基于双仿射注意力的中文电子病历命名实体识别方法
- 国知局
- 2024-09-19 14:30:25
本发明涉及基于双仿射注意力的中文电子病历命名实体识别方法,属医疗信息技术。具体涉及针对静脉血栓栓塞症患者中文电子病历的命名实体识别问题。
背景技术:
1、静脉血栓栓塞症(vte)包括深静脉血栓形成(dvt)和肺血栓栓塞症(pte),是严重威胁人类健康的疾病,是导致医院内非预期死亡的主要原因,也是医院内可预防的主要疾病之一。然而只有一半的高危患者能够获得有效的预防措施。vte患者的诊治过程中,形成了海量电子病历数据。电子病历(emr)记录了患者在医院中的整个医疗活动,包含了病人的疾病、诊断和治疗信息,为辅助临床决策和药物挖掘等工作提供重要数据支撑。中文电子病历命名实体识别主要是对中文电子病历中的疾病、药物、症状等医疗专业术语实体进行自动识别和分类,对于下游任务例如信息检索,知识图谱等有着十分重要的作用。
2、技术方面,许多研究人员设计了先进的神经网络模型用于电子病历命名实体识别任务,并通过在生物医学语料库上构建预训练模型进一步提高了其在领域内的实体识别性能。尽管先前方法结合了多维特征或使用了先进的神经网络结构,但将其运用在vte患者电子病历数据集中效果并不好。
3、静脉血栓中文电子病历数据集存在大量专业术语和缩写,想要识别出实体之间的关联极为困难,加之中文自身的语言特性,缺乏明显的词界限(空格分隔)。因此,通用模型在vte数据上难以准确把握实体的边界和在文本中的语义信息,导致识别效果不佳。如句子“腹软,无压痛及反跳痛,移动性浊音阴性,右下肢肿胀稍消退”中,实体“腹软”属于缩写,“移动性浊音”属于专业术语。传统方法不能充分挖掘上下文语义和实体间依赖关系,导致实体边界和语义信息丢失,命名实体识别效果不好。
技术实现思路
1、鉴于现有技术中的上述缺陷或不足,本发明提供基于双仿射注意力的中文电子病历命名实体识别方法,以克服静脉血栓栓塞症患者中文电子病历涉及大量的专业术语和缩写,导致命名实体识别时容易出现实体边界和语义信息丢失的问题,提高医疗文本中命名实体识别效果。
2、为了实现上述目的,本发明的技术方案是:基于双仿射注意力的中文电子病历命名实体识别方法,包括如下:
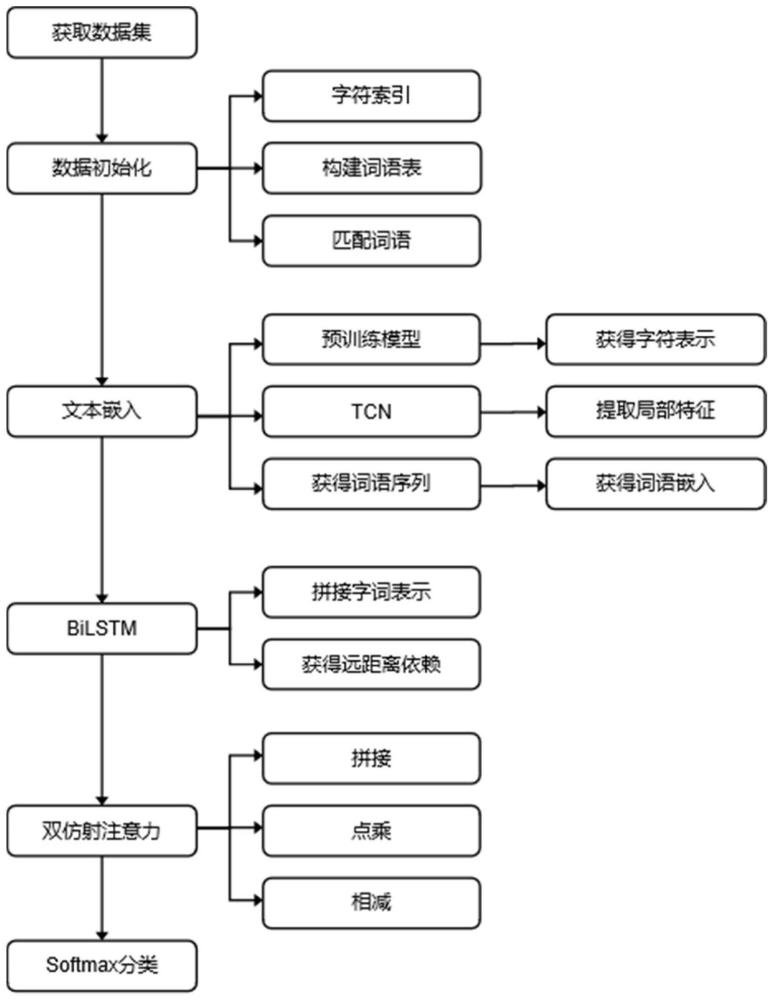
3、step1、获取静脉血栓栓塞症中文电子病历数据集,处理静脉血栓栓塞症中文电子病历原始文本,并对其进行实体标注;
4、step2、首先是数据初始化阶段,获取的静脉血栓栓塞症中文电子病历数据集,对文本中的所有字符进行索引;通过词典文件构建词语表,并使用词语表匹配句子中存在的词语,生成由词语首尾字符位置索引表示的词语序列;
5、step3、文本嵌入阶段,使用预训练模型对字符进行嵌入表示,并查找词语在序列中的索引得到词语的首尾字符位置嵌入;
6、step4、将字符序列分别与词语首尾位置嵌入拼接,拼接得到的两个嵌入充当开始层和结束层,使用bilstm提取字符远距离依赖关系;
7、step5、将提取完远距离特征的开始层嵌入和结束层表示传入双仿射注意力中,采用开始层与结束层表示拼接、点乘和相减的多种交互方式,实现词语首尾位置交互;
8、step6、将双仿射注意力的输出结果传入softmax函数用于标签分类。
9、进一步的,所述step1中,采用bio的标注方式对数据进行标注,形成静脉血栓栓塞数据集,并且按照8:1:1的比例划分数据为训练集,验证集和测试集。
10、进一步的,所述step2中,数据初始化阶段,采用先进的自然语言处理技术来预处理静脉血栓栓塞症中文电子病历数据集;数据初始化包括文本清洗、分词,以及构建高效的索引系统对文本中的所有字符构建字符索引。此阶段的关键在于利用专门为医疗领域优化的词典,包含了大量医学专业术语及其缩写,确保了实体边界的准确性和数据的丰富性。通过这样的预处理,本发明为深度学习模型的训练准备了高质量的输入数据。并依次对其建立在当前句子中的字符索引,以便于后面对词语首尾位置进行索引。
11、所述step2中包括:
