一种基于滑动窗口的污染物时序数据异常识别方法及系统与流程
- 国知局
- 2024-10-21 15:09:39
本发明涉及环境监测,具体为一种基于滑动窗口的污染物时序数据异常识别方法及系统。
背景技术:
1、污染源排污异常识别对于发现企业可能存在的数据篡改和数据造假的行为具有重要意义。目前,常见的污染源排污异常识别技术主要分为传统统计方法和先进的数据分析技术两大类。传统统计方法依赖于历史数据的基本统计特征,如均值、方差、分位数等,来检测异常排放情况。这些方法相对简单,适用于一些基本的异常情况,但对于复杂的异常模式可能不够敏感,容易产生误报或漏报。与传统方法相比,先进的数据分析技术在污染源排污异常识别中表现出更高的精度和灵敏度。这些技术包括机器学习方法、深度学习方法和时间序列分析方法。机器学习方法可以从历史数据中学习异常排放的模式,并根据新数据进行识别。深度学习模型如神经网络能够捕捉时间序列数据中的异常行为,而时间序列分析方法则专注于排放数据的时间特性,用于检测季节性或周期性的排放异常。无论使用哪种方法,污染源排污异常识别都需要高质量的数据作为输入,以便模型可以准确地识别异常情况。此外,模型的持续更新和改进也是保持其识别性能的关键,以适应不断变化的排放情况和新的异常模式。
2、但现有技术存在如下问题:
3、目前用电数据由于监测点位多、数据发送频率高,造成数据量极大,处理困难;同时,由于用电和污染物排放系统建设行为割裂,多个系统无法互通,无法建立污染物排放口与用电监测设备之间的联系;且不同企业间监测手段、设备、排放物限值均有不同,企业名称未能做到统一,使得数据融合较为困难,导致前期数据处理要求高、工作量大;由于数据不全、不统一等问题,多源数据应用困难。
技术实现思路
1、基于此,有必要针对现有异常检测技术依赖历史数据、数据不统一等造成处理量大且困难的问题,提供一种基于滑动窗口的污染物时序数据异常识别方法及系统。
2、为实现上述目的,本发明采用了以下技术方案:
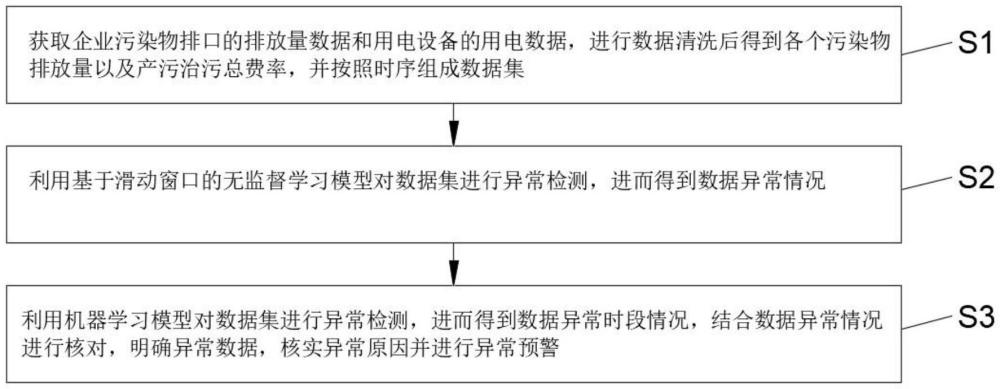
3、一种基于滑动窗口的污染物时序数据异常识别方法,包括以下步骤:
4、s1.获取企业污染物排口的排放量数据和用电设备的用电数据,进行数据清洗后得到各个污染物排放量以及产污治污总费率,并按照时序组成数据集;
5、s2.利用基于滑动窗口的无监督学习方式对数据集进行异常检测,进而得到数据异常情况;异常检测的具体步骤如下:
6、s21.从数据集中选取d天的数据作为判断窗口,将d天的数据以预设的时间节点作为分割点分为在先数据d1和在后数据d2;
7、s22.对在先数据d1中的产污治污总费率进行平均值计算得到费率平均值qavgd1,对在先数据d1中超过c种的关键污染物排放量进行平均值计算得到排放量平均值pavgd1,将费率平均值qavgd1和排放量平均值pavgd1与在后数据d2中每天产污治污总费率qd2以及每天超过c种的关键污染物排放量pd2进行对比,根据对比结果作出如下判断:
8、若qd2≥qavgd1*n1,pd2<pavgd1*n2;则判定窗口内的数据存在异常;
9、其中,c为低值污染物种类限制常数,n1、n2为低值限制倍率常数;
10、s3.利用机器学习模型对数据集进行异常检测,进而得到数据异常时段情况,结合步骤s2中数据异常情况进行核对,明确异常数据,核实异常原因并进行异常预警。
11、进一步的,利用机器学习中的随机森林模型对数据集进行异常预测,具体步骤如下:
12、通过bootstrap抽样从数据集中抽样生成多个不同的训练子集,进而构建t颗决策树,得到具有t颗决策树的随机森林模型;
13、从数据集中随机选择m个特征输入至具有t颗决策树的随机森林模型中进行预测,得到随机森林模型的预测值
14、
15、其中,yj(m)是第j棵决策树的预测值,j≤t。
16、进一步的,步骤s1中,对企业污染物排口的排放量数据和用电设备的用电数据进行数据清洗后得到各个污染物排放量以及产污治污总费率,并按照时序组成数据集的具体步骤如下:
17、对同企业同天同一污染物所对应的污染物排口的平均排放量进行求和,得到该企业同一污染物的单日排放量,将预设周期内的同一污染物的单日排放量按时序汇总成该污染物排放量,同理计算得到各污染物的排放量;
