一种题目的识别方法与流程
- 国知局
- 2024-10-21 14:31:33
本技术涉及图像数据处理领域,特别涉及一种题目的识别方法。
背景技术:
1、图像分割技术和字符识别技术的发展为题目图像的处理与识别提供了技术支持。区域生长、基于边缘检测的分割以及基于聚类的分割等算法的提出,可以实现对题目图像的有效分割。光学字符识别技术的进步,使得可以自动识别题目文本和公式信息。这些都是实现题目识别系统的重要基础。
2、目前的题目识别系统在分割题目区域时效果不佳,无法有效分割出包含完整题目信息的区域,导致后续特征提取和识别都受到影响。而对于含有公式的题目,系统中也缺乏对公式信息进行校验和纠正的步骤,直接影响最终的识别质量。
3、在相关技术中,比如中国专利文献cn112861864a中提供了题目录入方法包括以下步骤:获取初始图片;获取第一图片中的题目位置信息,得到题目图片;获得题目字符信息;判断题库中是否有匹配题目字符信息的题目;对题目文本进行结构化文本解析以获得题型描述特征,对所述题目图片进行识别以获得排版格式特征与试题特征,所述题型描述特征、所述排版格式特征与所述试题特征为所述题目结构化数据;发送题目结构化数据至智能终端以使其录入题目结构化数据。老师或学生均可在发现优质题目时通过对其拍摄以获得初始图片,上传初始图片至服务器以进行题目录入,无需通过打字而逐步输入题型、题干等内容,便于随时进行录题。但是该方案直接对原始图像进行分割,容易受噪声影响导致分割结果不准。
技术实现思路
1、要解决的技术问题
2、针对现有技术中存在的题目区域提取精度低问题,本技术提供了一种题目的识别方法,通过图像分割、特征提取和公式修正等,提高了题目识别的精度。
3、本技术的目的通过以下技术方案实现。
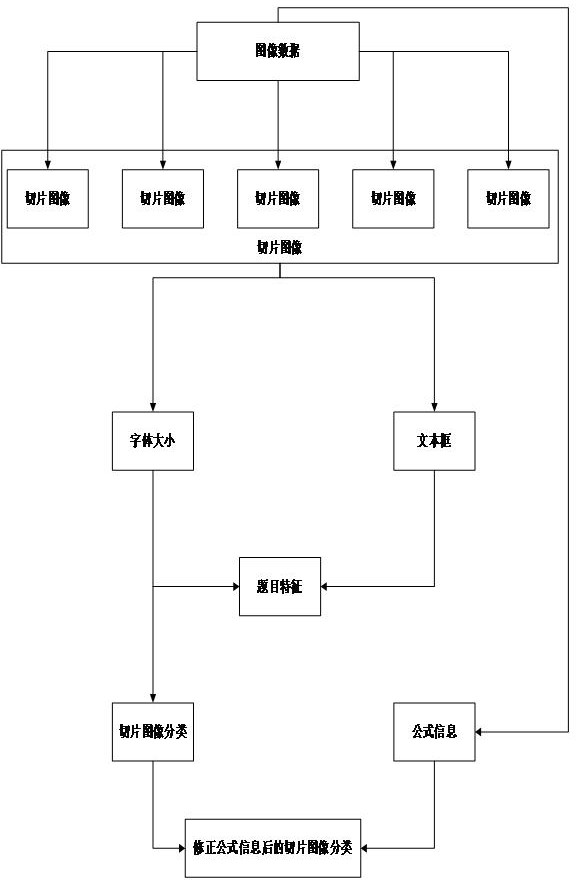
4、本说明书提供一种题目的识别方法,包括:通过扫描仪、摄像头等设备采集题目图像,得到原始图像数据;将原始图像数据转换为数字图像格式,如png、jpeg等。利用中值滤波算法对数字图像进行滤波,去除图像噪点;对滤波后的图像计算每个像素点的灰度值;根据灰度值计算相邻像素点之间的灰度差值,判断它们的连通性。以像素点为基本单元,根据像素点之间的连通性构建连通区域;使用dbscan聚类算法对连通区域进行聚类,得到多个聚类簇;将每个聚类簇对应的图像区域提取出来,形成单独的切片图像,每个切片图像仅包含一个完整的题目。对切片图像进行ocr文字识别,提取图像中的文本信息;利用自然语言处理技术,如词法分析、句法分析等,对提取的文本信息进行分析;根据分析结果,提取题目的题型(如选择题、填空题等)和选项个数等特征。将提取的题目特征作为输入,使用预训练的贝叶斯分类器对切片图像进行分类;根据分类结果,将切片图像划分为不同的题型类别,如选择题、填空题等。对每个切片图像进行ocr文字识别,提取图像中的文本信息;使用自然语言处理技术,如命名实体识别、关键词提取等,分析提取的文本信息;根据分析结果,判断题目的题干、选项、答案等信息。对每个切片图像进行ocr文字识别,提取图像中的公式区域;将提取的公式区域图像进行二值化、去噪等处理;使用公式识别算法,如基于模板匹配的方法,识别公式中的数学符号和结构。根据公式识别结果,提取公式的数学符号、结构和位置信息;将提取的信息按照math ml或latex的语法格式,生成相应的数据表示。构建数学公式的规则知识库,包括常见的数学符号、公式结构等;将math ml或latex格式的公式数据与规则知识库进行匹配;根据匹配结果,对公式数据进行修正,如补全缺失的符号、调整公式结构等。将经过公式修正的切片图像与其对应的题型分类结果、题干、选项、答案等信息进行关联;将关联后的数据存储到结构化的数据库中,如关系型数据库或nosql数据库;对存储的数据进行索引和优化,以便后续的查询和分析。
