一种基于轻量化的篇章级蒙汉神经机器翻译方法
- 国知局
- 2024-09-19 14:34:16
本发明属于翻译方法,具体涉及一种基于轻量化的篇章级蒙汉神经机器翻译方法。
背景技术:
1、语言是各国和各民族之间进行沟通交流的桥梁,随着经济社会的不断发展,各国各民族之间的交流日渐频繁,蒙古语作为蒙古族和蒙古国的官方语言在国内乃至国际上都占据着重要的地位。但在使用蒙古语与汉语进行交流时普遍存在着语言不通这一问题,且蒙汉之间的交流常以篇章的形式出现,如政府文件、时事新闻等。这使得传统的人工翻译无法满足现有的翻译需求,机器翻译应运而生。作为目前主流机器翻译技术的神经机器翻译在句子级翻译中展现出良好的翻译性能和质量,但其依赖于大规模的语料库,且在篇章级翻译中表现略显不足,导致篇章级蒙汉神经机器翻译的研究存在滞后性,无法满足目前但现实需求。
技术实现思路
1、针对上述的技术问题,本发明提供了一种基于轻量化的篇章级蒙汉神经机器翻译方法,将上下文信息引入蒙汉神经机器翻译中,并对模型进行轻量化操作,可以更好利用句间关系进行篇章级翻译,使得模型翻译的准确率更高。
2、为了解决上述技术问题,本发明采用的技术方案为:
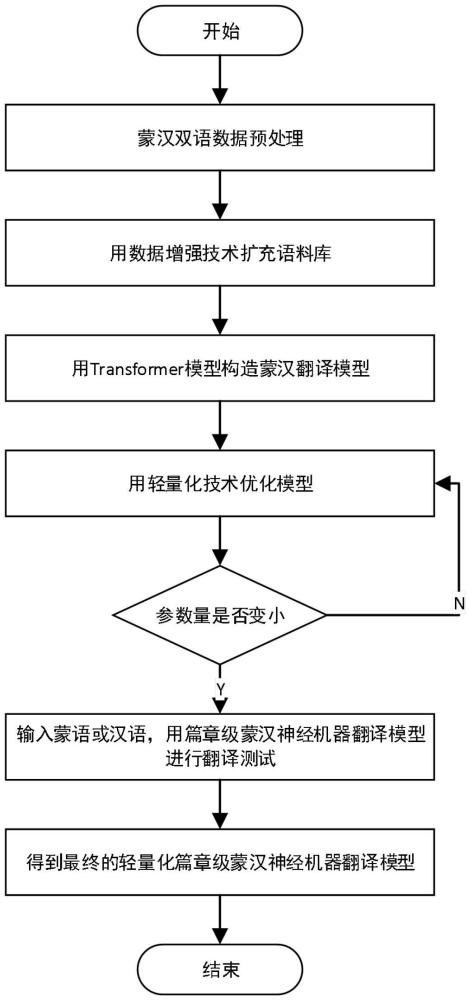
3、一种基于轻量化的篇章级蒙汉神经机器翻译方法,包括下列步骤:
4、s1、首先对篇章级蒙汉双语语料库进行数据预处理和数据增强;
5、s2、然后利用局部编码器和全局编码器进行编码;
6、s3、再利用历史上下文缓存机制辅助解码;
7、s4、通过轻量化注意力机制和前馈神经网络完成模型整体的轻量化;
8、s5、构建轻量化的篇章级蒙汉神经机器翻译模型进行蒙汉双语篇章级翻译。
9、所述s1中对篇章级蒙汉双语语料库进行数据预处理和数据增强的方法为:从cwmt2019上获取94065句对的蒙汉平行语料库作为数据集d1,该语料库包含政府相关工作报告、新闻和小说节选,能够有效保证数据的多样性;在蒙汉平行语料库中,随机选取1500对句子行为验证集,1000对句子作为测试集,剩余的91565句对作为训练集;此外通过回译的方法对从人民网下载15万句对的汉语单语语料进行数据增强,得到蒙古语单语语料,从而构造蒙汉伪平行语料库,将构造的伪平行语料库与d1结合作为数据集d2;针对上述数据集d1和d2进行预处理操作;首先,对语料库进行预处理,筛选删除重复的句子、非中文非蒙古文的字符,将语料格式转换为utf-8模式防止乱码的出现;然后,使用jieba分词技术和bpe子词切分对汉语进行分词处理;最后,使用bpe子词切分对蒙古语进行分词处理,得到预处理后的篇章级蒙汉双语语料库。
10、所述s2中利用局部编码器和全局编码器进行编码的方法为:在transformer模型的基础上添加全局编码器和局部编码器,使得模型能够从上下文中获取更多的语篇信息,之后通过历史上下文缓存机制获得历史上下文信息从而辅助解码器进行解码,提高翻译的准确率,得到最初的翻译模型;其中局部编码器为每个单词编码局部上下文;全局编码器从整个文本中获取每个词所关联的全局上下文,以理解句子间的依赖关系;最终形成混合的上文表示;若翻译的内容为单句文本时,全局编码则会退化成局部编码,由其可以直接传递到解码器,主导整个翻译过程。
