一种基于Catboost保客增换购概率预测的方法与流程
- 国知局
- 2024-10-15 09:22:02
本发明涉及数据处理,更具体地说,涉及一种基于catboost保客增换购概率预测的方法。
背景技术:
1、由于中国车市进入新的发展时期,汽车市场中换购和增购需求将成为车市发展的主要推动力。汽车企业与汽车经销商在进行新车销售业务时面临如何从保有客户中挖掘购车价值线索的问题。如何高效的在保有客户中挖掘有潜在增换购意向的客户是当前汽车企业和经销商亟待解决的问题。
技术实现思路
1、本发明要解决的技术问题在于,针对上述技术方案存在的不足,提供一种能有效挖掘增换购客户的基于catboost保客增换购概率预测的方法。
2、本发明提供一种基于catboost保客增换购概率预测的方法,所述方法包括以下步骤:
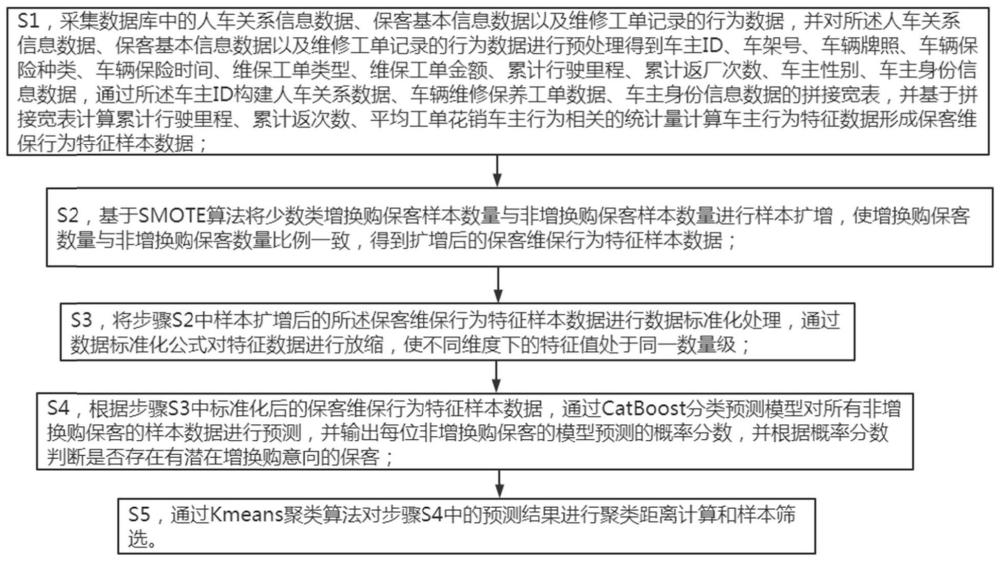
3、s1,采集数据库中的人车关系信息数据、保客基本信息数据以及维修工单记录的行为数据,并对所述人车关系信息数据、保客基本信息数据以及维修工单记录的行为数据进行预处理得到车主id、车架号、车辆牌照、车辆保险种类、车辆保险时间、维保工单类型、维保工单金额、累计行驶里程、累计返厂次数、车主性别、车主身份信息数据,通过所述车主id构建人车关系数据、车辆维修保养工单数据、车主身份信息数据的拼接宽表,并基于拼接宽表计算累计行驶里程、累计返次数、平均工单花销车主行为相关的统计量计算车主行为特征数据形成保客维保行为特征样本数据;
4、s2,基于smote算法将少数类增换购保客样本数量与非增换购保客样本数量进行样本扩增,使增换购保客数量与非增换购保客数量比例一致,得到扩增后的保客维保行为特征样本数据;
5、s3,将步骤s2中样本扩增后的所述保客维保行为特征样本数据进行数据标准化处理,通过数据标准化公式对特征数据进行放缩,使不同维度下的特征值处于同一数量级;
6、s4,根据步骤s3中标准化后的保客维保行为特征样本数据,通过catboost分类预测模型对所有非增换购保客的样本数据进行预测,并输出每位非增换购保客的模型预测的概率分数,并根据概率分数判断是否存在有潜在增换购意向的保客;
7、s5,通过kmeans聚类算法对步骤s4中的预测结果进行聚类距离计算和样本筛选。
8、本发明所述的基于catboost保客增换购概率预测的方法中;在所述步骤s1中预处理包括以下步骤:
9、s11,当人车关系信息数据、保客基本信息数据以及维修工单记录的行为数据为离散数据特征时衡量车主的维保时间节点是否存在上一次维保回厂记录,若存在上一次维保回厂记录则按上一次维保记录的值填充,若不存在则置为空2,当人车关系信息数据、保客基本信息数据以及维修工单记录的行为数据为连续数据特征时,按照保客车主维保行为数据分布,将超出均值上下三倍标准差的数据置为空,当某条车主数据如果返厂维修保养的记录为空或车龄不足一年,则直接删除该条数据;目的是处理异常值。
10、s12,将没有返厂维保记录的保客车主的缺失数据予以删除,将有一条及以上返厂维保记录的保客车主的缺失数据使用前一年回厂维保记录的均值进行填充;目的是对确实的数据进行填充。
11、s13,当每个增换购的保客车主对应多个车辆vin时,去除新购车vin对应的维保记录,保留增换购之前的车辆vin的维保行为及车辆信息数据。目的是去掉重复的数据。
12、本发明所述的基于catboost保客增换购概率预测的方法中;在所述步骤s2中,通过所述smote算法计算保客维保行为特征样本数据的采样倍率n,其中所述采样倍率n计算公式如下:
13、n=β*(ml-ms)
