一种基于质谱检测的稳定性监测方法及系统与流程
- 国知局
- 2024-10-09 15:39:42
本发明涉及质谱稳定性监测,尤其涉及一种基于质谱检测的稳定性监测方法及系统。
背景技术:
1、质谱检测技术作为一种强有力的分析工具,被广泛应用于各种科学研究和工业生产中。它通过测量离子化样品的质量-电荷比来鉴定和定量分析化合物。质谱检测具有高灵敏度、高分辨率和高通量的特点,能够提供丰富的结构和定量信息。尽管质谱技术已经相对成熟,但在实际应用中,数据的复杂性和多样性依然是一个重大挑战。质谱数据不仅包含了样品的丰富信息,还常常伴随着噪声、漂移和其他不确定因素,这些因素对数据分析的准确性和稳定性提出了更高的要求。因此如何有效地处理和分析这些数据,特别是监测数据的稳定性,成为了在一个重要的研究课题。
2、现有的基于质谱检测的稳定性监测方法及系统无法根据质谱数据的不同特点自动调整算法参数,降低模型在不同质谱数据集上的通用性和适应性,模型在捕捉数据依赖性关系时的稳定性和可靠性差;此外,现有的基于质谱检测的稳定性监测方法及系统无法在多个层次上识别异常数据点,降低异常检测的准确性和鲁棒性,且不适用于高通量质谱检测环境;为此,我们提出一种基于质谱检测的稳定性监测方法及系统。
技术实现思路
1、本发明的目的是为了解决现有技术中存在的缺陷,而提出的一种基于质谱检测的稳定性监测方法及系统。
2、为了实现上述目的,本发明采用了如下技术方案:
3、一种基于质谱检测的稳定性监测方法,该监测方法具体步骤如下:
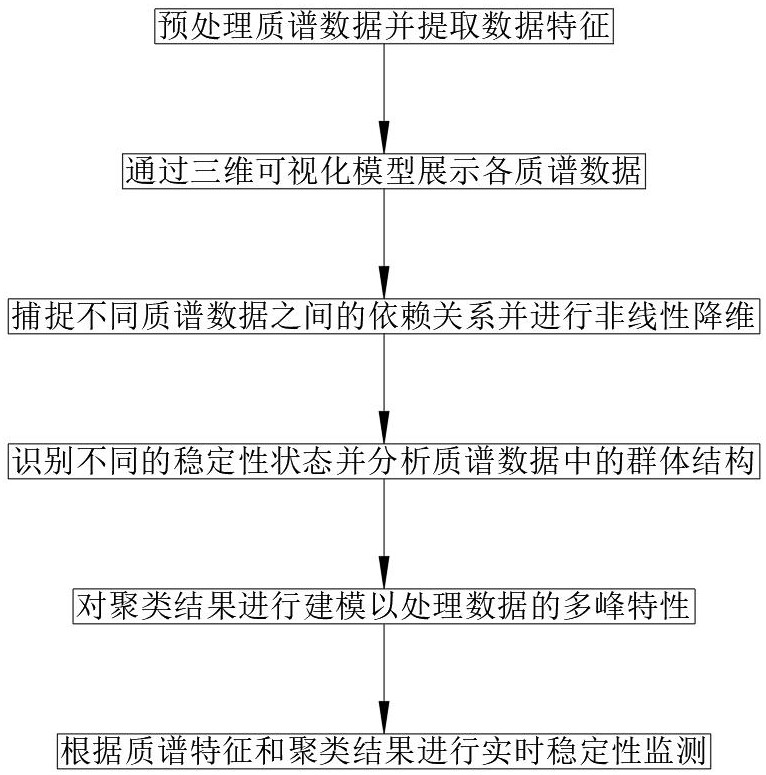
4、p1、预处理质谱数据并提取数据特征。
5、作为本发明的进一步方案,p1所述提取数据特征具体步骤如下:
6、步骤一:获取质谱数据,并构建质谱图像,其中质谱图像的横轴为质荷比,纵轴为信号强度,再采用高斯滤波器对质谱数据进行平滑处理,去除噪声,并使用多项式拟合对基线进行校正;
7、步骤二:构建n×n的窗口,并将窗口初始位置放置于质谱图像的左上角,即坐标处,之后依据需求对窗口进行横向逐点滑动或纵向逐点滑动,直至滑动至质朴图像结束;
8、步骤三:每次滑动窗口时,收集窗口中心数据点坐标以及其余邻域数据点坐标,并计算窗口中心数据点与窗口中其余点的差值,之后根据计算得到的差值,进行二值化处理,若中心点的值大于或等于邻域点,则差值为1,否则为0;
9、步骤四:将所有邻域点的二值化结果按顺时针或逆时针顺序组合成一个二进制数,以获取每个质谱数据点的lbp特征值,之后统计图像中所有lbp模式的出现频率,构建lbp直方图作为纹理特征向量,再将提取的lbp特征构建成数据矩阵,其中每行代表一个质谱样本,每列代表一个特征;
10、步骤五:提取每组实验样本质谱图像中的特征峰及其强度值,将每个样本的特征强度值排列成一行,形成响应矩阵的一行,再将所有样本的特征排列组合在一起,形成完整的响应矩阵,之后计算特征矩阵和响应矩阵的协方差矩阵;
11、步骤六:通过奇异值分解获取协方差矩阵的特征向量,并将其作为权重向量,再将原始数据投影到新的潜变量空间,以获取降维后的特征矩阵,并将降维后的特征矩阵作为此次质谱数据的数据特征。
12、作为本发明的进一步方案,步骤四所述lbp特征值具体计算公式如下:
13、;
14、式中,代表在坐标处的中心像素的lbp值;代表当前n×n窗口的中心点坐标;代表当前窗口的大小;代表二值化函数;代表点处的信号强度;代表当前n×n窗口中第个领域点坐标;代表二进制数的权重,其中是邻域点的编号。
15、p2、通过三维可视化模型展示各质谱数据;
