基于改进DeepSort框架的隧道场景中车辆跟踪方法
- 国知局
- 2024-10-09 14:38:27
本发明属于智能交通领域,涉及车辆跟踪技术,具体涉及一种基于改进deepsort框架的隧道场景中车辆跟踪方法。
背景技术:
1、目前,人工智能的迅速发展为隧道场景中车辆行驶轨迹的实时感知提供了新的解决方案和途径。通过深度学习和计算机视觉算法,基于隧道监控视频对道路上的车辆进行实时检测和追踪,能提取和识别车辆的位置、类别、速度信息,实时捕捉和记录车辆的状态。交通调度方面,通过对车辆的检测和跟踪,统计各个路段的车流量及车速情况,进而分析当前路段的交通拥挤状况及车辆行为,使得交通管理部门合理有效地进行实时车辆调度及道路疏导。交通安全预警方面,通过捕捉车辆轨迹来进行车辆信息的提取,判断车辆是否出现逆行、违规变道的驾驶行为,从而预防交通事故的发生。
2、隧道内外光线强弱变化大,驾驶员进出隧道时,眼睛无法快速适应亮度变化,需要提前降低车速,同时隧道中行驶有严格速度限制,因此车辆在进出隧道时车速反差大。隧道往往比连接道路窄,行驶空间相对狭小,车辆间容易相互遮挡。隧道环境昏暗,受照明不足和弯曲道路设计的影响能见度通常较差,导致监控摄像头画面模糊。这些都使得车辆检测和跟踪技术难以准确捕捉和跟踪车辆的位置和动态信息。
技术实现思路
1、发明目的:为了克服现有技术中存在的不足,提供一种基于改进deepsort框架的隧道场景中车辆跟踪方法,针对车辆检测模型和重识别模型现存问题进行改进,提高了隧道监控系统的实时性和准确性,对智慧交通系统发展具有重要意义。
2、技术方案:为实现上述目的,本发明提供一种基于改进deepsort框架的隧道场景中车辆跟踪方法,包括如下步骤:
3、s1:设计用于提取关键特征信息的通道空间融合注意力机制ca;
4、s2:构建基于通道空间融合注意力机制ca的隧道场景中车辆检测模型yolov5-am-vd-ts,用于检测运动车辆位置及类别并获取图像信息;
5、s3:运动预测与状态估计:通过卡尔曼滤波预测目标对象在未来帧的位置以及状态;
6、s4:设计用于提高网络特征提取能力的通道注意力机制se;
7、s5:基于通道注意力机制se,构建隧道场景中车辆重识别模型iresnet50-vri-ts,用于提取车辆检测框的运动特征和表观特征;
8、s6:目标车辆关联匹配:将目标关联问题转换为求解最优匹配的问题,对帧与帧之间各个目标进行最优匹配;
9、s7:联合车辆检测模型yolov5-am-vd-ts和车辆重识别模型iresnet50-vri-ts,构建基于改进deepsort框架的隧道场景中车辆跟踪模型dtm-yavt-ivt,进行车辆跟踪。
10、进一步地,所述步骤s1具体为:ca是一种为轻量级网络设计、简单灵活高效的注意力机制,通过将通道注意力分解为两个沿着不同方向聚合特征的1d特征编码,形成一对方向感知和位置敏感的特征图,用来增强感兴趣的目标表示,在提升网络精度的同时不增加计算开销;
11、每次输出的特征图在经过ca模块时都要进行以下的计算步骤:
