基于深度强化学习的水下多无人平台协同跟踪方法及系统
- 国知局
- 2024-10-21 15:03:03
本发明属于水下多传感器目标跟踪,特别涉及一种基于深度强化学习的水下多无人平台协同跟踪方法及系统。
背景技术:
1、随着以自主式水下航行器(autonomous underwater vehicle,auv)为代表的水下无人平台的快速发展,通过多个水下无人平台组网构成的水下多无人平台协同跟踪系统逐渐成熟且备受关注。
2、水下多无人平台协同跟踪系统,可综合利用各个子平台的侦察、监视、探测和通信能力,对来自水下目标进行早期发现、跟踪、识别、估计,为组织对抗行动提供实时信息保障。相较于传统水下目标跟踪系统,水下多无人平台协同跟踪系统具有结构自组织、容错性强、隐蔽性强的优点。然而,由于水下多无人平台协同跟踪系统自身结构特性和复杂的水下环境,其也面临着诸多挑战;其中,一方面,水下无人平台需要使用电池能量、计算性能和通信性能等受限资源来实现跟踪性能和系统资源消耗的平衡;另一方面,受复杂的水声环境影响,系统获得的多源信息动态变化且噪声干扰较大,严重缺乏环境的先验知识。
3、上述情况导致水下多无人平台调度和多无人平台数据融合,成为了基于水下多无人平台的水下目标跟踪技术中的关键。由于传统调度方法和数据融合方法依赖环境先验知识,难以适应动态变化的水下目标跟踪环境,导致系统性能受损;另外,传统的水下目标跟踪框架传统服从步进式架构,即按“多平台调度-局部估计-多平台数据融合”流程执行跟踪任务,这导致在同时面临多平台调度、多平台数据融合这类流程复杂的任务时,系统会出现顾此失彼的现象,严重影响系统的性能。综上所述,如何在无先验知识和动态环境中有效调度水下多无人平台以实现高能效跟踪,如何充分利用多源动态变化的信息,寻找最优节点融合策略,确保数据融合精度满足跟踪任务需求,以及如何突破传统跟踪框架的限制,优化多重复杂任务下的协同跟踪任务执行效率成为了水下多无人平台系统面临的重要问题。
技术实现思路
1、本发明的目的在于提供一种基于深度强化学习的水下多无人平台协同跟踪方法及系统,以解决复杂水下环境、能量受限情况下的水下多无人平台的动态调度和数据融合问题。本发明具体提供了一种基于深度强化学习的水下多无人平台协同跟踪方案,构建了新型端到端水下多无人平台协同跟踪框架,能够实现水下多无人平台在多源动态信息下的高能效目标跟踪,能够在有效降低系统能耗的同时显著提升系统的任务执行效率和协同跟踪性能,可提升水下多无人平台在复杂水下目标跟踪环境中的应用性能和系统效率。
2、为达到上述目的,本发明采用以下技术方案:
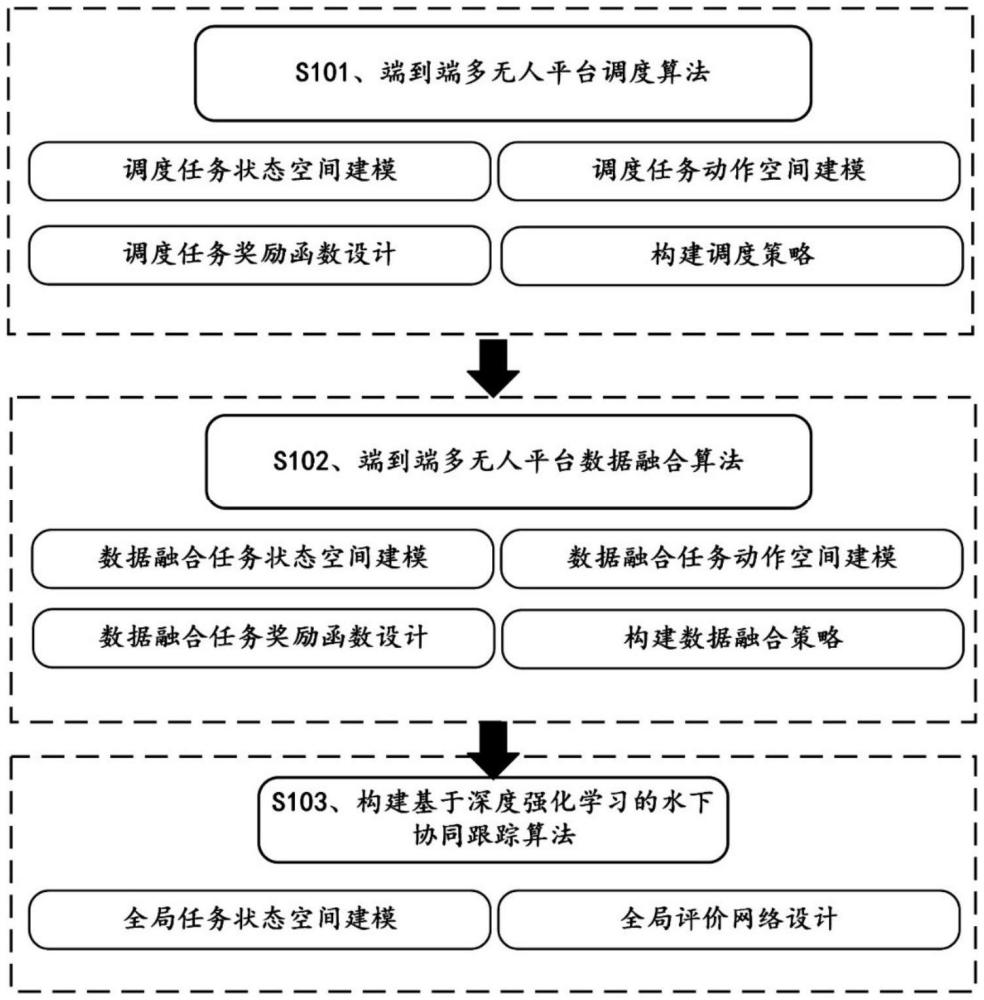
3、本发明第一方面,提供一种基于深度强化学习的水下多无人平台协同跟踪方法,包括以下步骤:
4、利用强化学习将复杂水下环境下的水下多无人平台动态调度问题建模为马尔可夫决策过程模型,并在奖励函数的设计中结合能效优化目标函数和基于虚拟数据法的跟踪性能评估函数,建立获得端到端的水下多无人平台调度算法;其中,所述端到端的水下多无人平台调度算法包括调度任务状态空间、调度任务动作空间、调度任务奖励函数以及多平台调度策略;
5、利用强化学习将多源动态信息下的水下多无人平台数据融合问题建模为马尔可夫决策过程模型,并在奖励函数的设计中结合基于虚拟数据法的数据融合性能评估函数,建立获得端到端的水下多无人平台调度算法;其中,所述端到端的水下多无人平台调度算法包括数据融合任务状态空间、数据融合任务动作空间、数据融合任务奖励函数及多平台数据融合策略;