5、进一步的,判断相邻像素点之间的灰度值是否连通,包括:读取输入的彩色图像数据;将彩色图像转换为灰度图像,得到每个像素点的灰度值;将灰度图像数据存储在二维数组中,每个元素表示对应像素点的灰度值。定义sobel算子的水平和垂直方向的卷积核;对灰度图像数据进行卷积操作,计算每个像素点在水平和垂直方向上的梯度值;根据梯度值计算每个像素点的梯度幅值和方向;将梯度幅值作为相邻像素点之间灰度值的差值,存储在新的二维数组中。遍历灰度图像数据的每个像素点;以当前像素点为圆心,以预设的半径r为半径,构建一个圆形区域;将圆形区域内的所有像素点的坐标保存在一个数组中。对于每个圆形区域,计算其内部像素点灰度值的均值和标准差;根据均值和标准差,使用sauvola算法计算该区域的局部阈值;将计算得到的局部阈值存储在一个与圆形区域对应的数组中。对于每个像素点,获取其对应的圆形区域内的局部阈值;比较该像素点与其相邻像素点之间的灰度值差值与局部阈值的大小关系;如果灰度值差值小于局部阈值,则将该像素点标记为与相邻像素点连通;如果灰度值差值大于等于局部阈值,则将该像素点标记为与相邻像素点不连通。遍历所有像素点的连通性标记结果;对于标记为连通的像素点,将其与其相邻的连通像素点合并为同一个连通区域;对于标记为不连通的像素点,将其视为独立的连通区域;将生成的连通区域信息存储在一个新的数据结构中,如列表或数组。将存储连通区域信息的数据结构作为函数的返回值;或者将连通区域信息写入文件中,以便后续的处理和分析。
6、进一步的,采用dbscan聚类算法对预处理后的图像数据进行划分,包括:从存储预处理结果的数据结构中读取图像数据;获取图像的宽度和高度信息;将图像数据转换为二维数组形式,每个元素表示对应像素点的灰度值。设置聚类的邻域半径r,表示以像素点为圆心的圆形区域的半径;设置邻域内最小像素点数量阈值minpts,用于判断像素点是否为核心点;初始化一个标记数组,用于记录每个像素点的聚类类别,初始值为未访问状态。如果当前像素点已经被访问过,则跳过该像素点,继续遍历下一个像素点;如果当前像素点未被访问过,则将其标记为已访问,并进行以下步骤。计算当前像素点的行和列坐标;根据行和列坐标以及邻域半径r,确定圆形邻域内的像素点范围;将圆形邻域内的像素点的坐标保存在一个数组中。统计圆形邻域内灰度值连通的像素点数量;如果连通像素点数量大于等于minpts,则将当前像素点标记为核心点;如果连通像素点数量小于minpts,则将当前像素点标记为非核心点。创建一个新的聚类类别,并将当前像素点归属到该类别中;遍历当前像素点的圆形邻域内的所有像素点;对于每个邻域内的像素点,如果它未被访问过,则将其标记为已访问,并将其归属到当前聚类类别中;如果邻域内的像素点也为核心点,则递归地对其进行处理,将其邻域内的像素点也归属到当前聚类类别中。如果当前像素点为非核心点,则将其标记为噪声点,不属于任何聚类类别。重复,直到图像中所有像素点都被访问并归属到对应的聚类类别中。遍历聚类类别标记数组,将属于同一聚类类别的像素点提取出来,形成一个切片图像;对每个切片图像,生成一个唯一的标识符,如切片编号或文件名;将切片图像数据和对应的标识符保存在一个数据结构中,如数组或字典。将保存切片图像数据和标识符的数据结构作为函数的返回值;或者将切片图像数据写入文件中,以便后续的处理和分析。
