一种抗体-抗原亲和力预测方法、装置、系统及存储介质与流程
- 国知局
- 2024-09-14 15:04:31
本发明属于抗体-抗原亲和力预测,尤其涉及一种抗体-抗原亲和力预测方法、装置、系统及存储介质。
背景技术:
1、抗体是由免疫系统在遭遇病菌、病毒等抗原刺激后由b细胞分泌的蛋白质分子。它们具有特异性的免疫功能,通过y形结构的两端抗原结合位点(complementarity-determining regions,cdrs,互补决定区)特异性地识别和结合入侵的抗原。此过程使得抗原失活并促使白细胞吞噬,从而起到诊断和防治疾病的作用。随着医学的进步,抗体已被开发成治疗多种疾病的药物,特别是在癌症治疗中显示出较化学小分子药更好的靶向性和降低毒性的优势。
2、抗体的亲和力是评价其功能的关键参数,指抗体与抗原之间的结合强度。亲和力越高,抗体和相应抗原之间的结合强度就越强。亲和力对于抗体是最基础的属性,也是抗体质量的重要指标,没有足够的亲和力,抗体就无法和抗原稳定持续的结合,从而也无法有效发挥抗体的功能。然而过高的亲和力,在某些情况下会使抗体分子在特定区域发生聚集,影响抗体在病灶部位的扩散和蓄积,会影响药物的效果。因此,寻找具有合适亲和力水平的抗体是抗体药物研发的关键步骤,也是抗体药物的研发难点之一。
3、传统上,亲和力的提高,依赖于动物免疫获得初始抗体后,通过人工突变和湿实验迭代优化。这一方法虽然可以达到目的,但成本高昂,且时间效率低下。
4、近年来,人工智能技术的引入为抗体的亲和力优化带来了新的可能。通过建立大规模的虚拟突变文库并运用序列分析技术,可以快速筛选出潜在的优势抗体变体,这种方法减少了对湿实验(wet lab experiments)的依赖,极大地节省了研发成本和时间。然而,这种基于序列的预测方法通常未能考虑抗体与抗原之间的空间结构关系,限制了预测的准确性。
5、尽管通过计算机技术进行的抗体亲和力预测提供了一个成本效益高的替代方案,现有技术依然存在不足。基于结构的预测方法需要精确的三维结构信息,而许多候选抗体并无可用的结构数据,使得这一方法在实际应用中受限。基于序列的方法虽然在操作上较为简便,但因忽略了结构信息,其预测的准确性往往不如基于结构的方法。由此可见,虽然人工智能为抗体亲和力研究提供了新的技术路径,但仍需改进以提高预测的精度和实用性。
技术实现思路
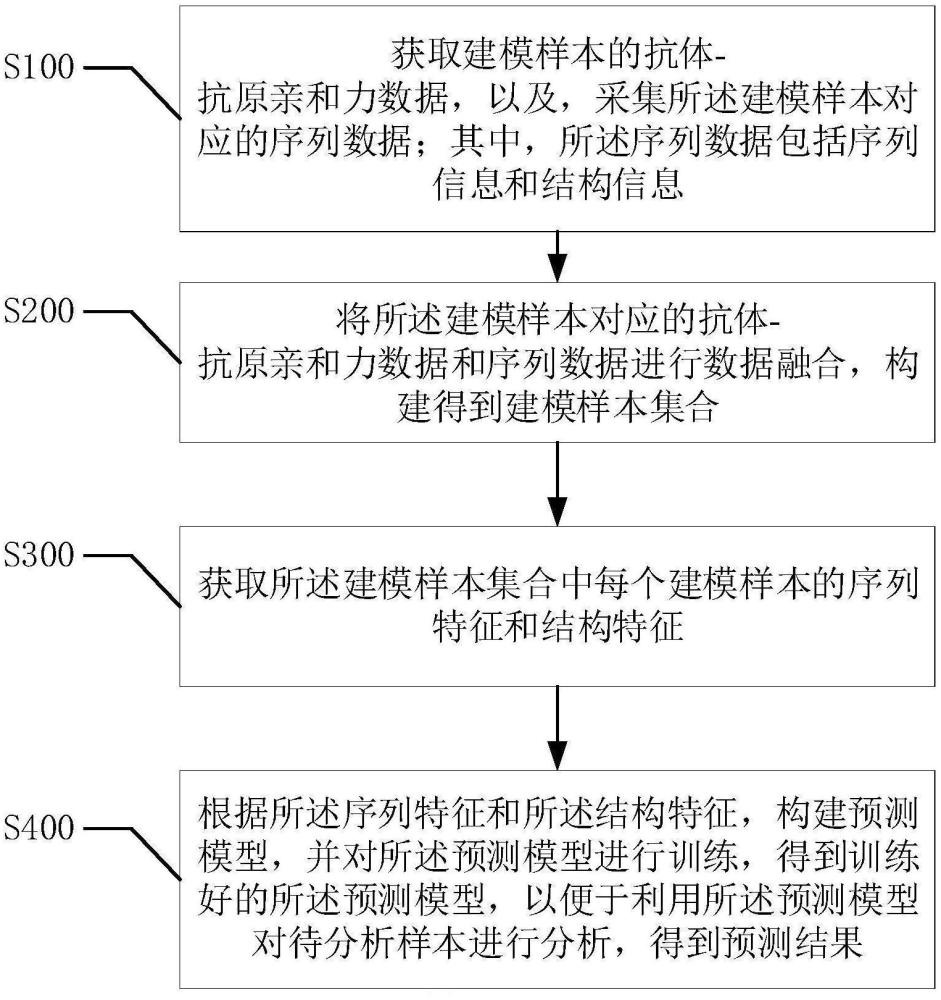
1、为解决上述问题,本发明提供一种抗体-抗原亲和力预测方法,包括:
2、获取建模样本的抗体-抗原亲和力数据,以及,采集所述建模样本对应的序列数据;其中,所述序列数据包括序列信息和结构信息;
3、将所述建模样本对应的抗体-抗原亲和力数据和序列数据进行数据融合,构建得到建模样本集合;
4、获取所述建模样本集合中每个建模样本的序列特征和结构特征;
5、根据所述序列特征和所述结构特征,构建预测模型,并对所述预测模型进行训练,
6、得到训练好的所述预测模型,以便于利用所述预测模型对待分析样本进行分析,得到预测结果。
7、优选地,所述获取建模样本的抗体-抗原亲和力数据,以及,获取所述建模样本对应的序列数据,包括:
8、采集抗体-抗原亲和力数据,作为建模样本;
9、获取每个所述建模样本所对应抗原和抗体的序列数据中的所述序列信息,以及每个所述序列信息对应的所述结构信息;
