、pid控制、ddpg算法姿态控制效果显著,对比实验能验证td3智能体拥有训练收敛更快,动作更柔和,鲁棒性更强的优点,大大提高无人作业底盘在丘陵山地的工作稳定性与作业效率。
本文地址:https://www.jishuxx.com/zhuanli/20240914/296539.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表