7、进一步的,采用sauvola算法计算圆形区域内的阈值,包括:从存储预处理结果的数据结构中读取图像数据;获取图像的宽度和高度信息;将图像数据转换为二维数组形式,每个元素表示对应像素点的灰度值。根据图像的大小和细节特征,设定合适的圆形区域半径r;根据图像的对比度和噪声水平,设定合适的经验参数k。具体的,设定经验参数k,包括:计算图像的最大灰度值max_val和最小灰度值min_val;计算全局对比度contrast,即contrast=(max_val-min_val)/(max_val+min_val)。对图像进行高通滤波,提取出图像中的高频噪声成分;计算高频噪声的标准差noise_std,表示图像噪声的强度。当全局对比度较高且噪声水平较低时,说明图像质量较好,可以选择较小的k值,如0.2-0.4;当全局对比度较低且噪声水平较高时,说明图像质量较差,需要选择较大的k值,如0.6-0.8;当全局对比度和噪声水平适中时,可以选择中等的k值,如0.4-0.6。
8、获取当前像素点的行和列坐标;以当前像素点为圆心,构建半径为r的圆形区域。初始化一个长度为256的数组,用于存储灰度直方图,每个元素表示对应灰度值的像素点数量;遍历圆形区域内的所有像素点;对于每个像素点,获取其灰度值,并将对应灰度值在灰度直方图数组中的计数加1。将灰度直方图数组中的每个元素除以圆形区域内的总像素点数,得到归一化的灰度直方图;将归一化的灰度直方图作为当前圆形区域的灰度分布特征。初始化变量sum和sum_sq,用于存储灰度值的总和和灰度值平方的总和;遍历灰度直方图数组,对于每个灰度值i:将i乘以对应的归一化频率,累加到sum中;将i的平方乘以对应的归一化频率,累加到sum_sq中;计算平均灰度值u,即u=sum;计算灰度值的标准差s,即s=sqrt(sum_sq-u^2)。获取圆形区域内的最大灰度值p;将平均灰度值u、灰度标准差s、经验参数k和最大灰度值p代入改进的sauvola公式;,计算得到当前圆形区域的阈值t。将计算得到的阈值t赋值给当前像素点,作为其对应的局部阈值。遍历完所有像素点,得到每个像素点对应的局部阈值。将存储局部阈值的二维数组作为函数的返回值;或者将局部阈值数据写入文件中,以便后续的处理和分析。
9、进一步的,利用dbscan聚类算法将包含同一题目的像素点区域进行聚类,得到切片图像,包括:从存储预处理结果的数据结构中读取图像数据;获取图像的宽度和高度信息;将图像数据转换为二维数组形式,每个元素表示对应像素点的灰度值。设置聚类的邻域半径r,表示以像素点为圆心的圆形区域的半径;设置邻域内最小像素点数量阈值minpts,用于判断像素点是否为核心点;设置灰度值连通性阈值t,用于判断像素点之间是否连通;初始化一个标记数组,用于记录每个像素点的聚类类别,初始值为未访问状态。具体的,设置邻域内最小像素点数量阈值minpts,包括:采用迭代的方式,逐步优化minpts阈值的取值;初始设置一个较大的minpts阈值,对图像进行聚类,得到初步的切片区域;评估切片区域的质量,如区域内像素点的一致性、区域边界的平滑度等;根据评估结果,调整minpts阈值,重新进行聚类,得到更优的切片区域;迭代多次,直到切片区域的质量满足预设的标准,得到最终的minpts阈值。