6、结合端到端的水下多无人平台调度算法以及端到端的水下多无人平台调度算法建立过程中建模的马尔可夫决策过程模型,引入深度强化学习中的mappo算法同时对多平台调度策略、多平台数据融合策略进行学习,通过环境的反馈评估当前策略的有效性,最终确定当前环境下的最优跟踪策略。
7、本发明的进一步改进在于,所述端到端的水下多无人平台调度算法中,
8、调度任务状态空间ssc中,k时刻的调度任务状态空间表示为,
9、
10、式中,为k时刻的调度任务状态空间;为k时刻的系统跟踪误差;为k时刻的系统剩余能量;为优选普通平台组成的子集;
11、调度任务动作空间asc中,k时刻的调度任务动作空间表示为,
12、
13、式中,为k时刻的调度任务动作空间;ok为候选普通平台集合;n*为中平台的数量;
14、调度任务奖励函数rsc表示为,
15、
16、式中,tend为系统协同跟踪系统时间;为即时奖励;为结算奖励;
17、多平台调度策略的生成过程中,结合建立的马尔可夫决策过程模型,引入ppo进行调度策略生成;ppo由执行网络和评价网络构成,执行网络用于策略生成,评价网络用于策略评估,基于ppo中的执行网络进行端到端调度策略生成;其中,
18、k时刻的执行网络的损失函数如下所示,
19、
20、式中,θsc为调度任务中的执行网络参数;ξ(·)为截断函数,用于将调度策略评估函数控制在[1-τ,1+τ]内,τ为超参数;
21、如下所示,
22、
23、式中,为基于参数θ′的策略;为基于参数θ的策略;ak,sk分别为k时刻的调度任务动作,调度任务状态;
24、ηk为k时刻的优势估计函数,如下所示,
25、ηk=δk+γλδk+1+…+(γλ)t′-k+1δt′-1
26、δk=rk+γv(sk+1)-v(sk);
27、式中,t′为协同跟踪任务所需的总时间;v(·)为价值函数;λ、γ均为折扣因子;δk为累积时间差异误差;
28、执行网络的输入为多无人平台调度状态,输出为生成的多无人平台调度策略。
29、本发明的进一步改进在于,即时奖励表示为,
30、
31、式中,α∈(0,1)为调整观测性能函数与能量损耗函数两部分比例的联合因子;ok为候选普通平台集合;为观测性能函数;为能量损耗函数;
32、
33、式中,为fisher信息矩阵;
34、
35、式中,mk+1表示对目标的预测位置信息,xk表示候选普通平台与目标预测位置之间的相对位置信息;
36、
37、式中,n为普通平台个数;为候选平台在k+1时刻的剩余能量;和分别表示候选平台在k+1时刻与中心平台、普通平台相互通信所需的能量消耗。
38、本发明的进一步改进在于,结算奖励表示为,
39、
40、式中,a、b为平衡目标跟踪精度和系统能效两部分比例的联合因子;为每轮训练跟踪精度;egoal为目标精度;egoal为目标能耗;为每轮训练系统能耗;为总训练轮次;
41、
42、式中,t为系统跟踪持续时间;
43、
44、式中,为i个普通平台得到的k时刻的虚拟量测和真实量测之间的虚拟偏差;为k时刻和之间的欧式距离;
45、
46、式中,为生成的虚拟量测;h(·)为已知的量测方程;为通过状态估计生成的量测预测值;v为量测噪声协方差。
47、本发明的进一步改进在于,所述端到端的水下多无人平台调度算法中,
48、数据融合任务状态空间sf中,k时刻的数据融合任务状态空间表示为,
49、
