一种基于成分组装的文本测试用例生成方法
- 国知局
- 2024-10-15 09:32:38
本发明涉及一种基于成分组装的文本测试用例生成方法,属于软件测试与程序分析。
背景技术:
1、当前,评估自然语言处理(natural language process,nlp)应用性能的标准范式是使用标注良好的基准集中划分好的验证集和测试集,将他们喂入待测对象,并基于输出结果计算出准确率(accuracy),精确率(precision),召回率(recall),f1分数(f1-score)等指标。研究人员已经为各类nlp应用建立了各种基准集,如squad,glue和nist mt。我们可以从一些基准集官方网站显示的排行榜中获取到一些nlp任务的最新发展情况。然而,基准集中的验证集或是测试集并不全面,并且有着和训练集相同的数据分布和偏差。它们包含的数据很有可能无法触发错误行为以发现nlp应用中潜在的问题。因此,标准评估范式的评估结果并不能充分地反映出nlp应用在面对真实应用场景中不可预知的输入时的真实性能。此外,检查输出和参考文本之间的一致性是评估nlp应用能力的一种非常单一的方式。一致性和代表性能的统计指标只反映了被测对象的整体性能,从中无法找出缺陷的具体特征并针对性地提出改进措施。有时,研究人员会采用一些技巧来提高nlp应用的性能,而检查一致性并不能分辨出正确的输出是否与这些技巧有关。例如,机器阅读理解模型可以通过模式记忆或关键词轻松“猜”出正确答案,一致性检查不能判断该模型是否真正理解文本并推断出答案。因此,我们提出了一种可以缓解基准和测试能力的限制且适用于多种nlp任务的测试用例生成方法,它可以提供具有多样化句型和含义的有效测试用例,以模拟和覆盖真实世界的输入,并评估各种nlp应用的能力,如语义理解、词语辨别等。
2、为了更好地促进nlp应用的发展,研究人员已经开始关注可用于各种nlp应用的测试方法。然而,nlp应用中的核心模块,深度神经网络模型,使测试变得非常具有挑战性。传统测试方法的设计是基于软件开发人员手动构建的内部逻辑。因此,传统的测试方法不能很好地适配于内部逻辑是由数百万个参数构建,编程范式是由数据驱动的深度神经网络。此外,为nlp应用构建严格的测试预言,即给定输入的预期输出,是非常困难的。对于自然语言生成(natural language generation,nlg)任务,如机器翻译,输出空间庞大导致手动构建和检查严格的预言信息异常复杂困难。目前,nlg任务的评估方法采用了一些指标(bleu,rouge等)来计算输出和参考文本(正确输出空间的一个子集)之间的差异,以估算出输出的质量。然而,研究表明这些指标和人类评价之间并没有明显的相关性。
3、到目前为止,研究人员已经提出了一些不依赖于基准集的面向nlp应用的测试方法。he等人提出了一种针对机器翻译软件的结构不变性测试方法。该方法通过检查软件的输出是否满足结构不变性来捕获翻译错误。chen等人提出了一种针对机器阅读理解模型的蜕变测试方法,包括七种专门为机器阅读理解任务设计的蜕变关系(例如,基于反义形容词的转换,基于时态变化的转换等)。然而,这些测试方法只可用于单个nlp任务,在设计蜕变关系时仅考虑了单个nlp任务的输入输出特征,因此不具备通用性。checklis是一个面向多类型nlp应用的行为测试工具,它包含了常用的测试用例生成方法,并可以验证nlp应用是否具备一些常规能力。但与自动化测试工具不同,checklist需要用户参与到测试用例的生成过程中以确保测试用例的可用性。
技术实现思路
1、本发明的目的在于,克服现有技术存在的技术缺陷,提出一种基于成分组装的文本测试用例生成方法,有效解决目前存在自然语言处理应用缺乏测试数据、测试预言构建困难等难题,帮助测试人员高效地构建测试用例集,进而帮助测试人员捕获被测对象的错误行为,提升测试效率。
2、本发明具体采用如下技术方案:一种基于成分组装的文本测试用例生成方法,包括如下步骤:
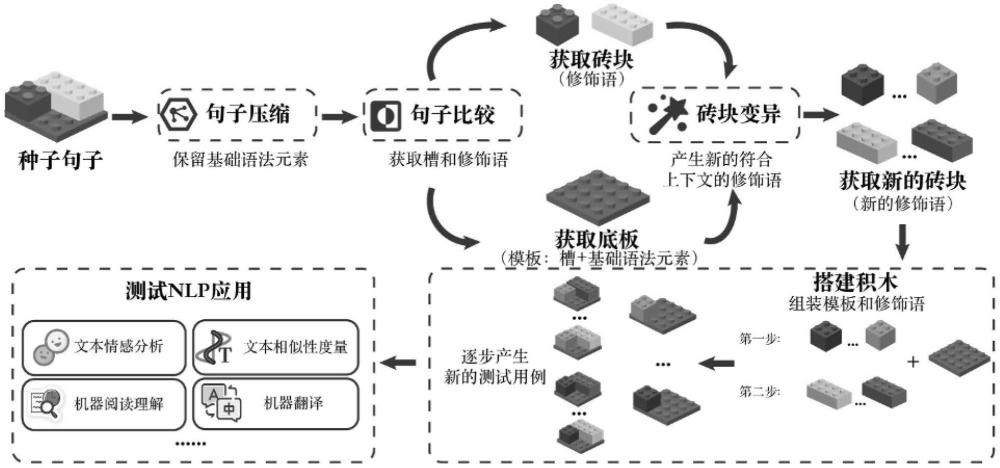
3、步骤ss1:句子拆解步骤,包括:通过确定原句中的修饰语并将它们从原句中删除来获得压缩结果,然后,通过比较压缩结果和原始句子,得到可以插入修饰语的槽,以创建句子派生模板;
4、步骤ss2:句子派生步骤,包括:根据句子派生模板和修饰语集合来派生出新的句子,应用变异算子产生符合语境的新修饰语;
5、步骤ss3:构建蜕变关系步骤,包括:根据被测nlp任务的输入格式和预先设计的蜕变关系生成一个新的测试集,然后将所述新的测试集输入到被测对象中,以检测错误行为。
