基于STM32的聋哑人辅助系统
- 国知局
- 2024-10-09 14:37:46
本发明涉及聋哑人辅助通信,尤其涉及基于stm32的聋哑人辅助系统。
背景技术:
1、聋哑人群面临着语言交流的困境,传统的手语翻译辅助设备存在诸多局限性,目前,现有的聋哑人穿戴式辅助设备大多采用形变材料和姿态传感器来捕捉手指动作和手部姿态,以实现手语的识别和翻译,然而,这些设备普遍存在价格昂贵、功能单一、反馈不足等问题,传感器价格昂贵导致设备成本高昂,而且常规设备缺乏有效的反馈系统,无法准确指示用户何时开始或结束手语动作,限制了聋哑人与正常人的有效交流。
2、然而,现有技术未能完全满足聋哑人群的需求,亟待解决的问题包括:传统穿戴式辅助设备成本高昂,限制了其普及和使用;设备缺乏有效的反馈系统,导致交流效率低下;同时,目前市场上缺乏专门用于手语训练和学习的器材,以及手语考试的相应器材。
3、因此,迫切需要一种新型的聋哑人辅助系统,能够降低成本、提供有效的反馈、支持手语训练和学习,以及满足手语考试的需要,从而促进聋哑人与外界的有效沟通和交流。
技术实现思路
1、基于上述目的,本发明提供了基于stm32的聋哑人辅助系统。
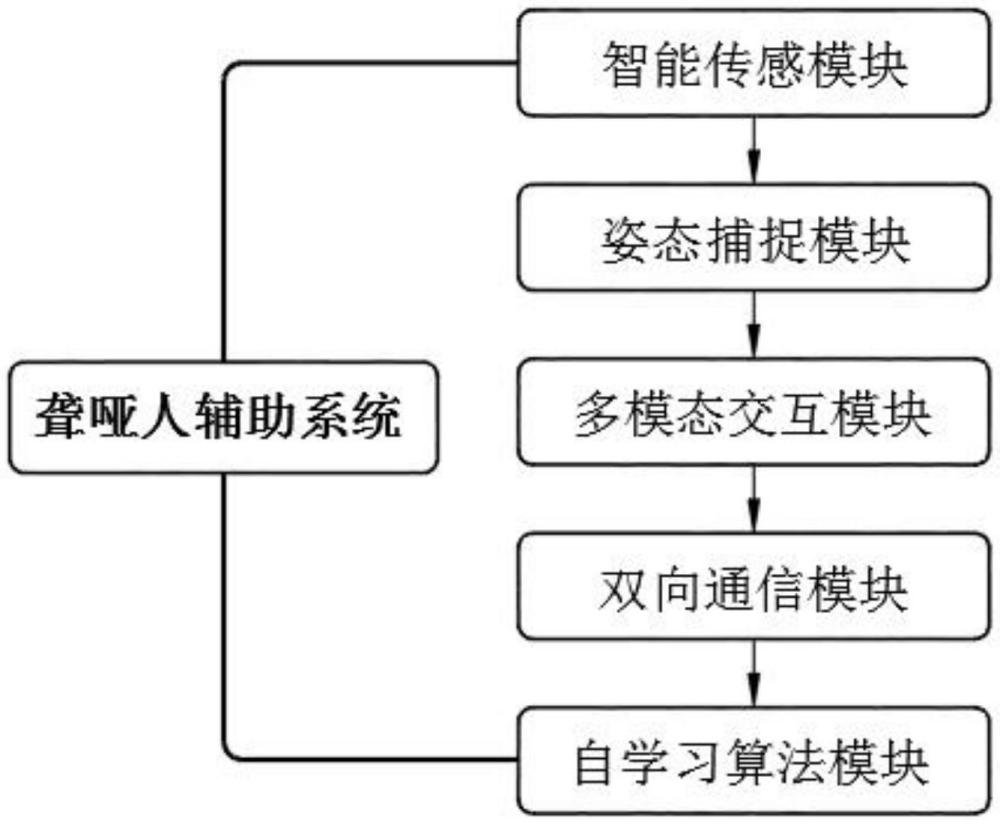
2、基于stm32的聋哑人辅助系统,包括智能传感模块、姿态捕捉模块、多模态交互模块、双向通信模块以及自学习算法模块;其中,
3、智能传感模块:集成有柔性压力传感器和电容式接触传感器,并安装于每个手指的指节位置,用于对手指每一次弯曲和接触的动态数据进行捕捉;
4、姿态捕捉模块:结合来自智能传感模块的手指动态数据与内置加速度计和陀螺仪的数据,通过stm32微控制器进行数据融合处理,实现手部及手腕的三维姿态实时捕捉;
5、多模态交互模块:基于姿态捕捉模块输出的三维姿态数据,通过微型oled显示屏提供视觉反馈,同时通过微型振动马达在预定手指产生触觉反馈,生成手语识别结果;
6、双向通信模块:通过stm32微控制器控制蓝牙模块,实现与外部设备的数据交换,并将多模态交互模块的手语识别结果转化为语音输出,同时接收外部语音输入,通过语音到文本转换功能转换为手语动作指示或文字描述,并输出至多模态交互模块显示;
7、自学习算法模块:使用深度学习算法分析由双向通信模块收集的用户反馈与多模态交互模块的操作数据,自动优化手语识别算法和反馈机制,并将改进后的算法周期性通过stm32微控制器更新至各模块,提升系统整体性能。
8、进一步的,所述智能传感模块包括数据捕捉单元、信号转换单元以及数据处理单元;其中,
9、数据捕捉单元:包括有柔性压力传感器和电容式接触传感器,每种传感器均安装于手指的每个指节位置,其中柔性压力传感器用于捕捉手指弯曲时产生的压力变化,通过测量压力改变来计算弯曲角度,电容式接触传感器则侦测手指间的相互接触;当两个手指的指节接触时,传感器间的电容值发生变化,从而能够确定接触事件的发生;
10、信号转换单元:接收来自数据捕捉单元的模拟信号,将其转换为数字信号,具体使用高精度模数转换器,确保从柔性压力传感器和电容式接触传感器接收到的模拟信号准确转换为数字形式,以便后续处理;
11、数据处理单元:接收信号转换单元输出的数字信号,通过设置阈值和执行基本算法,包括滤波和峰值检测,确定手指的具体动态,包括弯曲度和接触模式,并生成对应的数据包。
12、进一步的,所述数据处理单元包括:
13、数据预处理:接收信号转换单元输出的数字信号后,首先进行信号的预处理,具体使用数字低通滤波器去除信号中的高频噪声,滤波器采用巴特沃斯滤波算法,其传递函数公式为:
14、其中,h(s)为滤波器的传递函数,表示输入信号经过滤波器处理后的输出,s是拉普拉斯变换变量,ωc是截止频率,n是滤波器的阶数;