10、其中,在每个所述建模样本中,所述序列信息包括抗体的序列信息和与所述抗体对应的抗原的序列信息;所述抗体的序列信息包括重链序列信息和轻链序列信息中的至少一个;所述抗原的序列信息的数量为一条或两条。
11、优选地,所述抗体-抗原亲和力数据的数据类型包括解离常数和结合自由能;
12、所述将所述建模样本对应的抗体-抗原亲和力数据和序列数据进行数据融合,构建得到建模样本集合,包括:
13、将所有的所述抗体-抗原亲和力数据中,不符合预设亲和力数据类型的所述抗体-抗原亲和力数据,通过亲和力转换公式,转换为与所述预设亲和力数据类型一致的数据类型;
14、判断是否存在序列信息相同,但对应的多个抗体-抗原亲和力数据不同的建模样本;
15、若是,则将所述建模样本的多个所述抗体-抗原亲和力数据取平均值,并将所述平均值作为所述建模样本对应的所述抗体-抗原亲和力数据;
16、优选地,所述亲和力转换公式为:
17、
18、其中,δg代表结合自由能;kd代表解离常数;r代表气体常数;t代表华氏温度。
19、优选地,所述将所述建模样本对应的抗体-抗原亲和力数据和序列数据进行数据融合,构建得到建模样本集合之后,还包括:
20、对所述建模样本中的抗体-抗原亲和力数据分布优化处理;
21、所述数据分布优化处理包括:
22、确定所述抗体-抗原亲和力数据的正态分布参数,以及所述抗体-抗原亲和力数据的最大值和最小值;
23、基于所述最大值和所述最小值,对所有的所述抗体-抗原亲和力数据进行区间划分,得到包含有所述抗体-抗原亲和力数据的多个统计区间;
24、对划分到每个所述统计区间中的所述抗体-抗原亲和力数据的数据量进行统计,得到原始分布数据图;
25、根据所述正态分布参数构建正态分布步长数组,以及,计算得到正态分布值数组,并根据所述正态分布值数组构建正态分布数组;其中,所述正态分布数组为每个所述统计区间经过分布调整后的数据量的理论值;
26、基于所述原始分布数据图,通过所述正态分布数组将所有的所述抗体-抗原亲和力数据调整至服从正态分布。
27、优选地,所述基于所述最大值和所述最小值,对所有的所述抗体-抗原亲和力数据进行区间划分,得到包含有所述抗体-抗原亲和力数据的多个统计区间,包括:
28、获取预设区间数目;
29、根据所述预设区间数目计算得到区间长度;所述区间长度的计算方法为:
30、
31、其中,l代表所述区间长度;max代表所述最大值;min代表所述最小值;s代表所述预设区间数目;
32、在所述最大值和所述最小值之间,将所有的所述抗体-抗原亲和力数据划分为符合所述预设区间数目的所述统计区间;所述统计区间的表达式为:
33、[(min,min+l×1),(min+l×1,min+l×2),(min+l×2,min+l×3),…,(min+l×(s-1),max)]。
34、优选地,所述正态分布参数包括:均值、方差、步长和偏移量;
35、所述正态分布步长数组的表达式为:a=[0,0+stride×1,0+stride×2,…];
36、其中,a代表所述正态分布步长数组;stride代表所述正态分布参数中的所述步长;
37、所述正态分布值数组的计算方法为:
38、将所述正态分布步长数组中的每个元素输入到正态分布概率密度函数中计算得到所述正态分布值数组;
39、所述正态分布概率密度函数为:
40、其中,σ代表标准差,σ2所述正态分布参数中的方差;μ代表所述正态分布参数中的均值;e代表自然对数的底数,为数字常数;x代表所述正态分布步长数组中的元素;
41、所述基于所述原始分布数据图,通过所述正态分布数组将所有的所述抗体-抗原亲和力数据调整至服从正态分布,包括:
42、确定所有所述统计区间中正态分布中心位置m,并将所述正态分布中心位置m做为正态分布的顶点,拥有最大的数据量,以及,根据所述正态分布中心位置m确定每个所述统计区间的最大数据量vi,其中,i代表每个所述统计区间的位置;
43、所述正态分布中心位置表达式为:m=indexmid+shift;
44、其中,indexmid代表所有所述统计区间的正态分布中心位置的序号;shift为所述偏移量;
45、基于所述正态分布中心位置表达式,通过shift调整所述正态分布中心位置m;
46、如果shift为0,则所述正态分布中心位置m为所述所有统计区间的中间位置;如果shift为负整数,则所述正态分布中心位置m向左偏移shift个位置;如果shift为正整数,则所述正态分布中心位置m向右偏移shift个位置;
47、通过所述偏移量、所述正态分布中心位置m和所述正态分布值数组中的每个元素,将所有的所述抗体-抗原亲和力数据调整至服从正态分布。
48、将所有的所述抗体-抗原亲和力数据调整至服从正态分布优选地,所述通过所述偏移量、所述正态分布中心位置和所述正态分布值数组中的每个元素,将所有的所述抗体-抗原亲和力数据调整至服从正态分布,包括:
49、将所有所述统计区间的所述正态分布中心位置的数据量,确定为最大数据量,作为正态分布的顶点;
50、根据所述统计区间的所述最大数据量,确定所述最大数据量所在区间的左边所有统计区间的数据量,作为左边区间数据量;以及,根据所述统计区间的所述最大数据量,确定所述最大数据量所在区间的所有右边统计区间的数据量,作为右边区间数据量;
51、所述左边区间数据量的表达式为:
52、其中,i代表所述统计区间的位置;m代表所有所述统计区间中的所述正态分布中心位置;g代表所述正态分布值数组;g0代表g中0位置的值;gm-i为g中(m-i)位置的值;代表所述左边区间数据量;vmax代表所有所述统计区间的m位置的数据量;
53、所述右边区间数据量的表达式为:
54、其中,代表所述右边区间数据量;
55、判断所述抗体-抗原亲和力数据中,是否存在所述左边区间数据量和/或所述右边区间数据量大于其对应的所述统计区间数据量的区间;
56、若是,则将所述左边区间数据量和/或所述右边区间数据量大于其对应的所述统计区间数据量的区间作为调整区间,并将所述调整区间采用随机重复过采样方法增大数据量,直至所述调整区间的数据量达到其所对应的所述左边区间数据量和/或所述右边区间数据量。
57、优选地,所述序列特征包括pssm特征、独热编码特征和氨基酸理化性质特征;
58、其中,所述氨基酸性质特征包括blosum62打分矩阵特征和氨基酸理化性质矩阵特征中的任意一种或两种;
59、所述结构特征包括二级结构特征、二面角特征、溶剂可及性表面积特征、半球暴露量特征、氨基酸深度特征、氨基酸接触矩阵特征、氨基酸转角特征中的任意一种或多种。
60、优选地,所述氨基酸理化性质矩阵特征的获取方法,包括:
61、获取预设氨基酸理化性质特征对应关系,并且,基于所述预设氨基酸理化性质特征对应关系对所述建模样本的所述序列信息进行比较;其中,所述预设氨基酸理化性质特征对应关系中包括20种标准氨基酸,以及与所述标准氨基酸对应的性质特征;
62、对所述序列信息中的每一个氨基酸进行分析,将每一个氨基酸处理为0/1编码的性质特征的特征向量;其中,1代表所述氨基酸具备所述性质特征;0代表所述氨基酸不具备所述性质特征;
63、根据所述建模样本的所述序列信息的顺序,将所述序列信息的每种氨基酸的0/1编码的性质特征的特征向量合并,构成所述建模样本对应的氨基酸理化性质矩阵,并将所述氨基酸理化性质矩阵作为所述氨基酸理化性质矩阵特征。
64、优选地,所述预设氨基酸理化性质特征对应关系中包括17种性质特征,以及与所述性质特征对应的20种标准氨基酸;
65、其中,每种性质特征具有一个对应的id,所述预设氨基酸理化性质特征对应关系id由0至17,分别为如下17组对应关系:
66、id:0,性质特征:酸性,标准氨基酸为d和e;id:1,性质特征:碱性,标准氨基酸为h、r和k;id:2,性质特征:极性,标准氨基酸为d、e、h、r、k、c、g、q、n、s、y和t;id:3,性质特征:带电,标准氨基酸为d、e、h、r和k;id:4,性质特征:带正电,标准氨基酸为h、r和k;id:5,性质特征:带负电,标准氨基酸为d和e;id:6,性质特征:亲水,标准氨基酸为d、e、h、r、k、c、g、q、n、s、y和t;id:7,性质特征:疏水,标准氨基酸为f、a、l、m、i、w、p和v;id:8,性质特征:中性,标准氨基酸为f、a、l、m、i、w、p、v、c、g、q、n、s、y和t;id:9,性质特征:含硫,标准氨基酸为m和c;id:10,性质特征:脂肪族,标准氨基酸为a、g、l、m、i、p和v;id:11,性质特征:芳香族,标准氨基酸为f、w和y;id:12,性质特征:含羟基,标准氨基酸为s、y和t;id:13,性质特征:第一分子量,标准氨基酸为w、y和r;id:14,性质特征:第二分子量,标准氨基酸为f、h、m、e、k、q、d和n;id:15,性质特征:第三分子量,标准氨基酸为i、l、c、t、v、p、s、a和g;id:16,性质特征:第四分子量,标准氨基酸为t、v、p、s、a和g。
67、优选地,所述根据所述序列特征和所述结构特征,构建预测模型,并对所述预测模型进行训练,得到训练好的所述预测模型,包括:
68、定义模型结构,并基于所述模型结构构建所述预测模型;
69、以所述建模样本的序列信息为输入;其中,基于深度融合策略,将所述建模样本的抗体和抗原的序列信息首尾相连进行合并,构成融合序列;
70、对所述建模样本的所述序列特征和所述结构特征融合,得到特征矩阵,输入至特征提取层;
71、对所述特征提取层中的所述特征矩阵进行深度学习处理,将深度学习处理得到的结
72、果,通过多层全连接神经网络进行编码,输出得到预测亲和力结果,并基于所述预测亲和力结果与所述抗体-抗原亲和力数据的差异,对所述预测模型训练,得到训练好的所述预测模型。