18、对同企业同日用于产污治污的用电设备的费率进行求和得到单日产污治污总费率,将预设周期内的单日产污治污总费率按时序汇总成该企业的产污治污总费率;
19、按照企业名称将各个污染物排放量及产污治污总费率作为列属性对数据进行整合,并剔除空值,得到数据集。
20、进一步的,所述污染物包括二氧化硫、氮氧化物、非甲烷总烃,还包括其它废气流量。
21、进一步的,步骤s2中,利用基于滑动窗口的无监督学习方式对数据集进行异常检测前,对数据集进行单独/综合时序可视化分析,初步识别异常数据并标记。
22、本发明还涉及一种基于滑动窗口的污染物时序数据异常识别系统,其应用前述的基于滑动窗口的污染物时序数据异常识别方法,其包括数据采集清洗模块、第一异常检测模块、第二异常检测模块、异常预警模块。
23、数据采集清洗模块用于获取企业污染物排口的排放量数据和用电设备的用电数据,进行数据清洗后得到各个污染物排放量以及产污治污总费率,并按照时序组成数据集;
24、第一异常检测模块用于利用基于滑动窗口的无监督学习方式对数据集进行异常检测,进而得到数据异常情况;
25、第二异常检测模块用于利用机器学习模型对数据集进行异常检测,进而得到数据异常情况;
26、异常预警模块用于结合第一异常检测模块和第二异常检测模块的数据异常情况进行核对,明确异常数据,核实异常原因并进行异常预警。
27、与现有技术相比,本发明的有益效果包括:
28、1、本发明将基于滑动窗口的无监督学习和机器学习方法进行结合,挖掘用电费率和污染物排放数据间关联关系,利用数理统计相关算法,在不依赖于历史异常规则数据库的情况下,根据企业需求的特定异常状态进行针对性分析判断,从而更加精准地预测企业排污行为;
29、2、本发明采用随机森林模型进行异常时段判断,提高了识别模型的泛化能力和精准度。
技术特征:1.一种基于滑动窗口的污染物时序数据异常识别方法,其特征在于,其包括以下步骤:
2.根据权利要求1所述的基于滑动窗口的污染物时序数据异常识别方法,其特征在于,步骤s3中,利用机器学习中的随机森林模型对数据集进行异常预测。
3.根据权利要求2所述的基于滑动窗口的污染物时序数据异常识别方法,其特征在于,利用机器学习中的随机森林模型对数据集进行异常预测的具体步骤如下:
4.根据权利要求1所述的基于滑动窗口的污染物时序数据异常识别方法,其特征在于,步骤s1中,对企业污染物排口的排放量数据和用电设备的用电数据进行数据清洗后得到各个污染物排放量以及产污治污总费率,并按照时序组成数据集的具体步骤如下:
5.根据权利要求4所述的基于滑动窗口的污染物时序数据异常识别方法,其特征在于,所述污染物包括二氧化硫、氮氧化物、非甲烷总烃。
6.根据权利要求2所述的基于滑动窗口的污染物时序数据异常识别方法,其特征在于,步骤s2中,利用基于滑动窗口的无监督学习方式对数据集进行异常检测前,对数据集进行单独/综合时序可视化分析,初步识别异常数据并标记。
7.一种基于滑动窗口的污染物时序数据异常识别系统,其应用如权利要求1-6中任意一项所述的基于滑动窗口的污染物时序数据异常识别方法,其特征在于,其包括:
技术总结本发明提供一种基于滑动窗口的污染物时序数据异常识别方法及系统。该方法包括以下步骤:S1.获取企业污染物排口的排放量数据和用电设备的用电数据,进行数据清洗后得到各个污染物排放量以及产污治污总费率,并组成数据集;S2.利用基于滑动窗口的无监督学习方式对数据集进行异常检测,进而得到数据异常情况;S3.利用机器学习模型对数据集进行异常检测,进而得到数据异常情况,结合步骤S2中数据异常情况进行核对,核实异常原因并进行异常预警。本发明将基于滑动窗口的无监督学习和机器学习方法进行结合,挖掘用电费率和污染物排放数据间关联关系,在不依赖于历史异常规则数据库的情况下,根据企业需求的特定异常状态进行针对性分析判断。技术研发人员:陆晓波,武诺,周培生,宋佶岭,许可,唐沛豪,金涛,王丰羽,陈柯吟,张慧芬,李彤,王克气,沈怡秀,徐向凯,韦余娟受保护的技术使用者:江苏省苏力环境科技有限责任公司技术研发日:技术公布日:2024/10/17本文地址:https://www.jishuxx.com/zhuanli/20241021/320691.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。