虚拟试衣方法、装置、设备及存储介质与流程
- 国知局
- 2024-10-15 09:59:35
本公开涉及图像处理领域,尤其涉及虚拟试衣方法、装置、设备及存储介质。
背景技术:
1、随着互联网科技的不断发展,电子商务平台逐渐成为人们挑选购买衣物的主要途径。但是与线下亲自试穿相比,人们一般只能凭借经验来判断衣物是否合适,这也成为网购衣物大量退单的重要原因之一。此外,为了展示自家服装,大量电子商务卖家对模特试穿也有着及其旺盛的需求,而邀约模特拍摄的成本也成为了大多中小电子商务卖家头疼的问题之一,毕竟服装销售的销量与模特拍摄的质量成正比关系。
2、随着计算机视觉、图像处理以及人工智能技术的发展,虚拟试衣技术的研发在很大程度上缓解了上述两个难题。针对网购衣物无法亲自试穿的痛点,虚拟试衣能够使用户无需实际脱衣来更换衣物,只需上传一张自拍照,选中衣物,就能实现一键换装,极大提高了网购的效率以及客户的购物体验。针对模特约拍的成本痛点,卖家可以利用模特整成模块,通过文字描述模特的肤色,发型,身材等样貌细节来实现模特的生成(模特均由ai生成,无肖像权争议)。利用ai生成的模特来身穿卖家指定的衣物,可以大大降低中小电子商务卖家的成本。
3、现有的虚拟试衣相关技术主要可以分为两大类:
4、一是通过深度学习技术来根据人物的姿势体态预估衣物的形变,随后利用生成对抗网络将形变后的衣物与人物贴合到一块达到试衣效果。该类方法的缺点是,最后生成的图片分辨率通常较低,衣物形变无法产生相应的褶皱感,光影融合性较差;另外,服装与人物融合的边缘细节一般也比较粗糙,导致整体的试衣效果的整体逼真度较低。
5、二是由商户将衣物套上假人模特或者真人穿上衣物后当成底模任务,利用ai生成工具将底模人物替换成真实模特或者用户的肖像。该类方法的缺点是,虽然能在一定程度上缓解邀约模特拍摄的成本问题,但不仅商户操作麻烦,只能变换商户拍摄的指定姿势,而且将底模替换成真实用户形象的保真度离真实的用户形象还存在一定的差距,不能够在形象上使用户达到较为满意的购物体验。
技术实现思路
1、本公开提供了一种虚拟试衣方法、装置、设备及存储介质,解决了的技术问题。
2、根据本公开的第一方面,提供了一种虚拟试衣方法。该方法包括:
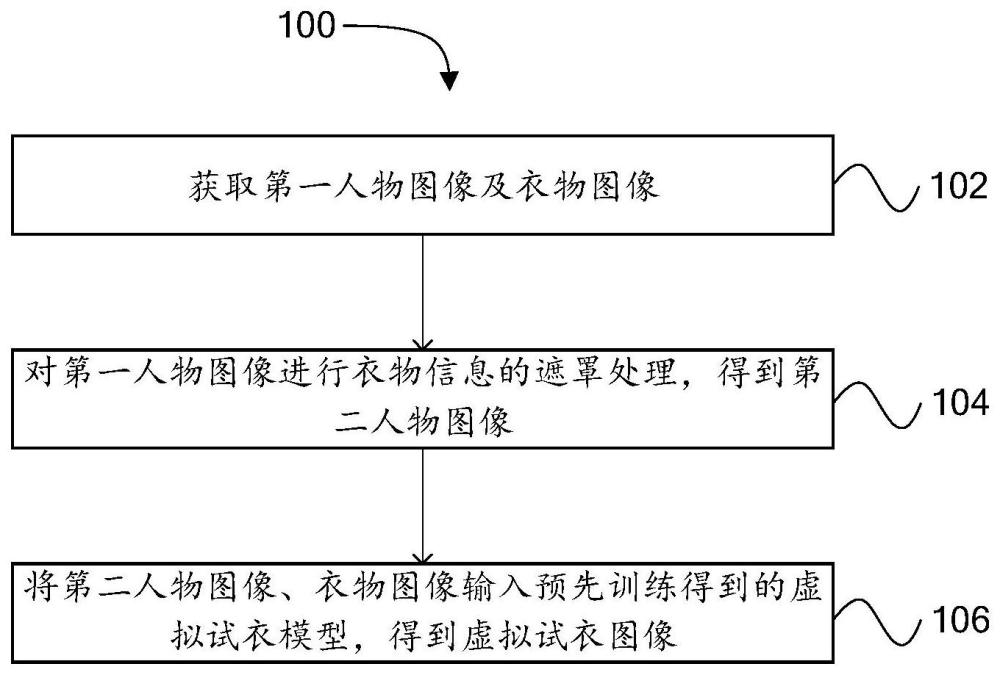
3、获取第一人物图像及衣物图像;
4、对所述第一人物图像进行衣物信息的遮罩处理,得到第二人物图像;
5、将所述第二人物图像、所述衣物图像输入预先训练得到的虚拟试衣模型,得到虚拟试衣图像;所述虚拟试衣模型为双u-net结构,包括图像编码器、两个u-net、图像解码器,其中,两个u-net分别作为衣物表征网络和潜在扩散网络;所述两个u-net网络结构一致,包括一个或多个下采样层、一个或多个中间层以及一个或多个上采样层。
6、如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述将所述第二人物图像、所述衣物图像输入预先训练得到的虚拟试衣模型,得到虚拟试衣图像包括:
7、将所述衣物图像输入图像编码器得到衣物潜在特征,将所述衣物潜在特征作为衣物表征网络的输入;记录上采样层、中间层与下采样层的进行空间自注意力运算时的特征;
8、将所述第二人物图像输入图像编码器得到人物潜在特征、遮罩区域信息,将所述人物潜在特征、遮罩区域信息以及一个服从高斯分布的随机噪声作为潜在扩散网络的输入;
9、将衣物表征网络记录的上采样层、中间层与下采样层的进行空间自注意力运算时的特征与潜在扩散网络进行迭代去噪的过程中相对应位置上的上采样层、中间层与下采样层的进行空间自注意力运算时的特征分别进行拼接,作为潜在扩散网络的相对应位置上的特征;
10、将潜在扩散网络输出的特征输入到图像解码器中,输出虚拟试衣图像。
