一种面向非侵入式语音质量评估的后门防御方法
- 国知局
- 2024-10-15 09:37:57
本发明涉及多媒体信息安全领域,尤其是涉及一种面向非侵入式语音质量评估的后门防御方法。
背景技术:
1、在过去十年期间,深度学习技术凭借其卓越的数据特征学习能力,极大地推动了多媒体信息技术的快速发展。然而,新技术的引入往往伴随着新的安全挑战。随着投毒攻击、后门攻击和对抗攻击的提出,深度学习模型的脆弱性和不稳定性也逐渐显露出来。其中,后门攻击具有较高的攻击成功率和隐蔽性,代表了对深度学习模型最为严重的一类威胁。
2、数据投毒是实施后门攻击最常用且实际的手段之一,基于数据投毒技术的后门攻击的攻击者选择数据集中一定比例的样本添加触发器后作为中毒样本,并将这些中毒样本的标签篡改为一个固定的标签。当深度学习模型基于这样一个数据集训练后便被植入了后门,将会在任意一个含有触发器的样本(即中毒样本)上预测出目标标签,同时还能够在干净样本上维持原有的优秀性能。基于数据投毒技术的后门攻击的特点是只需对数据集本身进行修改,而不需要涉及深度学习模型的结构和训练算法的其他详细信息。因此,基于数据投毒技术的后门攻击被广泛使用。
3、随着大数据时代的到来,数据成为了驱动人工智能和机器学习的关键因素。然而数据集的制作是十分耗时耗力的,因此研究者们往往采用网上的公开数据集进行训练,从而降低成本。然而,这却为基于数据投毒技术的后门攻击的实现提供了机会。不可信的第三方向数据集中p%的样本加入触发器作为中毒样本,并将这些中毒样本的标签修改为预先设定的一个标签yt(即目标标签)。这些中毒样本构成的数据集被称为中毒子集而数据集中剩余的干净样本构成的数据集则被称为干净子集和共同组成新的中毒数据集当研究者使用不可信的第三方提供的中毒数据集进行训练时,深度学习模型便会被植入后门。
4、一个典型的基于数据投毒技术的后门攻击如图1所示,攻击者利用一个白色像素方块作为触发器δ,将其添加到样本的右下角,并将对应的标签修改为目标标签yt。这样一个触发器的添加过程可用式(1)表示:
5、xi+δ=xi⊙(1-m)+δ⊙m (1)
6、其中,xi表示第i个干净样本,δ表示触发器,⊙表示矩阵元素之间的点乘,m是图像掩码,m的大小与xi一致。若m中元素的值为1,则表示这一位置的图像像素由触发器δ对应位置的像素取代,若m中元素的值为0,则表示这一位置的图像像素保持不变。随后,深度学习模型就会在训练过程中构建起触发器和目标标签之间的联系。深度学习模型的训练可以视为在两个子集和上的优化过程,如式2所示。
7、
8、其中,θ′表示深度学习模型的权重参数,xi表示干净样本,yi表示xi的标签,yt表示目标标签,fθ′()表示权重参数为θ′下的深度学习模型,表示损失函数。当这样的深度学习模型被部署后,攻击者只需向任意样本中加入相同的触发器,深度学习模型便会预测为预先设定的目标标签,实现操纵深度学习模型预测的目的。
9、非侵入式语音质量评估(non-intrusive speech quality assessment,nisqa)技术通过算法自动对语音的质量进行量化,是语音领域中十分关键的一个回归任务,被广泛应用于各种语音下游任务,其中包括但不限于语音通信、语音合成和语音增强。在语音通信领域,nisqa可用于实时监测和评估语音通话的质量,从而提供关键的反馈信息以改善语音通信系统的性能。在语音合成领域,nisqa可用于评估合成语音的自然度和流畅度,从而提高语音合成系统的表现。在语音增强领域,nisqa可用于评估降噪、去混响等处理算法对语音质量的影响,以指导处理算法的改进和应用。并且,随着nisqa预测性能的不断提升,其正在逐渐被应用于多个关注安全的领域。例如,利用nisqa来提升空中交通管制通信过程中的语音质量,确保通信的清晰度和可理解性,从而提高飞行安全性;利用nisqa改进助听器语音增强算法的设置,通过评估算法对语音质量的影响,优化助听器的性能,提供更好的听觉支持和用户体验。现有的nisqa中的基于数据投毒技术的后门攻击都为边界值攻击,即攻击者希望深度学习模型预测结果为标签的最大值或最小值,为了实现这个目标,攻击者会将中毒样本的标签修改到原始干净数据集中的所有干净样本的标签的最大值或最小值附近。