73、此外,为解决上述问题,本发明还提供一种抗体-抗原亲和力预测装置,包括:数据采集模块,用于采集建模样本的抗体-抗原亲和力数据,以及,采集所述建模样本对应的序列数据;其中,所述序列数据包括序列信息和结构信息;数据融合模块,用于将所述建模样本对应的抗体-抗原亲和力数据和序列数据进行数据融合,构建得到建模样本集合;特征获取模块,用于获取所述建模样本集合中每个建模样本的序列特征和结构特征;模型构建模块,用于根据所述序列特征和所述结构特征,构建预测模型,并对所述预测模型进行训练,得到训练好的所述预测模型,以便于利用所述预测模型对待分析样本进行分析,得到预测结果。
74、此外,为解决上述问题,本发明还提供一种抗体-抗原亲和力预测系统,包括存储器以及处理器,所述存储器中存储有抗体-抗原亲和力预测程序,所述处理器运行所述抗体-抗原亲和力预测程序以使所述抗体-抗原亲和力预测系统执行如上述所述的抗体-抗原亲和力预测方法。
75、此外,为解决上述问题,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有抗体-抗原亲和力预测程序,所述抗体-抗原亲和力预测程序被处理器执行时实现如上述所述的抗体-抗原亲和力预测方法。
76、本发明提供一种抗体-抗原亲和力预测方法、装置、系统及存储介质,其中,所述抗体-抗原亲和力预测方法包括:获取建模样本的抗体-抗原亲和力数据,以及,采集所述建模样本对应的序列数据;其中,所述序列数据包括序列信息和结构信息;将所述建模样本对应的抗体-抗原亲和力数据和序列数据进行数据融合,构建得到建模样本集合;获取所述建模样本集合中每个建模样本的序列特征和结构特征;根据所述序列特征和所述结构特征,构建预测模型,并对所述预测模型进行训练,得到训练好的所述预测模型,以便于利用所述预测模型对待分析样本进行分析,得到预测结果。
77、本发明所提供的抗体-抗原亲和力预测方法,融合抗体和抗原的序列特征和结构特征进行亲和力预测,旨在提高亲和力预测的准确性和效率。有益效果包括如下:
78、(1)综合序列和结构信息:该方法不仅利用了序列数据,还整合了结构信息。序列数据为预测提供了基本的分子生物学特征,而结构信息则补充了三维空间的相互作用和配置,从而提供了更全面的生物分子交互洞察。这种结合方式弥补了仅依赖序列数据时可能遗漏的结构动态和复杂的空间关系,从而增强了预测模型的准确性。既保留了基于序列的模型的快速高通量的优点,又能通过对序列获取相应的结构特征来弥补结构信息缺失的问题。
79、(2)高效的数据融合:通过高效的数据融合策略,该方法能够在不牺牲运算速度的前提下,处理大规模的数据集。数据融合过程中的优化保证了即使在数据量大的情况下也能维持高效的处理速度,使得该方法适合于高通量的抗体筛选和优化任务。
80、(3)高精度预测模型:通过结合序列特征和结构特征,本发明构建的预测模型在理解复杂的生物分子机制方面具有更高的精度。这种模型能更准确地模拟抗体与抗原之间的相互作用,提供更为精确的亲和力预测结果,对于设计高效的治疗性抗体特别有价值。
81、综上所述,本发明通过结合抗体和抗原的序列特征及结构特征,不仅保留了基于序列的模型的高通量优点,同时通过引入结构特征,有效地解决了仅依靠序列信息可能面临的限制和挑战。这种方法的实施有望在抗体药物的开发和优化中发挥重要作用,尤其是在需要迅速筛选并验证大量候选抗体的场景中。
本文地址:https://www.jishuxx.com/zhuanli/20240914/296858.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。