11、如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述虚拟试衣模型的训练过程包括:
12、基于马尔科夫链的扩散步骤向训练样本中添加随机噪声,在反向过程中从噪声样本中恢复干净的样本,计算真实噪声与估计噪声之间的损失,反向传播更新潜在扩散网络的模型参数,直到收敛,保存模型参数并作为衣物表征网络的模型参数。
13、如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,对所述第一人物图像进行衣物信息的遮罩处理,得到第二人物图像包括:
14、将所述第一人物图像输入预先训练得到的深度学习图像语义分割神经网络模型进行语义分割,得到语义分割后的人物图像,所述语义分割后的人物图像至少包括划分了人体信息区域和衣物信息区域的图像;
15、将所述语义分割后的人物图像中的衣物信息区域进行遮罩处理,得到第二人物图像。
16、如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述将所述语义分割后的人物图像中的衣物信息区域进行遮罩处理包括:
17、获取衣物图像中的衣物与所述语义分割后的人物图像中的人物的贴合区域;将所述贴合区域与所述语义分割后的人物图像中的衣物信息区域的并集作为人物图像中需要进行遮罩处理的区域。
18、如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,获取衣物图像中的衣物与所述语义分割后的人物图像中的人物的贴合区域包括:
19、对所述语义分割后的人物图像进行姿态识别得到姿态信息;对所述衣物图像进行分割,分割出衣物的待遮罩区域;将所述待遮罩区域与所述姿态信息输入预先训练的浅层卷积神经网络,确定所述衣物图像中的衣物在所述语义分割后的人物图像中人体的遮罩区域,作为人物图像中需要进行遮罩处理的区域。
20、根据本公开的第二方面,提供了另一种虚拟试衣方法。该方法包括:
21、采用如第一方面所述的方法得到虚拟试衣图像;所述第一人物图像包括用户图像,所述衣物图像为至少两个,所述虚拟试衣图像分别与所述衣物图像对应;
22、在至少两个虚拟试衣图像中选择至少一个目标虚拟试衣图像进行展示或推荐。
23、根据本公开的第三方面,提供了一种虚拟试衣装置。该装置包括:
24、获取模块,用于获取第一人物图像及衣物图像;
25、衣物信息遮罩模块,用于对所述第一人物图像进行衣物信息的遮罩处理,得到第二人物图像;
26、虚拟试衣图像生成模块,用于将所述第二人物图像、所述衣物图像输入预先训练得到的虚拟试衣模型,得到虚拟试衣图像;所述虚拟试衣模型为双u-net结构,包括图像编码器、两个u-net、图像解码器,其中,两个u-net分别作为衣物表征网络和潜在扩散网络;所述两个u-net网络结构一致,包括一个或多个下采样层、一个或多个中间层以及一个或多个上采样层。
27、根据本公开的第四方面,提供了一种电子设备。该电子设备包括:存储器和处理器,所述存储器上存储有计算机程序,所述处理器执行所述程序时实现如以上所述的方法。
28、根据本公开的第五方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现如根据本公开的第一方面和/或第二方面的方法。
29、应当理解,技术实现要素:部分中所描述的内容并非旨在限定本公开的实施例的关键或重要特征,亦非用于限制本公开的范围。本公开的其它特征将通过以下的描述变得容易理解。
本文地址:https://www.jishuxx.com/zhuanli/20241015/316038.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。