一种基于多周期分歧的长时间序列预测集成学习装置
- 国知局
- 2024-09-14 15:02:36
本发明涉及一种基于多周期分歧的长时间序列预测集成学习装置,属于时间序列预测。
背景技术:
1、在时间序列预测领域,如何解决预测序列数据变长时精度不足问题至关重要。长时间序列在不同采样尺度下经常表现出的不同特点,现有研究方法主要有基于模型结构改进和基于长时序数据特征提取的两个研究方向,但都没有对预测窗口增大时的性能下降问题做针对性改进。如何在预测窗口扩大时保证预测精度几乎不下降是本项发明要解决的问题。
2、目前,长时间序列预测方法大部分都只从单一的指标均值角度来衡量预测性能,该视角不能观察到预测性能随预测维度的变化情况,从而无法找到预测性能下降的真正原因。
技术实现思路
1、发明目的:常见的时间序列预测方法在长序列预测中表现出精度不足的现象,具体表现为在预测窗口增大时预测性能快速下降。针对现有技术中存在的问题与不足,本发明提供一种基于多周期分歧的长时间序列预测集成学习装置。具体来说,首先收集处理时间序列数据,对序列指定多个周期进行多轮分解,然后在这些不同尺度分解后的数据上训练多个不同的子模型,最后选择那些在长序列的部分维度上预测表现最好的模型,并将他们拼接在一起,完成基于多周期分歧的集成,提升长序列预测的精度。
2、技术方案:一种基于多周期分歧的长时间序列预测集成学习装置,包括序列分解模块、子模型训练模块和集成学习模块;
3、序列分解模块首先收集处理时间序列数据,划分好训练和待预测数据,对时间序列数据指定多个周期进行多轮分解;然后分析预测任务的关键因素;
4、子模型训练模块在多个周期多轮分解后的数据上,训练多个不同的子模型;
5、集成学习模块对这些子模型进行集成,识别多周期分解后预测性能走势之间的分歧,选择那些在长序列的部分维度上预测表现最好的子模型,并将他们拼接在一起,完成基于多周期分歧的集成,提升长序列预测的精度。
6、本发明可以解决长序列预测问题的长距离依赖难以提取和累计误差问题,并且本发明的使用不受具体预测的模型结构影响,在实施过程中应用面广、适用性强、精度提升效果好。
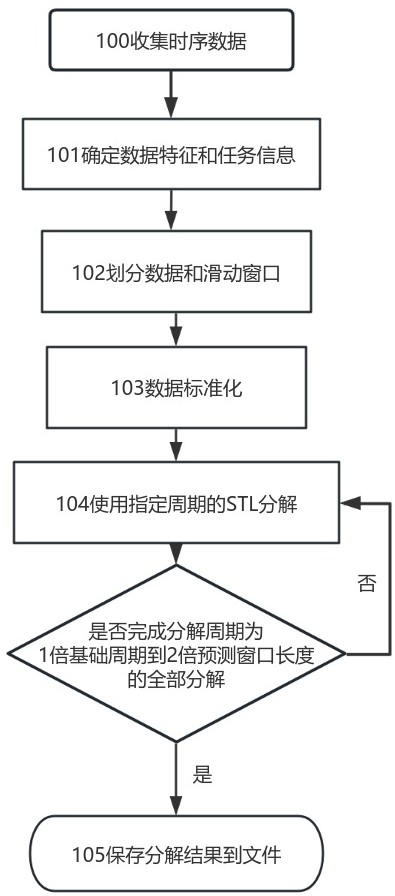
7、序列分解模块实现步骤具体为:
8、步骤100,收集用于训练的时间序列数据,真实情况可能存在缺失值或异常值;
9、步骤101,确定时间序列的每日数据粒度,作为基础周期值p,确定预测窗口长度f;
10、步骤102,划分好训练、验证和待预测数据,使用滑动窗口完成训练输入和训练标记的切分操作;
11、步骤103,在训练集上训练标准化器,并对全部数据进行标准化;
12、步骤104,使用stl分解方法对时间序列进行多次分解,分别设置分解周期为p的不同整数倍,从1倍开始,直到2倍的f,共n个;
13、步骤105,保存分解结果中的趋势、季节性分量到文件中,这样下次再用到这些分量时,只需读取文件结果,无需再执行一次耗时的分解过程,达到避免重复分解增大开销的目的。
14、子模型训练模块的实现步骤具体为:
15、步骤200,读取步骤105中的分解结果;
16、步骤201,先构造一个的深度神经网络模型,用于选择局部标准化技巧等关键因素,关键因素选出后,其他神经网络都可以沿用先构造的深度神经网络模型的参数设置,无需重复选择;
17、步骤202,基于步骤201选定的设置构造n个异构的深度神经网络模型,用于训练子模型;
18、步骤203,设置好模型训练所必须的超参数,使子模型训练参数设置相同,但数据输入不同;对于数据分解后的趋势分量和季节性分量分别训练一个子模型,每个深度神经网络会对应2个子模型,训练之后得到2n个异构的子模型;