10、如果当前像素点已经被访问过,则跳过该像素点,继续遍历下一个像素点;如果当前像素点未被访问过,则将其标记为已访问,并进行以下步骤。计算当前像素点的行和列坐标;根据行和列坐标以及邻域半径r,确定第一圆形区域内的像素点范围;将第一圆形区域内的像素点的坐标保存在一个数组中。遍历第一圆形区域内的所有像素点;对于每个像素点,判断其与圆心像素点的灰度值差是否小于阈值t,如果是,则将其标记为连通像素点;统计连通像素点的数量,得到第一圆形区域内的像素点数量。如果第一圆形区域内的像素点数量大于阈值minpts,则将圆心像素点标记为第一核心点;如果第一圆形区域内的像素点数量小于等于阈值minpts,则将圆心像素点标记为非核心点。以第一核心点为圆心,构建半径为r的第二圆形区域;统计第二圆形区域内的像素点数量;判断第二圆形区域对应的圆心是否为第二核心点。创建一个新的聚类类别,并将当前像素点归属到该类别中;遍历第二圆形区域内的所有像素点;对于每个像素点,如果它未被访问过且与当前核心点连通,则将其标记为已访问,并将其归属到当前聚类类别中;如果该像素点也为第二核心点,则递归地对其进行处理,将其第二圆形区域内的连通像素点也归属到当前聚类类别中。如果当前像素点为非核心点,则将其标记为噪声点,不属于任何聚类类别。重复直到图像中所有像素点都被访问并归属到对应的聚类类别中。遍历聚类类别标记数组,将属于同一聚类类别的像素点提取出来,形成一个切片图像;对每个切片图像,生成一个唯一的标识符,如切片编号或文件名;将切片图像数据和对应的标识符保存在一个数据结构中,如数组或字典。将保存切片图像数据和标识符的数据结构作为函数的返回值;或者将切片图像数据写入文件中,以便后续的处理和分析。
11、进一步的,采用自然语言处理方法提取切片图像的题目特征,题目特征包含题型和选项个数,包括:将切片图像转换为灰度图像,降低颜色对后续处理的影响;对灰度图像进行二值化处理,将文本区域与背景区域分离;对二值化图像进行去噪和平滑处理,消除孤立的噪点和细小的断点。对二值化图像进行垂直方向的投影,得到每一列上黑色像素点的数量;根据投影结果,确定文本行的垂直边界,即文本行的上下界;对于每一个文本行,进行水平方向的投影,得到每一行上黑色像素点的数量;根据水平投影结果,确定文本行的水平边界,即文本行的左右界;将确定的垂直边界和水平边界组合,得到每个文本行的边界框。对于每对相邻的文本行边界框,计算它们在垂直方向上的距离;记录所有相邻文本行边界框之间的距离,并找出其中的最小值;将最小距离作为文本行间距,表示相邻文本行之间的标准间隔。设定一个间距阈值,用于判断相邻文本行是否属于同一题目;对于每对相邻的文本行边界框,计算它们在垂直方向上的距离;如果距离小于等于间距阈值,则判断这两个文本行属于同一题目的内容;如果距离大于间距阈值,则判断这两个文本行属于不同题目的内容。对于每个文本行,使用光学字符识别(ocr)技术提取文本内容;对提取的文本内容进行预处理,如去除特殊字符、转换大小写等;使用自然语言处理技术对文本内容进行分析,如分词、词性标注、命名实体识别等;根据分析结果,提取文本行中的关键信息,如题干、选项等。根据提取的关键信息,判断题目的题型,如单选题、多选题、判断题等;对于选择题,通过识别选项前的标号(如a、b、c、d等),确定选项的个数;对于其他题型,根据题目的特定格式和关键词,判断题型和选项个数。将题型和选项个数转换为数值化的特征表示;可以使用one-hot编码或其他编码方式,将题型和选项个数映射为向量空间中的点;将题目的其他特征,如题干长度、关键词出现频率等,也纳入特征向量中;最终得到每个题目的特征向量,表示题目的题型、选项个数等特征。将每个题目的特征向量与对应的题目编号或标识符关联;将题目特征结果保存在结构化的数据格式中,如csv、json等;或者将题目特征结果直接传递给后续的题目分析和处理模块,进行进一步的分析和应用。