11、所述局部编码器部分使用标准的transformer编码器结构为每个句子构建局部编码表示,对于输入序列中的第k个源句子xk,编码器部分利用前n-1层叠加的编码层来得到该句子的编码表示,将第n-1层的编码器表示视作每个句子的局部上下文编码;
12、所述全局编码器部分在局部编码器的基础之上添加的,通过句间相对自注意力机制从整个篇章中为每个词检索出相关的全局上下文信息,当获得全局上下文表示后,使用门控融合机制来融合局部和全局上下文表示,以获得编码器对源端的最终表示;最后,经过编码器输出隐藏状态的表示,作为解码器的输入之一继续模型的训练。
13、所述s3中利用历史上下文缓存机制辅助解码的方法为:解码器部分引入历史上下文信息缓存机制,缓存之前解码出的句子信息来处理篇章级的翻译,对于待解码句子yk,解码端输入包括句子的词嵌入以及位置嵌入信息。首先,当解码器解码第k个句子时,之前已经解码出的k-1个句子的信息可以作为额外的历史信息,指导当前句子的解码,然后解码器中的cross-attention模块从编码器的输出中读取蒙古语句子的表示hk,获取源端上下文信息,同时经过层归一化操作得到解码器的输出。
14、所述s4中通过轻量化注意力机制和前馈神经网络完成模型整体的轻量化的方法为:模型的轻量化将注意力机制和前馈神经网络进行轻量化,来重置模型原有的多头注意力和前馈网络层,将原有的多头注意力机制优化为单头注意力机制,减少计算量,并且对前馈神经网络进行轻量化,从原始的先膨胀再收缩,优化为先收缩再膨胀。
15、所述s5中构建轻量化的篇章级蒙汉神经机器翻译模型的方法为:获得最初的翻译模型后对模型进行轻量化操作,以避免参数多大导致的语篇割裂问题,利用轻量化的注意力机制和前馈神经网络对模型进行优化,获得最终的轻量化的篇章级蒙汉神经机器翻译模型。
16、所述通过回译的方法对汉语单语语料进行数据增强的方法为:将目标语言翻译为源语言生成伪平行语料库,再用于训练源语言到目标语言的翻译,将伪平行语料库加入到原始语料库中完成数据增强;在增强文本生成中采用具有可调温度的随机采样来代替beamsearch以确保多样性;这样数据增强用于为无标签数据生成标签;对于一个无标签数据x和k个数据增强的数据x,使用权重平均的方法为:
17、
18、其中是一个概率向量,wori和wk控制不同的数据增强的质量去生成标签。
19、所述transformer模型包含编码器和解码器两个部分,所述编码器为:篇章级蒙汉文本存在两种情况,第一种由多个句子构成的文本的翻译,在这时编码器将对文本中的每个单句先进行局部上下文编码,然后从整个文本中获取全局上下文,最终形成混合的上下文表示;第二种情况由单个句子构成的文本的翻译,此时只进行局部编码,将局部上下文直接传递到解码器中;
20、在局部编码器部分使用标准的transformer编码器结构为每个句子构建局部编码表示。对于输入序列中的第k个源句子xk,编码器部分利用前n-1层叠加的编码层来得到该句子的编码表示为:
21、
22、将第n-1层的编码器表示视作每个句子的局部上下文编码为:
23、
24、其中selfatten(q,k,v)表示自注意力机制,q,k,v分别表示查询、键和值,multihead()表示多头注意力机制;