12、首先输入大小为512×38×38的特征图,其中512是通道数,38和38分别是高度和宽度,随后经过空间池化操作,xavg pool对每个通道执行沿宽度38的全局平均池化,得到一个512×38×1的特征图,捕捉高度方向的信息,yavg pool对每个通道执行沿高度38的全局平均池化,得到一个512×1×38的特征图,捕捉宽度方向的信息;随后进行特征融合与转换,concat+conv2d模块将两个池化后的特征图在通道维度上拼接,形成512/r×1×76的特征图,其中r代表重要性权重,通过学习得到,用于确定输入序列中每个元素的重要性,1×11×1的二维卷积层来融合和转换特征;随后进行批量归一化与非线性激活,batchnorm+non-linear模块对卷积后的特征图进行批量归一化,并通过非线性激活函数增加模型的表达能力;随后进行分裂与二维卷积,split模块将批量归一化和激活后的特征图分裂为两个512×1×38和512×38×1的特征图,conv2d模块通过另外两个1×11×1的二维卷积层分别处理分裂后的特征图;然后对两个卷积后的特征图应用sigmoid激活函数,生成两个注意力图,这两个图将分别在宽度和高度上对输入特征图进行重标定;然后进行特征重权,re-weight将通过sigmoid激活的注意力图乘以原始的512×38×38输入特征图,以此来重新加权原始特征,强化或弱化某些特征;最后输出加权后的特征图。
13、yolov5模型主干网络中的csp模块替代了传统的残差连接结构,能够有效地减轻梯度消失问题并提取更丰富的特征。通过在csp模块后插入ca注意力机制,可以帮助网络更加聚焦于对车辆检测有用的特征,如车辆的位置、形状、颜色、大小,提高关键信息的提取能力,而且对背景无关信息如复杂的隧道环境和道路场景做出抑制,从而提高车辆检测的准确性和效率。csp模块和ca注意力机制的结合可以实现一种协同作用,不仅可以加快特征的传播和信息流动,还可以提高模型的鲁棒性和对抗性,使得网络更具表达能力和学习能力。
14、进一步地,所述步骤s2中构建基于通道空间融合注意力机制ca的隧道场景中车辆检测模型yolov5-am-vd-ts的具体方法为:在现有的yolov5网络的基础上,在主干网络的三个csp模块后嵌入ca模块,筛选出车辆检测有利的重要特征而过滤掉那些无用的边缘特征,从而构建用于隧道场景中车辆检测的yolov5-am-vd-ts模型。
15、进一步地,所述步骤s2中车辆检测模型yolov5-am-vd-ts的运行流程为:输入的隧道车辆图像首先经过focus模块进行切片操作,输出尺寸为304×304的特征图,然后经过cbl模块提取输入图像特征后进行归一化处理,csp1结构进行残差块堆叠,输出尺寸为38×38的特征图,然后采用ca模块筛选关键特征信息,输出尺寸为19×19的特征图,然后通过spp空间金字塔池化模块进行最大池化操作,输出尺寸为19×19的特征图,然后经过fpn和pan结构进行不同尺度特征图的融合,依次经过两个csp2+cbl+上采样+concat模块结构和两个csp1+cbl+concat结构,最后经过nms操作,输出尺寸为19×19的特征图。
16、进一步地,所述步骤s3中运动预测与状态估计的具体过程为:
17、采用卡尔曼滤波作为运动模型,卡尔曼滤波根据第t-1帧中的车辆边界框进行建模后,能得到第t帧中目标的预测框;然后,通过目标检测方法将第t帧的检测框作为观测值,结合预测框和检测框,得到当前视频第t帧所有目标检测框的最优估计值;最后,利用最优估计值得到第t+1帧中该目标新的预测值,通过不断迭代,最终逼近目标的实际值,采用一个8维空间来描述隧道场景中车辆轨迹在某一时刻的状态,表示公式为:
18、
19、其中,(u,v)为车辆检测框的中心坐标,r为纵横比,h为边框高度,(x,y,r,h)为(u,v,r,h)的速度信息。
20、进一步地,所述步骤s3中状态向量的预测方程计算公式如下所示,描述了隧道场景中车辆运动状态从t-1帧到第t帧的转移过程,f为状态转移矩阵,在车辆运动状态转移过程中,还需要对车辆运动状态的不确定性做描述;卡尔曼滤波假设系统中的状态变量都服从高斯分布,因此用均值和方差来描述每个变量,
21、x=fxt-1
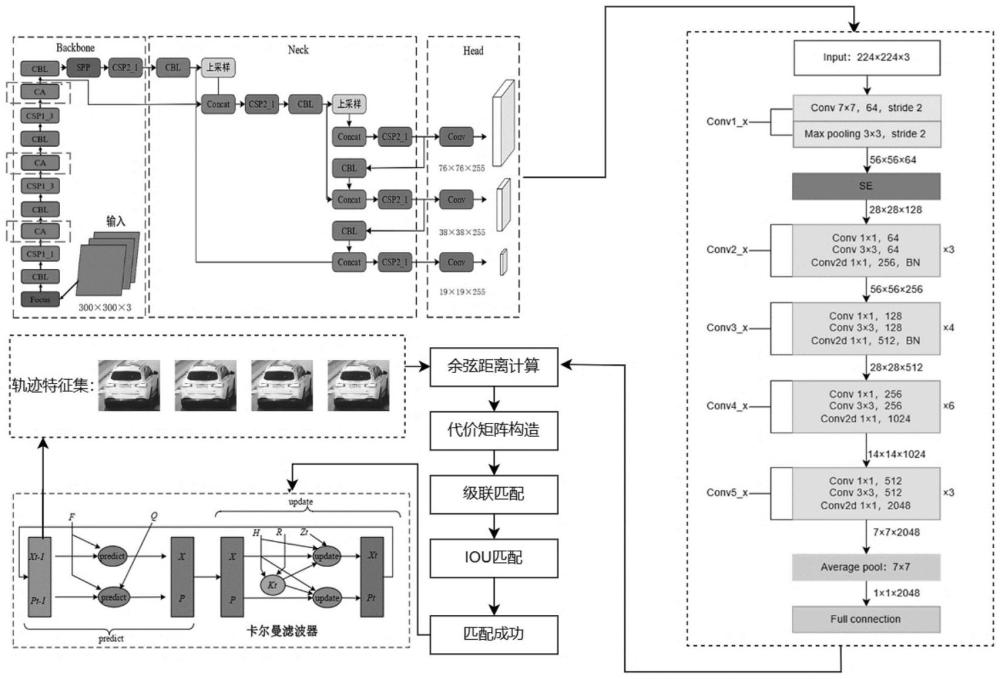
22、下式对车辆运动状态以及车辆运动状态的不确定性进行了初步估计,p为协方差矩阵,用来描述车辆运动状态的不确定性,p中的值越大,表示运动状态的不确定性越高,q为系统噪声矩阵,用来描述车辆运动状态预测中的噪声,
23、p=fpt-1ft+q。
24、进一步地,所述步骤s4具体为:se模块是一种易于插入的通道注意力机制,通过压缩和激励操作在特征通道间引入可学习的权重,有效捕捉通道间的关联性,提高网络特征提取能力;
25、每次输出的特征图在经过se模块时都要进行以下的计算步骤:
26、首先,设定卷积层的输入特征图尺寸为56×56×64,并将其作为se模块的输入;随后,进行全局池化操作,将特征图压缩为一个大小为1×1×64的向量,实现了特征的聚合与降维;然后进行激励操作,该部分由两个全连接层构成,并设置了两个缩放参数m,分别为2和4,第一个全连接层有64×2个神经元,接受1×1×64的输入,并输出1×1×64×2的特征图,第二个全连接层有64个神经元,它以1×1×64×4的特征图作为输入,输出为1×1×64的向量;随后执行重新加权操作,将激励部分的输出结果作为每个特征通道的权重值,这些权重值与初始特征图依次相乘,从而建立起与初始特征之间的联系,实现了对初始特征的重新定义;这一过程实质上是对特征进行了重新加权,以便更多地关注在激励阶段被判定为重要的通道。通过上述步骤,完成了对前层输出的se模块计算,并将结果作为下一层的输入。这一操作略微增加了计算量,但它有效地建立了通道间的复杂联系,从而优化了特征的提取精度。
27、resnet50的残差模块会传递原始的特征信息,将se注意力机制插入在残差模块前可以帮助网络动态地学习每个通道之间的权重,以增强特定通道对特征的贡献,使网络能够更好地捕捉和利用重要的特征,从而提升网络的性能和泛化能力。
28、进一步地,所述步骤s5中车辆重识别模型iresnet50-vri-ts的构建方法为:在现有的resnet50的基础上,在最初的残差模块前插入se模块解决目标识别信息丢失问题,改善模型特征提取能力,从而构建用于隧道场景中车辆重识别的iresnet50-vri-ts模型;
29、车辆重识别模型iresnet50-vri-ts的工作流程为:首先将隧道内的车辆图像大小调整为224×224×3输入到网络中,采用步长为2的7×7的卷积核进行卷积运算得到112×112×64的车辆特征图,再利用步长为2的3×3最大池化层得到大小为56×56×64的特征图,然后采用se模块加强图像中关键外观特征,然后将特征图依次经过conv2_x中的3个残差结构运算输出56×56×256大小的特征图,并在conv3_x中经4个重复的残差单元处理得到28×28×512特征图,然后通过conv4_x中的6个残差结构运算得到的车辆特征图大小为14×14×1024,经过conv5_x的3个残差结构输出7×7×2048的整车特征图,最后采用7×7的平均池化和全连接层将特征图转化为1×1×2048的特征向量。