12、进一步的,提取切片图像的题目特征,包括:对每个文本行内的二值化图像进行轮廓检测,找出所有闭合的轮廓;根据轮廓的大小和形状特征,筛选出代表文字的轮廓;对每个文字轮廓,确定其左右边界和上下边界,得到文字的边界框。对于每个文字的边界框,生成其最小外接矩形;计算最小外接矩形的高度,将其作为文字的字体大小;记录每个文字的字体大小,以便后续的分析和判断。设定一个字体大小阈值,用于判断文字是否属于题干内容;对于每个文字,比较其字体大小与阈值的大小关系;如果字体大小大于阈值,则判断该文字属于题干内容;如果字体大小小于等于阈值,则判断该文字属于其他内容,如选项、题号等。将题型、选项个数以及题干内容转换为数值化的特征表示;可以使用one-hot编码或其他编码方式,将题型和选项个数映射为向量空间中的点;对题干内容进行特征提取,如提取关键词、计算词频等,生成题干内容的特征向量;将题目的其他特征,如题目长度、关键词出现频率等,也纳入特征向量中;最终得到每个题目的特征向量,表示题目的题型、选项个数和题干内容等特征。将每个题目的特征向量与对应的题目编号或标识符关联;将题目特征结果保存在结构化的数据格式中,如csv、json等;或者将题目特征结果直接传递给后续的题目分析和处理模块,进行进一步的分析和应用。
13、进一步的,利用光学字符识别算法和自然语言处理方法提取分类后的切片图像中的语义特征,根据提取的语义特征判断题目信息,包括:将切片图像转换为灰度图像,降低颜色对后续处理的影响;对灰度图像进行二值化处理,将文本区域与背景区域分离;对二值化图像进行去噪和平滑处理,消除孤立的噪点和细小的断点。对二值化图像进行连通域分析,找出所有连通的像素区域;根据连通域的大小、长宽比等特征,筛选出可能为文本框的连通域;对筛选出的连通域进行边界框提取,得到多个文本框的位置和大小信息。对于每个文本框,计算其边界框的宽度和高度;将宽度和高度相乘,得到文本框的面积;记录每个文本框的面积值,并找出面积最大的文本框。将面积最大的文本框标记为题目文本框;记录题目文本框的位置和大小信息,用于后续的坐标计算和文本提取。根据题目文本框的边界框信息,提取其左上、右上、左下、右下四个顶点的坐标;记录四个顶点坐标,用于后续的坐标变换和位置判断。根据题目文本框的四个顶点坐标,计算其中心点的坐标;将中心点坐标作为题目文本框的参考点,用于建立局部坐标系。将题目文本框的中心坐标作为局部坐标系的原点(0,0);以原点为中心,建立局部坐标系的横轴和纵轴方向。设定一个正数阈值k,用于区分选项和非选项文本框;对于每个文本框,计算其中心坐标在局部坐标系下的横坐标值;判断横坐标值是否满足大于k或小于-k的条件;如果满足条件,则将该文本框标记为选项文本框;否则,标记为非选项文本框。使用ocr算法对题目文本框内的图像区域进行文字识别;将识别结果转换为文本格式,得到题目文本框内的文本信息。对文本信息进行分词、词性标注、命名实体识别等自然语言处理操作;提取文本信息中的关键词、短语等语义特征;根据语义特征构建题目的语义表示,如关键词向量、语义网络等。如果文本框的中心坐标满足横坐标大于k或小于-k的条件,且语义特征包含“单选”关键词,则判断题目文本框对应的题型为单选题;如果文本框的中心坐标不满足横坐标条件,且语义特征包含“多选”关键词,则判断题目文本框对应的题型为多选题;如果仅满足文本框的中心坐标判断条件或文本信息判断条件之一,则根据满足的条件进行题型判断,优先级为文本信息分析结果高于中心坐标判断结果;如果文本框的中心坐标判断和文本信息分析均不满足条件,则通过人工校对的方式确定题型。将判断得到的题型、题目文本框的位置和文本内容等信息进行组织和格式化;以结构化的方式输出题目信息,如json、xml等格式;
