一种结合音频视频信号的3D空间声源定位方法及装置与流程
- 国知局
- 2024-10-09 14:39:11
本发明涉及人工智能,特别是指一种结合音频视频信号的3d空间声源定位方法及装置。
背景技术:
1、声源定位,即估计声音来源位置,是智能家居场景中机器人平台的一项基本应用。仅检索声源方向的技术称为到达方向(doa)估计,而同时估计方位、仰角和距离的技术称为3d定位。传统的声源定位(ssl)问题通过基于信号处理(sp)的技术来解决,给定先前对环境的了解或声音传播模型的假设。然而,在嘈杂或高混响环境下,它们的性能受限。
2、近几十年来,基于机器学习的声源定位工作引起了越来越多的关注,例如将支持向量机(svm)子空间映射到声学空间进行说话人位置估计。由于计算硬件的发展,dl-based通过用大规模注释的数据训练网络,展示了相对于基于sp的方法的卓越性能。尽管有了这些进展,大多数现有的基于深度学习的工作要么考虑1d(方向角),要么考虑2d(方向角和仰角的声源定位问题,而忽略了半径的估计。然而,对于许多机器人应用而言,半径信息与方向角和仰角同样重要。只有少数研究进行了3d ssl,特别是使用小型机载麦克风阵列的情况。多种不同的异构传感器促进了多模态感知。音频和视觉具有特定于模态的限制,可以彼此补充。具体而言,音频具有360°的感知场,而视觉受到摄像机视野、遮挡和照明变化的限制。相反,声音背景噪声和混响会对音频感知能力产生负面影响,而对视觉没有影响。因此,音频-视觉融合可以在许多场景中取得期望的结果,其中ssl也是其中之一。例如,通过结合基于面部检测的视觉特征,可以改善1d doa估计。对于3d ssl,由于从小型麦克风阵列捕获的音频信号不能用于距离估计,一种解决方案是将视频部署到带有预定义超参数设置的信号处理策略中。
技术实现思路
1、为了解决现有技术存在的对声源半径的估计准确率低的技术问题,本发明实施例提供了一种结合音频视频信号的3d空间声源定位方法及装置。所述技术方案如下:
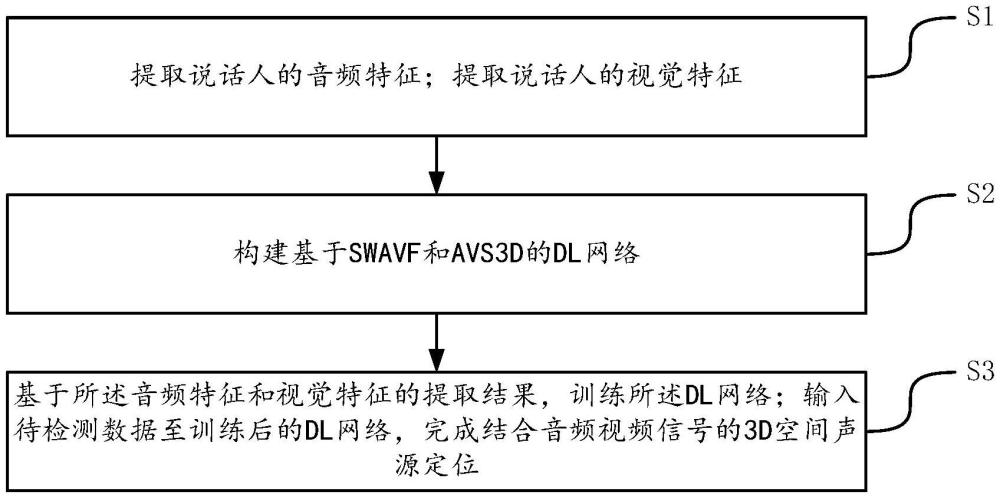
2、一方面,提供了一种结合音频视频信号的3d空间声源定位方法,方法包括:
3、s1、提取说话人的音频特征;提取说话人的视觉特征;
4、s2、构建基于swavf和avs3d的dl网络;
5、s3、基于音频特征和视觉特征的提取结果,训练dl网络;输入待检测数据至训练后的dl网络,完成结合音频视频信号的3d空间声源定位。
6、可选地,s1中,提取说话人的音频特征,包括:
7、通过麦克风阵列采集说话人的音频信号,采用短时傅里叶变换stft对说话人的非平稳语音信号进行分析,获得原始的频谱信息。
8、可选地,采用短时傅里叶变换对说话人的非平稳语音信号进行分析,包括:
9、对于麦克风阵列的第i个通道接收到的信号xi(n),在时间帧索引n处的频带k的离散stft定义如下述公式(1)所示:
10、
11、其中,f是频率箱数,s是帧移,w(m)是选择的窗口函数。
12、可选地,s1中,提取说话人的视觉特征,包括:
13、使用外参和内参相机标定参数以及声源的三维位置pl,合成人脸边界框bl=(ul,vl,wl,hl);其中ul是左上角的水平位置,vl是左上角的垂直位置,wl是宽度,hl是高度;
14、通过边界框bl,定义如下述公式(2)公式(3)的多变量概率分布函数:
15、
16、
17、其中,x=(u,v)是说话人的人脸图像位置,l是视场角(fov)内的目标数量,u(·)表示均匀分布,f(x|μ,σ)是具有均值μ+σ/2和标准差σ的类似高斯的概率分布函数;