6、作为一种较佳的实施例,所述句子拆解步骤具体包括:通过句子拆解得到的句子派生模板定义为底板,把移除的修饰语定义为砖块,给定一个种子句子s,将上述句子拆解的过程表述如下:
7、
8、其中,d(s)表示句子拆解操作,p0表示种子句子s的句子派生模板,包含基本语法元素和插入修饰语的槽,表示被移除的修饰语的集合,bi表示被d从左到右移除的第i个修饰语。
9、作为一种较佳的实施例,所述句子派生步骤具体包括:根据句子派生模板p0和大小为n的修饰语集合来派生出新的句子,如果将第i个修饰语bi依次按序插入模板p0的第i个槽di并保存,就可以生成n+1个句子;应用变异算子σ(b)来产生符合语境的新修饰语,变异后的修饰语与模板组合在一起,生成更多新的句子,给定压缩结果s0和派生模板p0,获得初始集合s0={s0}和派生链
10、作为一种较佳的实施例,所述句子派生步骤具体还包括:采用派生树来展示新生成的句子之间的派送关系,其中,根节点是种子句子的压缩结果s0,它是派生的起点,第i层的每个句子都比其第i-1层的父节点多插入一个bi的变异体,叶子节点是所有槽都被填满的句子,得到的新句子集是每个组装步骤的输出的并集;直观地说,从根节点s0到叶子节点的路径tpj上的每个节点都表示新生成的句子,并且具有派生关系,给定句子派生模板p0和附属集b,上述过程表述如下:
11、
12、其中,sent lego表示新生成句子的集合,τ表示使用派生模板p0和修饰语集合的派生方法,si表示第i个组装步骤的输出。
13、作为一种较佳的实施例,所述构建蜕变关系步骤具体包括:根据被测nlp任务的输入格式和预先设计的蜕变关系可基于sent lego生成一个新的测试集test lego,然后将testlego输入到被测对象中,以检测错误行为;所述nlp任务包括机器阅读理解应用、情感分析应用和语义相似性度量应用。
14、作为一种较佳的实施例,所述构建蜕变关系步骤具体还包括:对于机器阅读理解应用,通过验证机器阅读理解应用输出的语义不变性关系来检测它是否存在错误的行为;给定一个段落p,一个与该段落p相关的问题q,语义不变性关系表示如下:
15、
16、其中,p′表示语义与p相同的新段落,mmrc表示被测的机器阅读理解的应用,它的输出是它所预测的问题q的答案,表示语义不变性关系;语义不变性是指在阅读具有相同语义的段落去回答同一问题时,预测答案的语义不应该发生改变。
17、作为一种较佳的实施例,所述构建蜕变关系步骤具体还包括:对于情感分析应用,设置一个定向期望,以解决新测试用例缺乏测试预言的问题,定向期望是指期望情绪的变化符合某些预期,如果增加了一个积极/消极的文本成分,该句子的情绪应该变得更加积极/消极;在进行测试时,将情感分析应用的概率变化视为情感的变化,给定一个句子s和一个文本成分c,定向期望关系表示为:
18、
19、其中,msa表示情感分析应用,其输出是输入c或者s+c的情感标签,表示输入为s+c时情感标签所对应的概率,↑表示概率的增加。
20、作为一种较佳的实施例,所述构建蜕变关系步骤具体还包括:对于文本语义相似性度量,通过验证一对具有语义差异的句子的相似性标签是否是不同来捕获应用的错误行为;具有派生关系的两个句子就存在语义差异,给定两个具有派生关系的句子s和句子s′,语义差异关系表示如下:
21、sems≠sems′→mssm(s,s′)=0
22、其中,sems表示句子s的语义,sems′表示句子s′的语义,mssm表示文本相似性度量应用,它的输出是0或者是1;0表示句子s和句子s′的语义不同,1表示句子s和句子s′的语义相同。
23、本发明所达到的有益效果:本发明提出一种一种适配于多种nlp任务的基于成分组装的测试用例生成方法,该方法可以有效缓解基准集和nlp应用被评估能力的限制。该方法基于单个种子测试用例,生成涵盖多样化句式和句义的新测试用例,以模拟和更大范围地覆盖真实世界的输入,并评估nlp应用的各项能力,如语义理解、词语辨别能力等。本发明在四个常用的nlp任务上进行了实验,选择了四个先进的nlp模型和三个商业软件作为测试对象,以对该方法进行全面的性能评估。结果表明,该方法可以有效地生成多个nlp任务的测试用例和检测出nlp应用的错误行为,帮助测试人员评估出自然语言处理应用在真实应用场景中的性能,提高软件测试、软件迭代研发的测试效率。
本文地址:https://www.jishuxx.com/zhuanli/20241015/314510.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。