14、进一步的,利用基于规则的方法,根据math ml或latex格式的数据对分类后的切片图像中的公式信息进行修正,具体步骤包括:预先定义公式位置区间范围,指定公式在切片图像中的合理位置范围,如图像中心区域、左上角区域等;预先定义公式大小阈值范围,指定公式在切片图像中的合理大小范围,如占图像面积的10%~30%;预先定义公式语法特征,指定合法的math ml或latex语法规则,如标签嵌套、命令使用等;将定义的公式位置区间范围、公式大小阈值范围和公式语法特征组织成结构化的规则知识库。使用公式语法解析算法,如正则表达式匹配、语法树分析等,识别切片图像中的公式区域;对识别出的每个公式区域,提取其对应的math ml数据段或latex数据段;记录每个公式区域的位置信息和对应的数据段,用于后续的坐标定位和面积计算。利用坐标定位算法,如边界框检测、轮廓分析等,获取数据段在对应切片图像中的坐标位置;计算数据段的边界框坐标(左上角和右下角坐标),或提取数据段的轮廓坐标序列;利用像素统计算法,如面积计算、像素计数等,计算数据段占切片图像的面积比例;将计算得到的坐标位置和面积比例与数据段关联,形成完整的公式信息。对于每个提取得到的公式信息,分别与规则知识库中的公式位置规则、公式大小规则和公式语法规则进行匹配;判断公式的坐标位置是否在预定义的合理位置区间范围内,如果不在,则标记为位置错误;判断公式的面积比例是否在预定义的合理大小阈值范围内,如果不在,则标记为大小错误;判断公式的math ml数据段或latex数据段是否符合预定义的语法特征,如果不符合,则标记为语法错误。如果公式信息与规则知识库匹配失败,则根据错误类型采取相应的修正策略;对于位置错误,采用公式位置调整策略,如平移、缩放等,将公式调整到合理的位置区间范围内;对于大小错误,采用公式大小调整策略,如缩放、裁剪等,将公式调整到合理的大小阈值范围内;对于语法错误,采用公式语法修正策略,如标签补全、命令替换等,将math ml数据段或latex数据段修正为符合语法特征的形式。对于成功进行修正的公式,更新其对应的math ml数据段或latex数据段;将更新后的数据段重新与公式的位置信息关联,形成修正后的完整公式信息;将修正后的公式信息存储或传递给后续的处理模块,如公式渲染、公式识别等。重复,对分类后的切片图像中的所有公式信息进行匹配、修正和更新;直到所有公式信息都得到正确的修正和更新,或达到预设的迭代次数限制。将修正后的公式信息进行组织和格式化,如json、xml等格式;输出修正后的公式信息,包括公式的位置坐标、面积比例、修正后的math ml数据段或latex数据段等;将输出的公式信息传递给后续的任务模块,如公式渲染、公式识别、题目分析等,用于进一步的处理和应用。
15、进一步的,匹配失败的情况包括以下三种:公式的位置坐标超出规则知识库中预定义的位置区间范围:在规则知识库中,预定义了公式在切片图像中的合理位置区间范围,如图像中心区域、左上角区域等;对于提取得到的每个公式信息,获取其位置坐标(如左上角坐标和右下角坐标);判断公式的位置坐标是否在预定义的位置区间范围内,即比较坐标值与区间边界值的大小关系;如果公式的位置坐标超出了预定义的位置区间范围,则将其标记为位置匹配失败;位置匹配失败的情况可能包括:公式过于偏左、偏右、偏上、偏下,或者完全位于图像的边缘区域等。公式的大小超出规则知识库中预定义的大小阈值范围:在规则知识库中,预定义了公式在切片图像中的合理大小阈值范围,如占图像面积的10%~30%;对于提取得到的每个公式信息,计算其大小(如公式区域的像素面积);计算公式大小占切片图像总面积的比例,即公式面积除以切片图像面积;判断公式大小比例是否在预定义的大小阈值范围内,即比较比例值与阈值范围的上下界;如果公式的大小比例超出了预定义的大小阈值范围,则将其标记为大小匹配失败;大小匹配失败的情况可能包括:公式过大、过小,或者与切片图像的尺寸不协调等。