16、p3、捕捉不同质谱数据之间的依赖关系并进行非线性降维。
17、作为本发明的进一步方案,p3所述捕捉不同质谱数据之间的依赖关系具体步骤如下:
18、步骤1:通过文献调研、专家咨询以及历史实验结果收集质谱检测领域知识,计算各特征之间的相关系数,并识别可能的依赖关系,再使用卡方检验方法测试特征之间的条件独立性,对特征进行聚类,获取各组特征之间的潜在关系,之后使用格兰杰因果关系检验方法识别潜在的因果关系;
19、步骤2:将每个从质谱数据中提取的数据特征作为一个节点,根据专家意见和文献调研的结果,初步连接一些显著依赖的特征,再依据相关系数和条件独立性测试的结果,建立初始边连接,检查初始概率模型结构的合理性,根据数据统计结果和专家意见,修正初始概率模型结构;
20、步骤3:计算当前模型结构的bic值,即模型结构评分值,在当前模型结构中,选择一对没有直接连接的节点作为候选边,在和之间添加一条有向边或,计算新结构的bic值,并与当前结构的bic值进行比较;
21、步骤4:在当前模型结构中,选择一条现有的有向边作为候选边,并模拟删除该有向边,再计算新结构的bic值,并与当前结构的bic值进行比较,在当前模型结构中,选择一条现有的有向边作为候选边,反转该有向边,计算新结构的bic值,并与当前结构的bic值进行比较;
22、步骤5:比较添加边、删除边以及反转边操作的评分变化,选择能够最大化降低bic值的操作,再根据最优操作更新模型结构,依据概率模型中的节点数量和边数量初始化组个体,并随机初始化每组个体位置,其中位置表示模型结构,用一个二进制矩阵表示各网络结构,矩阵元素表示边的存在与否;
23、步骤6:对于每组个体,计算其对应模型结构的bic值作为亮度,其中模型bic值越小,该个体亮度值越高,比较各个体亮度值,再计算各组个体之间的距离,并将依据个体向更亮的个体移动的更新规则,调整各组个体位置,重复计算各组个体亮度值,并更新个体位置信息,直至达到预设最大迭代次数,对更新后的位置对应的模型结构进行随机扰动后,获取最终概率模型结构;
24、步骤7:在最终概率模型通过条件独立性测试来确认特征之间的依赖关系,之后通过马尔科夫链蒙特卡洛方法对各数据特征进行概率推理,并计算某些特征的后验概率以进行预测或分类,对捕捉到的特征依赖关系进行解释,以获取特征之间的相互作用信息。
25、作为本发明的进一步方案,步骤3所述bic值具体计算公式如下:
26、;
27、式中,代表模型结构评分值;代表观测数据集,包含所有质谱数据样本;代表概率模型的参数集;代表节点之间的有向边关系;代表数据在参数和结构下的似然;代表参数的数量;代表数据集中样本的数量;
28、步骤6中所述个体位置更新具体计算公式如下:
29、;
30、;
31、;
32、式中,代表个体和个体之间的距离;代表邻接矩阵的维度;代表质谱数据的第个维度;代表个体对应的邻接矩阵的第个元素;代表个体对应的邻接矩阵的第个元素;代表个体对个体的吸引度;代表最大吸引度常数;代表光强吸收系数,用于决定吸引度随距离的衰减速度;代表自然对数的底数;代表更新后的模型结构;代表个体当前的模型结构;代表个体当前的模型结构。
33、p4、识别不同的稳定性状态并分析质谱数据中的群体结构;
34、p5、对聚类结果进行建模以处理数据的多峰特性;
35、p6、根据质谱特征和聚类结果进行实时稳定性监测。
36、一种基于质谱检测的稳定性监测系统,包括采集预处理模块、提取降维模块、依赖捕捉模块、结构优化模块、异常识别模块、报告生成模块、捕捉检测模块、自适应调整模块以及可视化模块;
37、所述采集处理模块用于从质谱仪中采集原始质谱数据并进行清洗和标准化;