25、在全局编码器部分通过句间相对自注意力机制从整个篇章中为每个词检索出相关的全局上下文信息,是在局部编码器的基础之上添加:
26、hg=multihead(seg-attn(hl,hl,hl))
27、其中seg-attn(q,k,v)代表检索句子全局编码的相对注意力机制;
28、当获得全局上下文表示后,使用门控融合机制来融合局部和全局上下文表示,以获得编码器对源端的最终表示,形成混合编码表示为:
29、g=σ(wg[hl;hg])
30、h=layernorm((1-g)·hl+g·hg)
31、其中wg为可学习的线性变换,[.;.]为串联操作,σ(.)代表着激活函数。
32、最后,经过编码器输出隐藏状态的表示,作为解码器的输入之一继续模型的训练;
33、所述解码器为:有了源端篇章文本的局部和全局编码器表示,解码器根据当前句子的源端表示以及之前翻译历史中的目标全局上下文和当前翻译中的局部上下文,生成目标端篇章译文;在解码器中通过将生成的以前的句子作为目标端全局上下文,逐句生成翻译,并通过之前以及翻译过的上文句子的网络表示作为扩展历史上下文;具体过程为:给定两个连续的句子,解码器的第l层首先在扩展的历史上下文上计算注意力,以获取目标端全局上下文历史信息:
34、
35、其中sg()为梯度传播停止操作,san(q,k,v)是词级别的相对注意力机制;
36、在注意力计算完毕后,交叉注意力模块会从源端编码器对应当前句子的编码表示hk中获得当前时刻所需的源端上下文,同时经过层归一化操作得到解码器的输出:
37、
38、所述将注意力机制和前馈神经网络进行轻量化的方法为:
39、将原有的多头注意力机制优化为单头注意力机制,减少计算量;轻量化注意力机制具体假设有一个n个输入token序列,每个token的维维数为dm,这些dm维的输入首先产生do维的输出,然后使用三个线性层同时映射这n个do维输出以产生do维的q,k,v值,最后使用缩放的点积注意力来建模n个token之间的上下文关系;综上使用单头注意力机制可以将计算量从o(dmn2)降低到o(don2),其中dm维表示输入、do维表示输出,do<dm;
40、对前馈神经网络进行轻量化,从原始的先膨胀再收缩,优化为先收缩再膨胀;轻量化的前馈神经网络由两个线性层组成,第一层将输入的维度从dm降至dm/r,而第二层将维数从dm/r扩展至dm,其中r为膨胀率,实现从原来的先膨胀再减小,优化为先减小再膨胀,降低模型的体量。
41、本发明与现有技术相比,具有的有益效果是:
42、本发明通过轻量化篇章级蒙汉神经机器翻译对篇章级文本进行翻译,将预处理和数据增强后的数据输入到翻译模型中进行翻译,本发明所提出的模型可以实现对篇章级翻译更加深入的理解翻译,使得翻译出的篇章更具有上下文语义关系,并通过轻量化处理使得模型能够在一定程度上避免语篇割裂问题,比传统的篇章级机器翻译模型的翻译准确率更好。本发明为各国交流提供便捷,有助于缓解语言不通带来的交流上的困难。而本发明的翻译模型可以根据上下文语义进行翻译,提升了翻译的准确性。
本文地址:https://www.jishuxx.com/zhuanli/20240919/298902.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表