50、w1+w2+…+wn=1;
51、式中,pf代表融合估计协方差;表示数据融合估计;nf为参与数据融合的平台总个数;pi和代表平台i的局部估计协方差和局部状态估计,wi∈[0,1]为平台i对应的数据融合权重;
52、数据融合任务动作空间af中,k时刻的数据融合任务动作空间表示为,
53、
54、数据融合任务奖励函数rf表示为,
55、
56、式中,tend为系统协同跟踪持续时间;为即时奖励;为结算奖励;
57、数据融合策略生成的过程中,结合建立的马尔可夫决策过程模型,基于ppo中的执行网络进行端到端多平台数据融合策略生成;其中,
58、k时刻,数据融合任务的执行网络的损失函数lf(θf)表示为,
59、
60、式中,θf为数据融合任务中的执行网络参数;为数据融合策略评估函数;
61、
62、式中,为基于参数θf′的数据策略;为基于参数θf的策略;分别为k时刻的数据融合任务动作和数据融合任务状态;
63、ηk为k时刻融合任务中的优势估计函数,如下所示,
64、ηk=δk+γλδk+1+…+(γλ)t′-k+1δt′-1
65、
66、执行网络的输入为数据融合状态,输出为生成的数据融合策略。
67、本发明的进一步改进在于,即时奖励表示为,
68、
69、式中,为参与数据融合的n*个平台得到的k时刻的虚拟量测和真实量测之间的虚拟偏差;为k时刻和之间的欧式距离。
70、本发明的进一步改进在于,结算奖励表示为,
71、
72、式中,为数据融合估计目标精度;为每轮训练数据融合估计精度;为总训练轮次。
73、本发明的进一步改进在于,所述结合端到端的水下多无人平台调度算法以及端到端的水下多无人平台调度算法建立过程中建模的马尔可夫决策过程模型,引入深度强化学习中的mappo算法同时对多平台调度策略、多平台数据融合策略进行学习,通过环境的反馈评估当前策略的有效性,最终确定当前环境下的最优跟踪策略的步骤具体包括:
74、基于mappo的基本理念,将多无人平台调度任务和多无人平台数据融合任务视作两个执行独立任务的智能体;其中,两个智能体通过各自的执行网络与环境进行交互,实现策略更新,通过一个全局评价网络获取两个任务的全局状态并对两个智能体生成的策略进行评价,实现两个任务的策略协同更新,从而建立端到端的水下多无人平台协同跟踪框架;其中,
75、全局任务状态空间建模为
76、全局评价网络结合全局任务状态,同时对调度任务和数据融合任务的策略进行评价,使两者的策略能够在全局情况下协同更新;
77、全局评价网络的损失函数如下所示,
78、
79、式中,θc为全局评价网络参数;ri为累积折扣汇报;nt为智能体个数;v(·)为新策略价值函数;v′(·)为旧策略价值函数;
80、全局评价网络的输入为全局任务状态,输出为策略评价值。
81、本发明的进一步改进在于,所述建立端到端的水下多无人平台协同跟踪框架之后,端到端水下多无人平台协同跟踪的流程具体包括:
82、(1)初始化:初始化调度任务执行网络参数θ、数据融合任务执行网络参数θf、全局评价网络参数θc;初始化折扣因子λ、γ以及迭代次数ω;初始化调度任务状态空间ssc、数据融合任务状态空间sf和全局任务状态空间stotal跟踪任务相关参数;
83、(2)动作更新:分别对调度任务、数据融合任务中的执行网络输入当前时刻的调度状态数据融合状态以及前一时刻选取的旧动作生成当前时刻的新动作
84、(3)奖励更新:通过当前时刻的新动作,更新调度任务、数据融合任务的奖励;