15、动态检测:经过滤波后的信号进入动态检测阶段,通过设置阈值来识别手指的弯曲度和接触模式,弯曲度的确定是通过比较压力传感器信号的幅值与预设的弯曲度阈值,接触模式的识别则是通过比较电容传感器信号的变化是否超过接触阈值;弯曲度阈值计算公式为:tbend=μ+k·σ,其中,tbend为弯曲度阈值,用于判断手指是否达到足够的弯曲度以识别为有效手势,μ是信号的平均值,σ是信号的标准偏差,k是调节因子,用于根据用户的手部灵敏度调整;接触模式阈值计算公式为:tcontact=δc>τ,其中,tcontact为接触模式阈值,用于确定手指间接触是否足够明显以识别为有效接触,δc表示电容变化量,τ是接触敏感度阈值;
16、峰值检测:对于弯曲度和接触模式的每一次有效活动,执行峰值检测算法,确定活动的精确时刻和持续时间,峰值检测算法采用改进的z-score算法,通过计算数据点的z分数来识别峰值,具体公式为:其中,z为数据点的z分数,用于判断数据点是否为峰值,x是当前数据点,μ和σ分别是窗口内数据的均值和标准偏差,当z超过设定的z分数阈值时,该点被认定为峰值;
17、数据包生成:基于检测到的弯曲度和接触事件,生成数据包,该数据包包括时间戳、事件类型、事件持续时间和强度的信息。
18、进一步的,所述姿态捕捉模块包括数据接收单元、数据融合处理单元以及三维姿态重建单元;其中,
19、数据接收单元:用于接收来自智能传感模块的手指动态数据以及内置加速度计和陀螺仪的数据,其中智能传感模块提供的数据包括手指各指节的弯曲角度和接触状态,而加速度计和陀螺仪用于提供手部和手腕在空间中的加速度和旋转角度信息;
20、数据融合处理单元:使用stm32微控制器执行数据融合算法,整合接收到的数据,数据融合具体采用扩展卡尔曼滤波器算法,具体通过以下状态更新和测量更新公式进行;
21、状态预测公式为:其中,代表在时间步k的状态预测值;f为非线性状态转移函数;代表在时间步k-1的状态估计值;uk代表控制输入;
22、测量更新公式为:其中,kk为卡尔曼增益;zk代表在时间步k的测量值;h为测量函数,用于将状态空间映射到测量空间;
23、三维姿态重建单元:基于融合后的数据,利用三维重建算法计算手部和手腕的实时三维姿态,该三维重建算法利用前述卡尔曼滤波器输出的状态估计,结合手部的几何模型,计算每个关节的实际位置和方向。
24、进一步的,所述三维姿态重建单元包括:
25、状态估计接收:首先接收来自数据融合处理单元的状态估计值,包括手部各关节的预测位置和速度;
26、手部几何模型加载:加载预定义的手部几何模型,该模型用于定义了手部的骨架结构,包括每个关节的长度和相对位置;
27、关节位置的逆向运动学解算:使用逆向运动学算法来确定每个关节的实际位置,该算法基于以下方程求解:其中,θ为关节角度;p为从当前关节到目标位置的向量;l为关节之间的长度;
28、方向向量的确定:为每个关节计算方向向量,使用四元数表示关节的方向,四元数是通过以下方式从卡尔曼滤波器的输出转换得来:其中,q为关节的四元数表示;θ为关节旋转角度;为旋转轴的单位向量;
29、数据包的构建和发送:根据每个关节的位置和方向,构建数据包,其中包括所有关节的状态信息。
30、进一步的,所述多模态交互模块包括视觉反馈单元、触觉反馈单元以及结果生成单元;其中,
31、视觉反馈单元:包括微型oled显示屏,用于实时显示手部三维姿态以及手语识别的进度和结果,具体当三维姿态数据从姿态捕捉模块接收后,视觉反馈单元将这些数据转换为图形用户界面的形式,展示每个手指的位置和姿态,以及整个手势的识别状态,以直接反映用户的手部动作,辅助用户自我校正和学习手语;
32、触觉反馈单元:包括多个微型振动马达,分别安装在手套的预定手指位置上,当手语动作被识别或需要特定的用户注意时,将会根据手语识别结果和三维姿态数据的分析,激活相应手指的振动马达,振动的强度和持续时间根据手语动作的复杂性和识别的紧急性进行调整,提供即时的物理反馈;
