一种内含感知增强模块的SwinTransformer自适应图像融合方法
- 国知局
- 2024-09-19 14:38:59
本发明属于图像处理,具体涉及一种内含感知增强模块的swintransformer自适应图像融合方法。
背景技术:
1、近年来,随着深度学习技术的发展,图像融合任务取得了显著进展。在卷积神经网络(convolutional neural networks,cnn)强大的特征提取能力下,融合图像的性能得到有效提升。然而,基于cnn的融合方法存在一些问题,例如不能充分捕获源图像之间的全局上下文信息,仅能获取局部信息。同时,随着网络深度增加,底层信息(如边缘、线条等)在卷积层中可能会丢失,从而影响融合效果。因此,引入注意力机制来捕获全局特征关联变得至关重要。注意力机制的核心在于为特征图的每个位置分配权重,以提高模型的表征能力和决策准确性。
2、近年来,transformer从自然语言处理(nlp)领域被引入计算机视觉领域,用于解决与图像相关的问题,并取得了显著成果。相比传统的cnn,transformer通过自注意力计算,能关联图像的全局信息。改进型的swin transformer甚至在计算复杂度与图像大小成线性关系的条件下,取得超过cnn的性能效果,可替代其作为图像分类和密集识别等任务的通用骨干。基于swin transformer的方法,如swinfuse,以自编码网络为框架,在视觉效果和客观评价上较以往的图像融合方法有了巨大的提升。然而,目前现存的以自编码网络为框架的图像融合算法(包括swinfuse)大多采用手工融合策略,无法适应复杂的环境。此外,基于swin transformer的图像融合算法容易将注意力倾向于亮度较高的像素,导致在可见光图像处于浓雾、强光或弱光等具有挑战因素的条件下易受到影响,融合质量将急剧下降,这不利于在航空、航天、医疗等领域的实际应用。
技术实现思路
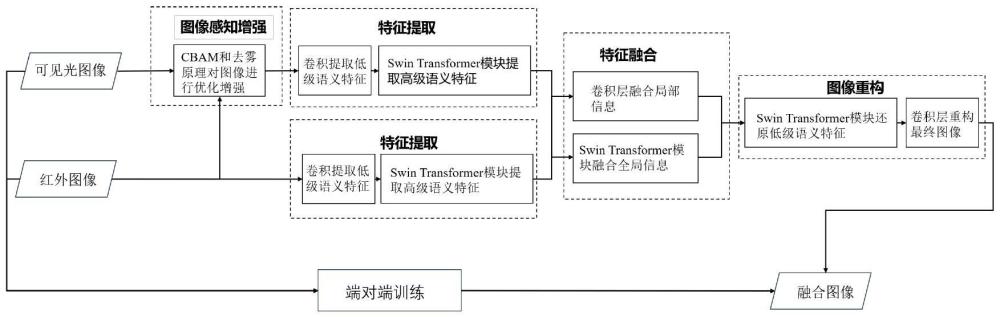
1、为了克服现有技术的不足,本发明提供了一种内含感知增强模块的swintransformer自适应图像融合方法,其特点在于对可见光图像根据场景环境进行优化增强,并采用自适应融合策略实现图像融合。该方法实现步骤为:1)根据实际的场景条件,结合红外图像特征对可见光图像进行优化增强;2)对优化后的可见光图像与输入的红外图像使用卷积操作获得低层特征图,并通过嵌入编码得到特征向量;3)利用基于swin transformer的特征提取模块获取图像的全局语义信息,生成高层特征图;4)利用自适应融合策略融合两种源图像的特征图;5)通过卷积层和swin transformer模块精细化地逐次还原图像的高级和低级语义特征,实现图像重构。
2、本发明提供的技术途径与现有技术相比,引入感知增强模块,并协同图像融合策略进行端对端的网络训练。相较于依赖先验知识的手动设计,这种方法无需人工干预,因此能够得到期望约束下的最佳策略。与此同时,感知增强模块根据应用场景对可见光图像进行优化,能够改善其在浓雾、强光、弱光等具有挑战因素的场景中的不良表现,从而增强模型在复杂场景下的鲁棒性。此外,采用自适应融合策略以更好地聚合源图像的互补信息,使融合图像在具有显著的红外目标的同时保持丰富的可见光细节,具有极高的实用价值。
3、本发明解决其技术问题所采用的技术方案如下:
4、步骤1:可见光图像感知增强;
5、利用感知增强模块pem提高可见光图像的质量;
6、步骤2:低级语义特征提取;
7、将预处理后的可见光图像和原始的红外图像通过三次连续卷积得到低层特征图;
8、步骤3:高级语义特征提取;
9、将低层特征图进行嵌入编码以展平高、宽维度,生成符合swin transformer处理要求的序列向量:
10、
11、其中,表示编码后的输入序列,reshape(.)表示图像变换操作;
12、将序列向量送入2个基于swin transformer的特征提取模块estb中,获取图像的全局上下文;每个estb模块由6个swin transformer层组成;
13、在通过两个estb模块后,对高级语义特征进行归一化处理,并将其形状重新变换成特征图矩阵:
14、
15、其中为图像高级语义特征,为形状变换后的高层特征图;unreshape(.)图像变换操作;