10、后门攻击的出现极大地阻碍了深度神经网络在现实世界中的广泛使用。因此,保护深度学习模型免受后门攻击是至关重要的。设计强有力的后门防御方法可以帮助确保深度学习模型的安全性和可靠性,从而促进其在现实世界中的广泛应用。
11、目前,针对基于数据投毒技术的后门攻击的后门防御的主要研究集中在图像或语音分类领域,针对语音领域中的回归任务提出的后门防御方法十分缺失。而如果将图像或语音分类任务中的后门防御方法直接迁移到语音领域中的回归任务中,那么往往防御效果不佳。因为这些图像或语音分类任务中的后门防御方法往往没有考虑到后门攻击在回归任务中的特殊性。而目前针对语音领域中的回归任务提出的后门防御方法,其在每次训练迭代中从原始数据集中随机地选择大小为n的子集,并将子集中训练损失较大的样本剔除,该后门防御方法虽然能起到一定的防御效果,但无法应对投毒率较大时的后门攻击,且该后门防御方法的效率不高。
技术实现思路
1、本发明所要解决的技术问题是提供一种面向非侵入式语音质量评估的后门防御方法,其能够应对投毒率较大时的后门攻击,且效率高。
2、本发明解决上述技术问题所采用的技术方案为:一种面向非侵入式语音质量评估的后门防御方法,其特征在于包括以下步骤:
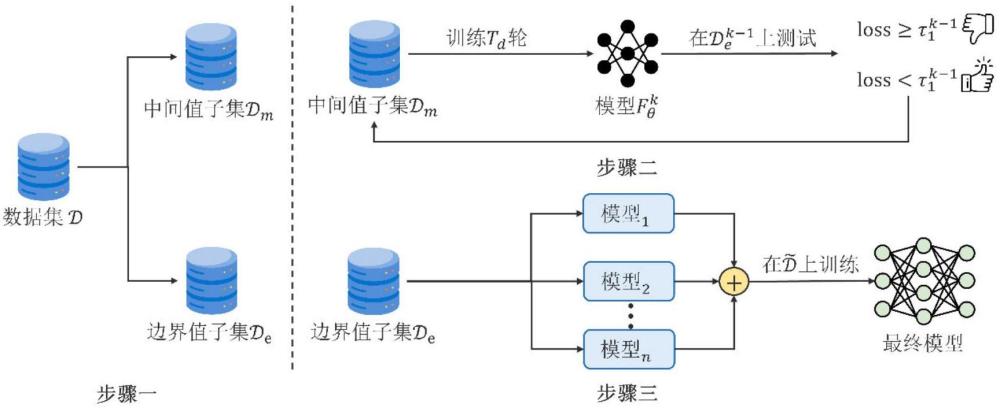
3、步骤1:对包含有干净样本及其干净标签和中毒样本及其目标标签的语音数据集进行预拆分,预拆分成两个子集,分别为中间值子集和边界值子集其中,干净样本和中毒样本均为语音样本,干净样本的干净标签为干净样本语音质量的量化值,中毒样本的目标标签为攻击者预先设定,干净样本的干净标签和中毒样本的目标标签均为mos分,值范围为[1,5];
4、步骤2:预设前期训练轮次为tr次,预设间隔轮次为td次,1<td<tr,设定迭代次数为k,k的初始值为1;重复基于中间值子集对nisqa模型进行训练,对边界值子集进行测试,利用预测结果变动中间值子集和边界值子集,具体过程为:
5、步骤2.1:在第k次迭代过程中,基于中间值子集对nisqa模型进行训练,在训练td轮后结束训练,得到第k次迭代过程训练后的nisqa模型然后使用nisqa模型对边界值子集进行测试,得到边界值子集中的每个语音样本的预测标签即伪标签,计算边界值子集中的每个语音样本的标签与预测标签的损失;再依次比较边界值子集中的每个语音样本对应的损失与的大小,若当前的语音样本对应的损失大于则认为当前的语音样本为中毒样本,保持当前的语音样本不动,若当前的语音样本对应的损失小于或等于则认为当前的语音样本不为中毒样本,将当前的语音样本移动到中间值子集中;在边界值子集中的所有语音样本对应的损失与比较完毕后,得到新的中间值子集和新的边界值子集再执行步骤2.2;其中,计算边界值子集中的每个语音样本的标签与预测标签的损失的损失函数采用nisqa模型中原有的损失函数,k=1时为步骤1中的中间值子集为步骤1中的边界值子集表示步骤1中的中间值子集中的所有语音样本的均方误差、表示未训练过的原始的nisqa模型,k>1时表示第k-1次迭代过程得到的中间值子集、表示第k-1次迭代过程得到的边界值子集、表示中的所有语音样本的均方误差、表示第k-1次迭代过程训练后的nisqa模型;
6、步骤2.2:判断k是否小于如果是,则令k=k+1,然后返回步骤2.1继续执行,直至得到第次迭代过程训练后的nisqa模型第次迭代过程得到的中间值子集第次迭代过程得到的边界值子集否则,基于第次迭代过程得到的中间值子集对第次迭代过程训练后的nisqa模型进行训练,在训练轮后结束训练,得到前期训练完成的nisqa模型并令令其中,为向下取整运算符号,k=k+1、中的“=”为赋值符号;