85、(4)全局评价更新:通过输入当前时刻的全局状态调度任务动作πsc、数据融合策略πf,分别更新调度任务策略的评价值、数据融合任务策略的评价值;
86、(5)执行网络更新:利用梯度下降法分别求解调度任务执行网络损失函数和数据融合任务执行网络损失函数,以更新执行网络参数,从而实现策略更新;其中,
87、
88、(6)全局评价网络更新:全局利用梯度下降法求解全局评价函数损失函数,以实现损失最小化,从而实现全局评价网络参数更新;其中,
89、
90、(7)重复步骤(2)至步骤(6)ω次,完成端到端水下多无人平台协同跟踪。
91、本发明第二方面,提供一种基于深度强化学习的水下多无人平台协同跟踪系统,包括:
92、第一算法构建模块,用于利用强化学习将复杂水下环境下的水下多无人平台动态调度问题建模为马尔可夫决策过程模型,并在奖励函数的设计中结合能效优化目标函数和基于虚拟数据法的跟踪性能评估函数,建立获得端到端的水下多无人平台调度算法;其中,所述端到端的水下多无人平台调度算法包括调度任务状态空间、调度任务动作空间、调度任务奖励函数以及多平台调度策略;
93、第二算法构建模块,用于利用强化学习将多源动态信息下的水下多无人平台数据融合问题建模为马尔可夫决策过程模型,并在奖励函数的设计中结合基于虚拟数据法的数据融合性能评估函数,建立获得端到端的水下多无人平台调度算法;其中,所述端到端的水下多无人平台调度算法包括数据融合任务状态空间、数据融合任务动作空间、数据融合任务奖励函数及多平台数据融合策略;
94、跟踪模块,用于结合端到端的水下多无人平台调度算法以及端到端的水下多无人平台调度算法建立过程中建模的马尔可夫决策过程模型,引入深度强化学习中的mappo算法同时对多平台调度策略、多平台数据融合策略进行学习,通过环境的反馈评估当前策略的有效性,最终确定当前环境下的最优跟踪策略。
95、与现有技术相比,本发明具有以下有益效果:
96、本发明具体提供了一种基于深度强化学习的水下多无人平台协同跟踪方案,构建了新型端到端水下多无人平台协同跟踪框架,能够实现水下多无人平台在多源动态信息下的高能效目标跟踪,能够在有效降低系统能耗的同时显著提升系统的任务执行效率和协同跟踪性能,可提升水下多无人平台在复杂水下目标跟踪环境中的应用性能和系统效率。具体解释性地,本发明技术方案中,利用强化学习方法建立端到端的水下多无人平台调度算法,可以有效解决传统调度算法难以解决的动态调度问题,在缺乏先验知识的情况下,实现系统动态适应水下环境,优化了系统资源分配和系统任务执行效率,提升了能效比;利用强化学习方法建立端到端的水下多无人平台数据融合算法,可以有效解决在传统数据融合方法难以解决的水下多源动态信息数据融合问题,优化了系统在复杂水下环境下的数据融合性能和执行效率,能够提升水下多无人平台系统的目标跟踪精度;引入深度强化学习构建的水下多无人平台协同跟踪算法,可以有效解决传统步进式的水下目标跟踪算法难以解决的复杂多任务问题,通过端到端的框架优化了整个协同跟踪流程,将协同跟踪流程中的多个重要环节,包括多平台调度、多平台数据融合等整合进一个框架,使得系统具备同时处理调度、融合等多重复杂任务的能力,提升了水下多无人平台的协同跟踪效率。
本文地址:https://www.jishuxx.com/zhuanli/20241021/320315.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。