一种基于注意力机制的近海藻华爆发预测方法
- 国知局
- 2024-09-14 15:02:48
本发明属于海洋生态系统监测,具体涉及一种基于注意力机制的近海藻华爆发预测方法。
背景技术:
1、近海藻华丰度预测是海洋生态系统监测和保护中的重要课题。随着工业化和城市化的加速发展,近20年来全球海岸带藻华扩大,藻华爆发频率增加,影响面积增加。当水华爆发时,以蓝藻为代表的有害藻类大量消耗水中溶解氧,造成水中其它水生植物、动物死亡,最终影响水环境质量,破坏水生态环境平衡,对人类健康和社会经济造成严重危害。
2、目前,藻华爆发预警主要依赖于物理、化学和生物指标的监测,如水温、营养盐含量、光照强度等,也有使用机器学习的方法如arima、梯度提升树、逻辑回归等等,这些方法通常需要大量的现场采样和实验分析,难以实现对近海藻华进行精确且及时性的预测。因此,发展一种高效且精确的预测方法对于改善海洋生态系统监测和保护至关重要。
技术实现思路
1、为了解决上述所存在的技术问题,实现对海洋近海藻华进行精确及时的预测,本发明提供了一种基于注意力机制的近海藻华爆发预测方法。
2、所采用的技术方案如下:
3、一种基于注意力机制的近海藻华爆发预测方法,包括如下步骤:
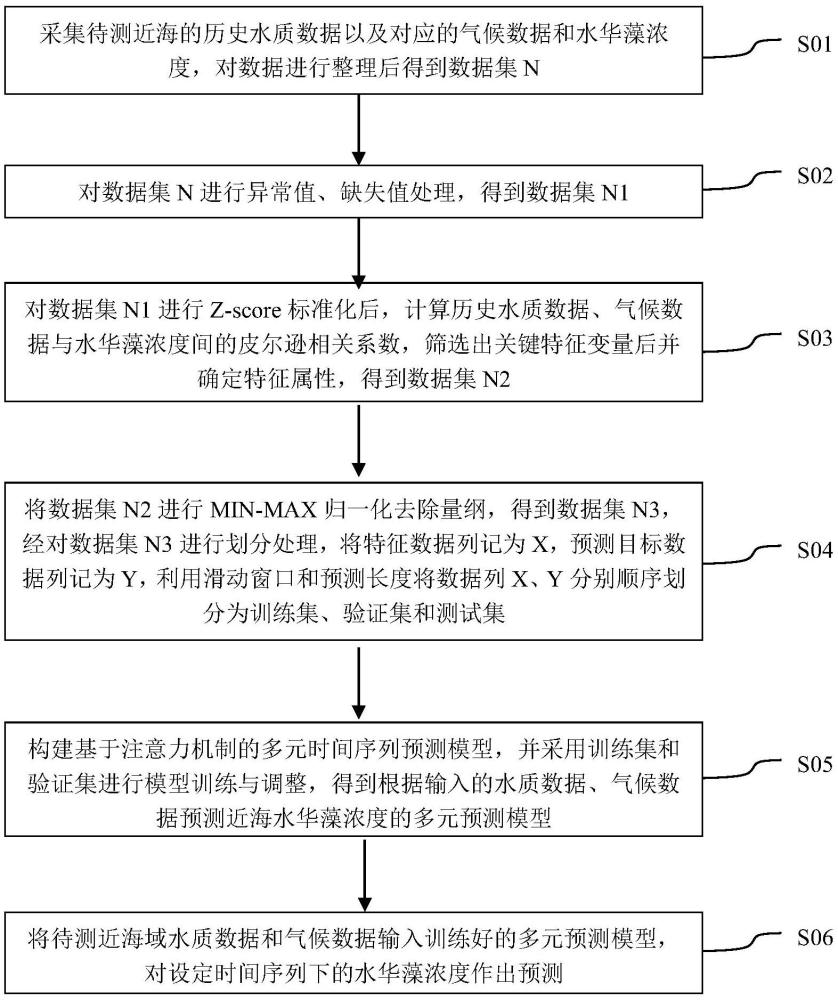
4、步骤1,采集待测近海的历史水质数据以及对应的气候数据和水华藻浓度,对数据进行整理后得到数据集n;
5、步骤2,对数据集n进行异常值、缺失值处理,得到数据集n1;
6、步骤3,对数据集n1进行z-score标准化后,计算历史水质数据、气候数据与水华藻浓度间的皮尔逊相关系数,筛选出关键特征变量后并确定特征属性,得到数据集n2;
7、步骤4,将数据集n2进行min-max归一化去除量纲,得到数据集n3,经对数据集n3进行划分处理,将特征数据列记为x,预测目标数据列记为y,利用滑动窗口和预测长度将数据列x、y分别顺序划分为训练集、验证集和测试集;
8、步骤5,构建基于注意力机制的多元时间序列预测模型,并采用训练集和验证集进行模型训练与调整,得到根据输入的水质数据、气候数据预测近海水华藻浓度的多元预测模型;
9、步骤6,将待测近海域水质数据和气候数据输入训练好的多元预测模型,对设定时间序列下的水华藻浓度作出预测。
10、优选地,筛选出皮尔逊相关系数大于0.1的关键特征变量,确定35个列特征属性和6个衍生特征;
11、所述列特征属性包括:观测年份、观测月份、水体表层溶解氧、水体表层溶解氧饱和度、水体表层大肠杆菌、水体表层粪便大肠杆菌群、水体表层无机氮总量、水体表层凯氏定氮总量、水体表层氮浓度、水体表层氨氮浓度、水体表层亚硝酸盐氮浓度、水体表层硝态氮、水体表层5天生化需氧量、水体表层磷总量、水体表层正磷酸盐磷、水体表层塞氏盘深度、水体表层悬浮固体、水体表层盐度、水体表层二氧化硅、表层水温、水体表层浊度、水体表层联合氨、水体表层挥发性悬浮固体、水体表层酸碱度、水体表层辉色素、观测站点纬度、观测站点经度、观测区域当月最高气温、观测区域当月平均最高气温、观测区域当月平均气温、观测区域当月平均最低气温、观测区域当月最低气温、观测区域降雨量、观测区域风向、观测区域风速;