30、进一步地,所述步骤s6中目标车辆关联匹配包括匈牙利算法、级联匹配、iou匹配,将目标关联问题转换为求解最优匹配的问题,对帧与帧之间各个目标进行最优匹配,具体为:首先,对候选图像进行目标检测获得候选车辆检测框,将卡尔曼滤波预测为确定态的跟踪轨迹与检测到的目标框进行级联匹配,从而得到的结果分为三种情况:成功匹配的轨迹mt(matched tracks,mt)、未匹配的检测ut(unmatched tracks,ut)、未匹配的轨迹ud(unmatched detections,ud);在成功匹配的情况下,即预测边界框与当前帧的车辆检测边界框匹配,则只需要采用卡尔曼滤波完成轨迹更新;对于未匹配的检测和未匹配的轨迹的情况,需要计算交并比进行iou匹配;卡尔曼滤波预测为非确定态的跟踪轨迹与检测到的目标框则直接进行iou匹配,并计算其代价矩阵以作为匈牙利算法的输入实现匹配关联;
31、经过iou匹配后,对于成功匹配的情况,采用卡尔曼滤波器对之前的轨迹进行更新;对于未匹配轨迹的情况,如果此时该轨迹处于未确认状态,则直接删除该轨迹,否则需要失配达到一定次数后进入删除态;对于未匹配的检测的情况,即在当前帧中出现了新的目标,但预测边界框中不存在该新增目标,这种情况则需要为该目标初始化一个新的轨迹。
32、进一步地,所述步骤s7中基于改进deepsort框架的隧道场景中车辆跟踪模型dtm-yavt-ivt进行车辆跟踪的具体方法为:首先将隧道监控视频帧序列依次经过yolov5-am-vd-ts模型中focus模块、cbl标准卷积模块、csp1_x模块、ca模块、spp空间金字塔池化模块、非极大抑制模块、nms模块处理后,定位隧道监控目标车辆的位置;然后采用卡尔曼滤波根据车辆轨迹预测车辆在当前帧的8维状态向量,同时,车辆检测框经过resnet50-vri-ts模型中的conv1_x、se模块、conv2_x、conv3_x、conv4_x、conv5_x模块及7×7的平均池化输出全连接层前的1×1×2048维的车辆外观特征向量,并计算其与每条车辆轨迹最近100个成功关联的特征集的最小余弦距离,从而建立代价矩阵;然后经过匈牙利算法进行级联匹配,得到成功匹配的轨迹、未匹配的检测及未匹配的轨迹,同时,对于未匹配的检测和未匹配的轨迹再进行iou匹配;最后当检测框与预测框配对成功后,通过卡尔曼滤波更新对应的隧道场景中的车辆轨迹。
33、有益效果:本发明与现有技术相比,基于注意力机制对检测模型和重识别模型进行改进,提高了网络对车辆关键特征的提取能力,提出的基于改进deepsort框架的隧道场景中车辆跟踪方法,具有更好的mota、motp、idf1和ids,能有效跟踪隧道场景中车辆,提高隧道监控系统的实时性和准确性。
本文地址:https://www.jishuxx.com/zhuanli/20241009/305941.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表