16、步骤4:自适应特征融合;
17、编码器完成图像特征提取后,将红外和可见光特征图输入交叉自注意力cmsa模块中;该模块同时接收来自两种源图像的特征图,针对其中一个源图像的特征图,根据自身得到查询矩阵q,而根据另一个源图像的特征图得到键矩阵k和值矩阵v,进行自注意力计算;
18、
19、其中,为交叉注意力计算完成后的源图像各自的特征图,cmsa中包含2层stb,用于得到两张源图像的全局关联特征;
20、输出的交互特征图将被作为两个分支的输入,其中一个分支在经过卷积层特征增强后,将两个源图像的特征图进行通道拼接;随后,经过三个卷积层将通道数降到原始通道数,完成局部信息融合;另一分支则直接拼接,经过一个卷积层降维融合后输入fstb实现全局特征增强,完成全局信息融合;最后,将局部融合信息和全局融合信息相加得到融合后的特征图:
21、
22、其中与分别表示局部融合信息和全局融合信息,conv表示卷积操作,cat为拼接操作,将两张特征图的通道维度直接拼接;fstb为融合自注意力层,包含6层stb,用于增强融合后图像的全局特征;
23、步骤5:图像重构;
24、利用transformer模块和基于cnn的解码器,将融合后的深度特征映射回图像空间;
25、首先,将融合图像的特征图输入基于swin transformer的解码器模块rstb中,精细化融合特征图中的高级语义特征,并从全局角度恢复融合的低级语义特征;接着,通过卷积减少融合特征图的通道数量,生成最终的融合图像;
26、步骤6:模型训练;
27、对于自编码器结构的图像融合算法,训练分成两个阶段;第一阶段,训练自编码器,即先训练编码器和解码器,使模型具有提取图像信息和重构图像的能力;在第一阶段训练完成后,固定编码器和解码器的参数,训练融合策略和感知增强模块,以实现完整的图像融合算法;整个过程采用端对端的训练;
28、步骤7:测试验证:
29、已训练好的模型通过测试数据集检验,根据含有不同挑战因素场景下的测试数据集得到融合结果的主客观指标评价来验证模型的有效性。
30、优选地,所述pem基于去雾原理:
31、i(x)=j(x)t(x)+a(1-t(x)) (1)
32、其中i(x)和j(x)表示观察到的有雾图像和其无雾图像推理;t(x)是传输图,也称透射率;a是全球大气光;
33、将式(1)进行变形:
34、j(x)=k(x)i(x)-k(x)+b (2)
35、其中,b是一个常量偏置,默认为1;
36、将k(x)视为源图像到预处理图像的特征转换图,利用红外和可见光图像的特征来估计k(x);将输入的可见光原图像与k(x)代入式(2)计算得到j(x),再通过sigmoid函数激活得到优化后的可见光图像。
37、优选地,所述rstb结构和estb完全一致,由6个stb层组成。
38、本发明的有益效果如下:
39、(1)感知增强模块协同图像融合策略进行端对端的网络训练。相较于依赖先验知识的手动设计,这种方法无需人工干预,能够得到期望约束下的最佳策略。
40、(2)设计了一个可见光图像感知增强模块。结合红外特征,通过对在浓雾、强光、弱光等具有挑战因素场景中表现不佳的可见光图像进行优化增强,使模型在含挑战性因素的条件下仍具有较强的鲁棒性。
41、(3)图像融合算法采用自编码器框架,并设计了自适应融合策略。自编码器框架使模型在训练图像特征提取和重构时能利用质量更高、效果更好的大量可见光数据集。同时,自适应融合策略有利于在各种不同的复杂场景下适用,算法能根据当前红外和可见光图像的特性选择期望的有用特征进行融合,得到更好的融合性能。
42、(4)通过实验验证了算法的有效性。在包含多种复杂场景的tno数据集和含有强光环境的roadsense数据集上,我们的方法相比其他主流的图像融合算法具有更强大的视觉感知能力,可更好的克服各种挑战场景带来的不利影响,同时具有更高的客观评价。特别是相比于同样以swin transformer为骨干网络的swinfuse模型,本发明的方法有显著的性能提升。
本文地址:https://www.jishuxx.com/zhuanli/20240919/299383.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表