7、步骤3:选择n个未受到后门攻击且已训练完成的nisqa模型;然后使用这n个nisqa模型分别对步骤2中前期训练完成后得到的边界值子集进行测试,得到边界值子集中的每个语音样本的预测标签即伪标签;再依次遍历边界值子集中的每个语音样本,对当前遍历的语音样本的n个预测标签进行加权求和,并将加权求和得到的结果作为新标签替换掉当前遍历的语音样本原有的标签,直至边界值子集中的所有语音样本原有的标签替换完;其中,n>1;
8、步骤4:将步骤2中前期训练完成后得到的中间值子集和步骤3中替换标签后得到的边界值子集合并成语音数据集然后基于语音数据集对步骤2中前期训练完成的nisqa模型进行训练,在训练th轮后结束训练,得到后门攻击减缓的nisqa模型,实现了后门防御;其中,th表示预设的后期训练轮次。
9、所述步骤1中,对语音数据集进行预拆分的过程为:预设一个阈值th;再依次遍历语音数据集中的每个语音样本,若当前遍历的语音样本的标签落于[1,1+th]或[5-th,5]内,则将当前遍历的语音样本归入到边界值子集中;若当前遍历的语音样本的标签落于(1+th,5-th)内,则将当前遍历的语音样本归入到中间值子集中;在语音数据集中的所有语音样本遍历完毕后,得到中间值子集和边界值子集
10、所述步骤3中,n个未受到后门攻击且已训练完成的nisqa模型各不相同。
11、所述步骤3中,对当前遍历的语音样本的n个预测标签进行加权求和时所采用的权重为n个未受到后门攻击且已训练完成的nisqa模型对应的权重,设定第i个未受到后门攻击且已训练完成的nisqa模型对应的权重为wi,wi的获取过程如下:
12、步骤3.1:使用第i个未受到后门攻击且已训练完成的nisqa模型对步骤2中前期训练完成后得到的中间值子集进行测试,得到中间值子集中的每个语音样本的预测标签即伪标签;然后对中间值子集中的所有语音样本的标签与所有语音样本的预测标签进行相关性计算,得到中间值子集对应的第i个相关性值ci;其中,i∈[1,n];
13、步骤3.2:在步骤3.1的基础上,共得到中间值子集对应的n个相关性值;然后计算中间值子集对应的n个相关性值的和值sc;再计算
14、与现有技术相比,本发明的优点在于:
15、1)本发明方法利用nisqa回归任务中后门攻击多为边界值攻击的特点,快速地将语音数据集预拆分成两个子集,分别为中间值子集和边界值子集,中毒样本只可能出现在边界值子集中,这种子集分法使得本发明方法更适用于nisqa的后门防御。
16、2)本发明方法在对nisqa模型进行训练的过程中,采用基于损失的中毒样本过滤策略,按照一定的间隔轮次动态地过滤掉中间值子集中存在的中毒样本,使得中间值子集中尽量不含有中毒样本,从而达到减缓nisqa模型的后门攻击。此外,这种边训练边调整边界值子集的方式使得本发明方法相比现有方法在实现相同防御效果的前提下具有更高的效率。
17、3)本发明方法能够有效地减缓nisqa模型受到后门攻击的侵害,在确保原有预测性能(语音数据集中的所有样本用于训练,干净样本用于预测的情况)仅轻微降低的前提下,能够显著减少后门攻击的成功率。
18、4)现有回归任务中的后门防御在投毒率较大时会有较高概率选到中毒样本,从而使得后门被植入深度学习模型中,而本发明方法针对nisqa后门攻击中边界值攻击的特点预分割语音数据集,在投毒率较大时依然能够有效,即本发明方法能够应对投毒率较大时的后门攻击。
本文地址:https://www.jishuxx.com/zhuanli/20241015/314799.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。