12、所述衍生特征包括:区域、季节、温差、湿度指数、风力等级和评定水质等级;预测目标为水体表层叶绿素-a。
13、进一步优选地,所述步骤2中对数据集n进行异常值、缺失值处理,其具体方法是:
14、数据集n中包含水体表中底三层的多种水体观测数据,移除数据集n中的中层水体和底层水体的观测的数据,并对数据集n中的列名进行重命名,使所有监测点的数据格式一致;
15、按照年份、月份和监测点信息将采集数据与对应整个区域的气候数据进行合并,再根据监测点将其经纬度信息与采集数据进行合并,重新组织列的顺序;
16、将气象信息中包含的特殊字符用整个区域的当前月份均值进行替换;
17、计算每列数据的标准差和均值,并将超出设定阈值的异常值替换为该列的均值;
18、根据每列的缺失值比例,删除缺失值比例大的列,并使用xgboost模型对缺失值进行填充。
19、优选地,所述步骤5中对所构建的多元时间序列预测模型进行训练的方法是:
20、将训练集输入数据h进行特征转换和嵌入,得到嵌入后的张量embed(x);
21、基于gru神经元的编码器,将张量embed(x)和初始化隐藏状态hidden0输入至gru神经元中,得到第一时间步的输出output1和隐藏状态hidden1;
22、将第一时间步的输出output1和隐藏状态hidden1输入至gru神经元中,得到第二时间步的输出output2和更新后的隐藏状态hidden2;
23、经gru神经元多次循环处理,直至处理完所有时间步或达到设定的终止条件为止;
24、采用注意力机制计算每个时间步的输入特征与当前输出预测的相关性;
25、基于gru神经元的解码器,将当前时刻的输入与上下文向量进行拼接作为构造gru神经元的输入,并将其与上一时刻的隐藏状态一同传入gru神经元进行计算,得到当前时刻的输出结果。
26、优选地,嵌入后的张量embed(x)具体获得方法是:
27、将输入数据h按批次分组,并对输入数据h进行转置以符合模型需要的格式,得到结果记为x′,x′∈r(batch×var×time),创建顺序时间标记xmark,xmark∈r(batch×1×time);将转置后的输入数据与时间标记进行拼接得到张量xconcat,xconcat∈r(batch×(var+1)×time);使用线性变换操作将拼接后的张量xconcat映射到一个新的特征空间,得到嵌入后的张量embed(x),
28、其中优选地,采用注意力机制计算每个时间步的输入特征与当前输出预测的相关性,得到注意力权重,其具体方法是:
29、将注意力机制参数初始化,将隐藏状态hidden沿时间维度重复max_len次,得到隐藏状态hidden′,其表达式:
30、hidden′=hidden.repeat(max_len,1,1).transpose(0,1)
31、通过线性层attn和双曲正切激活函数计算注意力能量张量,其表达式是:
32、energy=tanh(attn([hidden′,encoderoutputs])
33、其中:{output1,output2,...,outputn}的统称为encoderoutputs;
34、将注意力能量张量转置并使用学习得到的权重v进行加权,得到每个查询的注意力分数;
35、通过softmax函数对注意力分数进行归一化,得到归一化后的注意力权重。
36、优选地,基于gru神经元的解码器,将当前时刻的输入与上下文向量进行拼接作为构造gru神经元的输入,并将其与上一时刻的隐藏状态一同传入gru神经元进行计算,得到当前时刻的输出结果,其具体方法是:
37、使用上一时刻的隐藏状态lasthidden和编码器的输出encoderoutputs计算注意力权重attention_weights,经对编码器输出进行加权后,获得上下文向量context;
38、将当前时刻的输入currentinput和上下文向量context进行拼接,构成gru单元的输入rnninput。
39、将构造好的输入rnninput和上一时刻的隐藏状态lasthidden传入gru神经元进行计算,得到当前时刻的输出output和更新后的隐藏状态hidden;
40、将gru神经元的输出output通过线性层映射到指定的输出维度,得到最终的输出结果final_output。
41、进一步地,还包括步骤7,采用决定系数分数r2、均方误差mse和平均绝对误差mae三个指标中的至少一种评定多元预测模型的训练效果。
42、本发明技术方案具有如下优点:
43、a.本发明利用注意力机制构建的多元时间序列预测模型,并通过收集海域各个监测位置的水质数据、气候数据及水华藻浓度历史数据,并按照年、月、监测站合并得到数据集,本发明方法结合如气候数据、水体a类叶绿素浓度等多维海洋环境数据,构建了一个高效的多元预测模型,该模型利用注意力机制动态调整不同特征的权重,以更准确地预测近海藻华的丰度和群落结构。
44、b.本发明基于注意力机制的深度学习算法能够有效地处理大规模、高维度的海洋环境数据,并从中提取关键特征信息,实现对复杂生态系统的精确预测,利用注意力机制构建的多元预测模型能够更准确地捕捉藻类丰度中不同物种之间的关系和变化趋势,从而提高预测的准确性和可靠性。
45、c.本发明通过展示使用15个月来预测8个月的r2值能够看出,所构建的多元时间序列预测模型在长期预测和短期预测上均比lstm模型和blstm模型具有显著的优势,通过对模型预测结果的分析和比较,本发明方法能够应用于近海藻华爆发的预测中。
46、d.本发明构建的多元时间序列预测模型不仅适用于近海藻华丰度预测,还可以扩展应用于其他生态系统监测和预测任务,例如湖泊水质监测、森林火灾预警等。模型的灵活性和通用性使其在环境保护、资源管理等领域具有广泛的应用前景。
本文地址:https://www.jishuxx.com/zhuanli/20240914/296758.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。