公式的math ml数据或latex数据不符合规则知识库中预定义的语法特征:在规则知识库中,预定义了合法的math ml或latex语法特征,如标签嵌套规则、命令使用规则等;对于提取得到的每个公式信息,获取其对应的math ml数据段或latex数据段;利用语法解析器或正则表达式等工具,分析math ml数据段或latex数据段的语法结构;将分析得到的语法结构与预定义的语法特征进行匹配,判断是否符合规则;如果math ml数据段或latex数据段的语法结构不符合预定义的语法特征,则将其标记为语法匹配失败;语法匹配失败的情况可能包括:标签不匹配、命令使用错误、括号不配对、缺少必要的参数等。
16、对于匹配失败的公式信息,需要进行相应的错误处理和修正:位置匹配失败的处理:采用公式位置调整策略,如平移、缩放等,将公式的位置坐标调整到预定义的合理位置区间范围内;可以根据公式的偏移方向和距离,计算出需要平移或缩放的量,并对公式的坐标进行相应的变换;调整后的公式位置应该满足规则知识库中预定义的位置区间范围,确保公式在切片图像中的位置合理。大小匹配失败的处理:采用公式大小调整策略,如缩放、裁剪等,将公式的大小调整到预定义的合理大小阈值范围内;可以根据公式的当前大小比例与阈值范围的差距,计算出需要缩放或裁剪的比例因子,并对公式进行相应的变换;调整后的公式大小应该满足规则知识库中预定义的大小阈值范围,确保公式在切片图像中的大小合适。语法匹配失败的处理:采用公式语法修正策略,如标签补全、命令替换等,将mathml数据段或latex数据段修正为符合语法特征的形式;可以利用语法修正规则或模板,对不符合语法的部分进行替换、插入或删除操作,使其符合预定义的语法特征;修正后的mathml数据段或latex数据段应该能够通过语法解析器的检查,确保其语法结构正确。
17、相比于现有技术,本技术的优点在于:
18、通过引入图像分割和特征提取技术,本技术能够更准确地识别和定位图像中的题目区域。这有助于克服传统方法在处理复杂题目结构和排版时可能出现的精度低的问题。通过更有效的区域提取,系统可以更精细地分析题目的各个部分,从而提高整体的识别精度;
19、本技术利用特征提取的方法,可以更好地适应不同题型和排版风格。这种灵活性使得系统能够处理各种多样化的题目,包括不同字体、大小和排列方式的题目。通过在特征提取阶段的优化,系统更有可能正确识别并解析多样化的题目结构,提高了系统的通用性和适用性;
20、引入公式修正作为本技术的一部分,有助于纠正由于复杂公式和排版而引起的识别错误。这种技术特征通过对公式结构进行修正,进一步提高了题目识别的准确性。对于包含数学或科学公式的题目,公式修正的步骤可以显著提升整体的解析准确性,使系统更适用于涉及符号和数学表达式的题目。
21、本方法通过连通域分析算法对图像进行切割,获取包含单个题目的切片图像;然后提取每个切片图像的题目特征,包括题型和选项个数;接着运用贝叶斯分类对切片图像进行分类;同时使用光学字符识别和公式识别算法识别题目中的公式信息,并利用规则方法消除识别错误;最终生成含有修正后的公式信息的切片图像分类结果,提高了题目提取的精度。
本文地址:https://www.jishuxx.com/zhuanli/20241021/318455.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。