19、步骤204,保存步骤203中训练好的不同子模型的预测结果为列表形式,称为预测列表,并计算这些子模型的mse、mae、mape评估指标。
20、集成学习模块进行模型融合的步骤具体为:
21、步骤300,将步骤204全部子模型的评估指标mape在全部预测维度上展开,并保存为平均绝对百分比误差列表;
22、步骤301,使用基于mape走势差异的最佳预测集成算法,在验证集上对全部子模型的预测性能进行深度评估,根据算法中对局部最优的定义,选择出具有局部最优属性的子模型;
23、步骤302,保存步骤301中得到的子模型选择方案,即集成方案;
24、步骤303,将集成方案,应用到测试集上,得到集成后的预测结果。
25、对于所述长时间序列,预测窗口长度f应至少为4倍的基础周期值p。例如,如果数据集每小时一个数据点,则基础周期值p为24,该预测任务窗口长度应至少为96,否则很难称之为长时间序列预测任务,也非该集成学习装置的适用范围。
26、所述stl分解方法,为根据不同的数据集情况调节季节性平滑参数,并丢弃残差分量。分解后得到的趋势、季节性、残差三个分量,在丢弃残差分量后,仅依照步骤105所述保存方法,保存趋势和季节性分量用于后续预测。
27、所述子模型训练模块,应按照步骤203所述的训练方法,针对趋势分量和季节性分量分别训练,且训练趋势分量时应减少深度模型的编码向量维度dmodel设置和学习率更新方案,使其更适用于更平滑和可预测性更强的趋势预测任务。
28、所述基于mape走势差异的最佳预测集成算法部分,接收三个输入:步骤204中一个包含多个预测模型的预测列表,步骤300中对应的平均绝对百分比误差列表,以及设定的单位间隔长度(默认为p)。算法的目标是从提供的预测列表中,按照每个单位间隔选择平均绝对百分比误差最小的预测模型。具体操作如下:算法首先定义两个输出,最佳预测列表和最佳平均绝对百分比误差列表。然后,算法遍历整个预测时段,每次处理一个单位间隔。在每个单位间隔内,算法初始化该间隔的最佳误差为无穷大,并将最佳预测设为空。接着,算法遍历每个子模型的预测结果,在当前间隔内计算每个模型的平均绝对百分比误差,并与当前最佳误差比较,若当前模型的误差更小,则更新该间隔的最佳误差和最佳预测。最后,将每个间隔的最佳预测合并到最佳预测列表中。当所有间隔处理完成后,算法输出最终的最佳预测列表和最佳平均绝对百分比误差列表。这种方式确保了每个单位间隔内都选出了表现最佳的预测模型。
29、一种基于多周期分歧的长时间序列预测集成学习方法,包括序列分解步骤、子模型训练步骤、集成学习步骤;
30、序列分解步骤和序列分解模块实现步骤相同。
31、子模型训练步骤和子模型训练模块的实现步骤相同。
32、集成学习步骤和集成学习模块进行模型融合的步骤模型融合的步骤相同。
33、一种计算机设备,该计算机设备包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行上述计算机程序时实现如上所述的基于多周期分歧的长时间序列预测集成学习方法。
34、一种计算机可读存储介质,该计算机可读存储介质存储有执行如上所述的基于多周期分歧的长时间序列预测集成学习方法的计算机程序。
35、有益效果:与现有技术相比,本发明提供的基于多周期分歧的长时间序列预测集成学习装置,使用集成学习的方法在不降低序列预测任务难度的情况下,提升了预测的精度,尤其是提高了预测窗口中更远未来的预测精度。
本文地址:https://www.jishuxx.com/zhuanli/20240914/296746.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表