14、其中,ml为多数类增换购保客样本数量,ms为少数类增换购保客样本数量,β∈[0,1]随机数,若β等于1,则采样后正负比例为1:1;
15、然后,从少数类增换购保客样本中选取一个样本xi,按采样倍率n,从xi的k近邻中随机选择n个样本xzi,最后,依次在xzi和xi之间随机合成新样本,新样本的合成公式如下:
16、xn=xi+β*(-xi)
17、xn为合成增换购保客样本,xi是少数类增换购保客样本中第i个样本,xzi是xi的k近邻中随机选取一个少数类增换购保客样本β∈[0,1]的随机数。
18、本发明所述的基于catboost保客增换购概率预测的方法中;在所述步骤s3中所述标准化公式如下:
19、
20、其中,xi表示当前保客维保行为特征的数值;μ表示当前所有保客维保行为特征数据的均值;xmax表示当前所有保客维保行为特征数据的最大值;xmin表示当前所有保客维保行为特征数据的最小值。
21、本发明所述的基于catboost保客增换购概率预测的方法中;所述步骤s5包括以下步骤:
22、s51,将所有已有的增换购保客数据点聚类形成一个簇,并计算该簇的质心,然后计算簇中每个数据点距离质心的距离,并求得平均距离,其中,所述平均距离计算公式如下:
23、
24、其中,avg_distancex表示增换购保客簇中每个数据点到质心的平均聚类距离;x表示质心的数据点;xi表示簇中某个增换购保客的数据点。
25、本发明所述的基于catboost保客增换购概率预测的方法中;所述步骤s5还包括以下步骤:
26、s52,将每个非增换购保客特征数据点看作一个坐标,对质心与数据集中的每个非增换购保客数据点之间计算欧式聚类距离,所述欧式聚类距离计算公式如下:
27、
28、其中d(x,xi)表示某个非增换购客户到质心的聚类距离;x表示质心的数据点;xi表示某个非增换购保客的数据点。
29、本发明所述的基于catboost保客增换购概率预测的方法中;所述步骤s5还包括以下步骤:
30、s53,通过比较非增换购保客到质心的距离与平均距离,将大于平均距离的非增换购保客去除,保留小于平均距离的非增换购保客,所述非增换购保客去除公式如下:
31、if(distcex>avg_distcex)then(drop)else(keep)其中,distancex表示当前非增换购保客数据点距离质心的聚类距离;avg_distancex表示步骤s51中计算出的平均聚类距离;keep和drop分别表示当前预测潜在意向增换购保客保留和去除。
32、本发明所述的基于catboost保客增换购概率预测的方法中;在所述步骤s1中所述人车关系信息数据包括车主id、车架号、车型编码、车系编码、车辆保险时间、车辆颜色、人车关系创建时间。
33、本发明所述的基于catboost保客增换购概率预测的方法中;在所述步骤s1中所述维修工单记录的行为数据包括维修工单id、返厂类型、维修工单类型、特约店编码、车架号、工单金额、维修时间、累计行驶里程。
34、本发明所述的基于catboost保客增换购概率预测的方法中;在所述步骤s1中所述车主基本信息数据包括车主身份id、车主性别、车主手机号、是否绑定微信公众号。
35、本发明的基于catboost保客增换购概率预测的方法针对车企识别保有车主增换购意愿难的问题,为车企提供一种通过对保有车主维修保养行为数据进行挖掘,预测车主增换购概率。能够有效发现潜在的高意向增换购保客车主,同时也为企业节约企业营销成本。
本文地址:https://www.jishuxx.com/zhuanli/20241015/313917.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表