38、所述提取降维模块用于提取质谱数据的纹理特征,捕捉质谱图中的局部模式,并对提取的特征进行降维,减少冗余信息;
39、所述依赖捕捉模块用于构建质谱数据的概率模型,捕捉不同特征之间的依赖关系;
40、所述结构优化模块用于优化概率模型结构,并对优化后的模型结构进行评价;
41、所述异常识别模块用于检测质谱数据中的异常点,识别潜在的质量问题。
42、作为本发明的进一步方案,所述异常识别模块识别潜在的质量问题具体步骤如下:
43、步骤ⅰ:获取预处理后的质谱数据集,其中表示第个质谱数据点,包含多个特征,之后选择多个初始聚类中心,再计算每个数据点到聚类中心的距离,并将各组质谱数据分配到最近的聚类中心,并更新每个聚类的中心为该聚类中所有点的平均值;
44、步骤ⅱ:重复寻找聚类中心,并分配质谱数据点,直到聚类中心收敛到预设阈值内,根据聚类结果,识别不属于任何主要聚类的点或处于聚类边缘的点,并将其标记为异常点;
45、步骤ⅲ:计算并记录未标记质谱数据点与异常数据点之间的相似度,以构建标准拉普拉斯矩阵,再对拉普拉斯矩阵进行特征值分解,得到多组最小特征值对应的特征向量,构成特征矩阵,之后设置各数据点邻域半径,以及质谱数据点成为核心点所需的最小邻居数;
46、步骤ⅳ:计算特征矩阵中每对数据点之间的距离,同时计算每个数据点邻域半径内的邻居数,若邻居数不小于,则该点为核心点,从一个核心点开始,将所有在邻域半径内的点加入到当前聚类中,若新加入的点也是核心点,则继续扩展,重复选择核心点并创建新聚类,直至没有新的点可加入;
47、步骤ⅴ:检测聚类完成后的各组质谱数据点,若一个点既不是核心点,也不是任何核心点的邻居,则该点被标记为异常点,再通过构建的概率模型计算其余每个节点的条件概率表,以及各数据点在概率模型中的联合概率以及异常概率,若异常概率高于异常阈值时,识别该点为异常点;
48、步骤ⅵ:对检测出的各组异常点进行解释说明,再通过报告生成模块依据用户需求通过图表的形式对各组质谱数据的检测结果,进行可视化展示,并通过短信、邮箱以及报警的方式告知用户存在稳定性异常。
49、所述聚类分析模块用于对质谱数据进行检测分析,识别数据中的潜在模式和结构;
50、所述报告生成模块用于自动生成质谱检测结果报告,提供详细的分析结果和建议;
51、所述捕捉检测模块用于识别捕捉质谱数据中的社团结构以及多峰特性。
52、作为本发明的进一步方案,所述捕捉检测模块识别捕捉质谱数据中的社团结构以及多峰特性具体步骤如下:
53、第一步:捕捉检测模块初始化一组空的网络图,将质谱数据点表示为网络图中的节点,并根据数据点之间的相似度或距离,构建节点之间的边,计算所有节点对之间通过边的最短路径数,即边介数,并移除边介数最大的边;
54、第二步:移除完成后,重新计算网络图各边的边介数,并移除边介数最大的边,重复计算各边的边介数,以及移除最大边介数,直至网络图分裂为多个社团,计算每个社团的内部特征;
55、第三步:构建高斯混合模型,定义多个高斯成分,每个成分表示一个高斯分布,再使用期望最大化算法计算数据点属于每个高斯成分的后验概率,并根据后验概率更新高斯混合模型参数;
56、第四步:通过更新后的高斯混合模型计算每个质谱数据点的概率分布,再分析高斯混合模型中每个高斯成分,识别质谱数据的多峰特性,再根据每个高斯成分的均值和协方差,确定质谱数据的不同峰值位置和分布形态。
57、所述自适应调整模块用于动态调整模型参数,并实时更新检测算法;
58、所述可视化模块用于构建虚拟现实场景,展示质谱图。
59、相比于现有技术,本发明的有益效果在于:
60、1、该基于质谱检测的稳定性监测方法通过文献调研、专家咨询以及历史实验结果收集质谱检测领域知识,计算各特征之间的相关系数,并识别可能的依赖关系,再使用卡方检验方法测试特征之间的条件独立性,对特征进行聚类,获取各组特征之间的潜在关系,之后使用格兰杰因果关系检验方法识别潜在的因果关系,将每个从质谱数据中提取的数据特征作为一个节点,初步连接一些显著依赖的特征,再依据相关系数和条件独立性测试的结果,建立初始边连接,检查初始概率模型结构的合理性,根据数据统计结果和专家意见,修正初始概率模型结构,计算当前模型结构的bic值,即模型结构评分值,在当前模型结构中,随机添加一条有向边,计算新结构的bic值,并与当前结构的bic值进行比较,在当前模型结构中,进行添加边、删除边以及反转边操作,并比较各操作的评分变化,选择能够最大化降低bic值的操作,再根据最优操作更新模型结构,依据概率模型中的节点数量和边数量初始化多组个体,并随机初始化每组个体位置,其中位置表示模型结构,用一个二进制矩阵表示各网络结构,矩阵元素表示边的存在与否,对于每组个体,计算其对应模型结构的bic值作为亮度,其中模型bic值越小,该个体亮度值越高,比较各个体亮度值,调整各组个体位置,重复计算各组个体亮度值,并更新个体位置信息,直至达到预设最大迭代次数,对更新后的位置对应的模型结构进行随机扰动后,获取最终概率模型结构,在最终概率模型通过条件独立性测试来确认特征之间的依赖关系,之后通过马尔科夫链蒙特卡洛方法对各数据特征进行概率推理,并计算某些特征的后验概率以进行预测或分类,对捕捉到的特征依赖关系进行解释,以获取特征之间的相互作用信息,能够根据质谱数据的不同特点自动调整算法参数,提高了模型在不同质谱数据集上的通用性和适应性,能够更好地捕捉质谱数据中的变化和趋势,增强模型在捕捉数据依赖性关系时的稳定性和可靠性。
61、2、该基于质谱检测的稳定性监测系统获取预处理后的质谱数据集,之后选择多个初始聚类中心,再计算每个数据点到聚类中心的距离,并将各组质谱数据分配到最近的聚类中心,并更新每个聚类的中心为该聚类中所有点的平均值,重复寻找聚类中心,并分配质谱数据点,直到聚类中心收敛到预设阈值内,识别不属于任何主要聚类的点或处于聚类边缘的点,并将其标记为异常点,计算各数据点之间的相似度,以构建标准拉普拉斯矩阵,再对拉普拉斯矩阵进行特征值分解,得到多组最小特征值对应的特征向量,构成特征矩阵,之后设置各数据点邻域半径,以及质谱数据点成为核心点所需的最小邻居数,找寻特征矩阵中各核心点,从一个核心点开始,将所有在邻域半径内的点加入到当前聚类中,若新加入的点也是核心点,则继续扩展,重复选择核心点并创建新聚类,直至没有新的点可加入,检测聚类完成后的各组质谱数据点,若一个点既不是核心点,也不是任何核心点的邻居,则该点被标记为异常点,再通过构建的概率模型计算其余每个节点的条件概率表,以及各数据点在概率模型中的联合概率以及异常概率,若异常概率高于异常阈值时,识别该点为异常点,对检测出的各组异常点进行解释说明,再通过报告生成模块依据用户需求通过图表的形式对各组质谱数据的检测结果,进行可视化展示,并通过短信、邮箱以及报警的方式告知用户存在稳定性异常,能够在多个层次上识别异常数据点,提供更精确的异常检测,提升异常检测的准确性和鲁棒性,能够高效地处理大量质谱数据,适用于高通量质谱检测环境。。
本文地址:https://www.jishuxx.com/zhuanli/20241009/309515.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表