18、将视觉特征被编码为所有u和v的和的串联,获得距离感知视觉特征编码。
19、可选地,基于swavf和avs3d的dl网络,包括:
20、通过两个卷积层沿频率和时间轴提取从降采样输入得到的低级特征;通过两个残差块进行全局特征提取;
21、在dl网络中引入每个坐标的单独分支,每个分支分别通过一个残差块提取高级特征;一个将特征投影到目标空间的层,以及沿着目标轴卷积的层并输出一个空间谱;
22、基于swavf晚期融合方法对获得的单模态输出进行融合;
23、通过三个平行的多层感知器以及带有sigmoid输出层,说话人的方位、仰角以及距离进行预测并输出。
24、可选地,基于swavf晚期融合方法对获得的单模态输出进行融合,包括:
25、基于视觉模态,通过三个小的子网络产生空间权重;
26、将空间权重与音频网络的输出进行哈达玛积运算;
27、对基于概率的预测输出的峰值位置进行调整。
28、可选地,s3中,基于音频特征和视觉特征的提取结果,训练dl网络,包括:
29、获取训练目标,训练目标包括:从音频特征和视觉特征中识别出投影faz、fel和fd,以及与地面真实的基于概率的编码yaz、yel和yd;
30、训练一个epoch以获得窄带3d位置预测,基于如下述公式(4)的均方误差mse损失函数,对dl网络进行第一阶段训练;
31、
32、其中,和分别表示第一阶段在时间t和频率f下的输出;α、β和γ是根据经验设置的权重,用于调整每个损失项的相对贡献;
33、基于如下述公式(5)的损失函数,对dl网络进行第二阶段训练:
34、
35、另一方面,提供了一种结合音频视频信号的3d空间声源定位装置,该装置应用于结合音频视频信号的3d空间声源定位方法,该装置包括:
36、特征提取模块,用于提取说话人的音频特征;提取说话人的视觉特征;
37、dl网络构建模块,用于构建基于swavf和avs3d的dl网络;
38、定位模块,用于基于音频特征和视觉特征的提取结果,训练dl网络;输入待检测数据至训练后的dl网络,完成结合音频视频信号的3d空间声源定位。
39、另一方面,提供一种结合音频视频信号的3d空间声源定位,所述结合音频视频信号的3d空间声源定位包括:处理器;存储器,所述存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,实现如上述结合音频视频信号的3d空间声源定位方法中的任一项方法。
40、另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现上述结合音频视频信号的3d空间声源定位方法中的任一项方法。
41、本发明实施例提供的技术方案带来的有益效果至少包括:
42、本发明提供的方法创新性地引入了视-听结合机制,利用视觉特征补充音频特征,大幅增强了在复杂声场环境下的定位准确性。其次,利用短时傅里叶变换(stft)对音频信号实施高效的预处理,确保对音频的时频域特性有精确的捕捉。本发明还使用了独特的编码策略,有助于模型更好的估计目标半径。其次,为了实现视频-音频并行,本发明特别提出了空间加权的音频-视觉融合机制——swavf机制,即使视觉信息相对较弱,它也能增强音频网络的预测准确性,而不会被音频的“强大”异常值所主导。
本文地址:https://www.jishuxx.com/zhuanli/20241009/305972.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表