12、数据集文件中的每一行文本被逐行读取并存储于一个列表中,接下来,对这个列表中的每一行进行遍历,处理包含有效内容的行,对于每行,通过空格分割来提取出单词和对应的标签,其中单词位于分割结果的首位,标签位于末位;如果开启了数字标准化选项,则将文本中的所有数字字符替换为“0”;随后,将提取的标签添加到标签字典中,处理后的单词添加到单词字典中;此外,遍历单词中的每个字符,将其添加到字符字典中,在所有行处理完毕后,统计单词字典、字符字典和标签字典中的元素数量,并通过检查标签字典中的标签来确定使用的标记方案;同时以实现更加方便地对比其他模型的效果,在此处适配两种不同类型的数据集标注方案;如果标签中同时存在以"b-"和"s-"开头的标签,则标记方案设为"bmes";如果只存在"b-"开头的标签,则设为“bio”。
13、作为发明的进一步方案,所述step3中,文本嵌入阶段包括:
14、step3.1将字符序列通过ernie-health预训练语言模型将文本字符转化为高维向量空间中的点,这些向量包含了字符的上下文语义信息。通过ernie-health的处理,能够捕捉到词语之间的细微语义差异,为后续的命名实体识别提供了精准的特征表示;
15、step3.2对字符使用时间卷积网络(temporal convolutional network)用于提取局部特征信息,并得到由词语首尾位置字符嵌入表示的词语嵌入。进一步增强了模型对局部依赖关系的理解能力。tcn通过其独特的膨胀卷积结构能够覆盖广泛的输入序列,捕捉到局部特征之间的关系,如医疗术语内部的结构信息。这对于理解如“双下肢深静脉血栓形成”这类复杂实体至关重要。tcn与ernie-health的结合,使得模型不仅能理解全局上下文,还能精确识别出局部特征,显著提升了命名实体识别的准确率和效率。
16、所述step3.1中,具体的,对于输入句子,将其字符序列通过ernie-health预训练语言模型编码为字向量序列,通过医疗词典匹配得到该句子包含的词语在字符序列中相应的开始位置序列和结束位置序列;
17、所述step3.2中,具体的,再对字符向量使用时间卷积网络提取特征,最后通过开始位置序列和结束位置序列得到词语边界开始字向量和词语边界结束字向量。
18、进一步地,所述step4中使用bilstm处理拼接后的嵌入向量是为了捕获字符之间的远距离依赖关系。bilstm通过其双向结构,可以同时考虑文本序列中每个字符前后的上下文信息,有效地提取出字符间复杂的语义关系。在实际操作中,bilstm层接收拼接后的向量作为输入,通过前向和后向的lstm单元分别处理文本信息,然后将两个方向的输出进行整合,得到了蕴含丰富上下文信息的序列表示。
19、进一步地,所述step4中,将词典匹配得到的词语首尾字向量分别与ernie-health编码的字符向量进行拼接;输入到bilstm中,捕获序列中的上下文信息和远距离依赖关系;bi-lstm层得到起始语义向量和结束语义向量,输入至双仿射注意力。
20、进一步的,所述step5中,在得到bilstm层处理后的序列表示之后,本步骤通过双仿射注意力机制进一步提炼和强化了文本中词语首尾位置之间的交互信息。首先,本发明将开始层和结束层的嵌入表示进行拼接,点乘和相减,通过这些操作模拟不同的交互方式,以充分捕捉实体边界间的复杂关系。
21、双仿射注意力机制通过对这些交互特征进行加权和聚合,能够精确识别和强调文本中关键实体之间的语义联系。这一步骤的关键在于,通过学习到的权重,模型能够自动识别哪些字符组合对于实体识别最为重要,进而优化实体边界的判定。
22、进一步地,所述step6中,将双仿射注意力机制的输出结果传入softmax函数,是为了将学习到的特征映射到实体标签的概率分布上。softmax函数作为多分类的常用激活函数,能够将输入的向量转换为一个概率分布,其中每个元素的值代表该字符属于某个实体类别的概率。在具体操作中,对于序列中的每个字符,模型通过softmax函数输出一个概率向量,表示该字符属于各个实体类别的可能性。然后,根据这些概率分布,本发明实现为序列中的每个字符分配最有可能的实体标签,从而完成命名实体的识别和分类。
23、本发明的有益效果是:本发明实现实体边界和语义信息的准确把握,改善vte患者中文电子病历命名实体识别过程中的实体边界和语义信息丢失问题;提高了医疗文本中命名实体识别效果,识别准确率和精度上有着不错表现。
本文地址:https://www.jishuxx.com/zhuanli/20240919/298486.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表