33、结果生成单元:基于从视觉反馈单元和触觉反馈单元收集的用户反应和三维姿态数据,运用预设的支持向量机算法分析手部动作,生成手语识别结果,并与预定义手语库中的匹配;接着将识别的结果被转换为可视化数据,显示在oled屏幕上。
34、进一步的,所述结果生成单元包括:
35、特征提取:首先接收手部三维姿态数据,并提取预定特征,该特征包括手指的弯曲角度、手指间的相对位置以及手部的整体形态,特征向量形成公式为:
36、其中,xi表示从手部姿态数据中提取的第i个特征;
37、支持向量机模型应用:使用预先训练的支持向量机模型来分析提取的特征,并识别相应的手语动作,支持向量机模型基于以下分类函数进行决策:
38、其中,αi代表第i个支持向量的拉格朗日乘子;yi为第i个支持向量的标签;为核函数,用于计算输入向量与支持向量之间的相似度;b为偏置项;
39、手语库匹配:根据支持向量机模型的输出,将识别的手语动作与预定义的手语库进行匹配,确定最接近的手语表示,具体配过程基于支持向量机提供的决策置信度进行;
40、结果可视化:将识别的手语结果转换为可视化数据,包括动画或图标,显示在微型oled屏幕上。
41、进一步的,所述双向通信模块包括语音输出单元、语音接收单元、语音识别单元以及指令转换单元;其中,
42、语音合成单元:包括文本语音引擎,用于将多模态交互模块识别的手语结果转换为语音输出,具体将接收手语识别结果的文本描述,并生成相应的语音;
43、语音接收单元:通过集成的麦克风阵列接收外部语音输入,并通过噪声抑制和回声消除技术,确保接收到的语音信号清晰无干扰;
44、语音识别单元:包括语音识别引擎,用于将接收到的语音信号转换为文本;
45、指令转换单元:用于接收asr引擎生成的文本描述,并将其解析为手语动作指示,以供用户执行或学习。
46、进一步的,所述自学习算法模块包括数据收集单元、深度学习训练单元、优化算法单元以及性能评估单元;其中,
47、数据收集单元:用于从双向通信模块和多模态交互模块收集数据,包括用户的语音反馈、手语识别结果的准确性反馈以及用户与系统交互的详细记录,为算法训练提供必要的输入;
48、深度学习训练单元:使用收集的数据来训练深度学习模型,用于处理时间序列数据,包括手势动作序列,训练过程中模型通过最小化识别错误和优化参数来学习识别手语的最有效方式;
49、优化算法单元:基于深度学习模型的输出,自动调整手语识别算法和用户反馈机制,具体包括调整算法参数包括学习率或层数,以及改进用户界面的反馈方式,包括调整反馈的时效性和相关性;
50、性能评估单元:用于定期评估优化后的手语识别算法的性能,使用准确率、召回率和f1分数的指标来衡量改进的效果。
51、本发明的有益效果:
52、本发明,通过采用多模态交互技术和自学习算法,显著提高了手语识别的准确性和交互的自然度,通过集成视觉反馈和触觉反馈机制,该系统不仅能实时显示手部三维姿态,还能根据手语动作提供即时的触觉反馈,极大地增强了聋哑用户的学习和使用体验,此外,该系统的自学习功能能够根据用户的交互行为自动优化识别算法和反馈机制,进一步提升系统的响应性和用户满意度。
53、本发明,采用了成本较低的传感器和组件,降低了生产成本,使得这种高效能的聋哑人辅助系统更加易于普及,系统的双向通信功能也允许聋哑人与听力正常的人之间进行有效沟通,不仅帮助聋哑人更好地理解外界,也使得听力正常的人能够理解聋哑人的需求和表达,从而提升了社会的包容性和聋哑群体的生活质量。
本文地址:https://www.jishuxx.com/zhuanli/20241009/305901.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表