一种基于医疗健康数据的多源知识图谱构建方法
- 国知局
- 2024-10-21 15:14:10
本发明属于知识图谱构建领域,具体涉及一种基于医疗健康数据的多源知识图谱构建方法。
背景技术:
1、知识图谱是结构化的语义知识库,是使用图模型来描述世间万物联系的一种方法,知识图谱由节点和边构成,节点一般为实体,例如人物或者组织机构;边可以是属性或者实体之间的关系。医疗健康领域具有庞大的行业知识,构建基于医疗健康领域数据的行业知识图谱,有助于推动行业认知智能化应用的发展。
2、知识图谱的构建通常包括以下几个环节:知识建模、知识存储、知识抽取、知识融合、知识计算、知识应用。首先由领域专家设计构建行业知识图谱的schema(本体)。针对构建知识图谱设计底层的存储方式,完成各类知识的存储。然后使用nlp技术(自然语言处理natural language processing,nlp)从各类数据源中抽取出实体、属性,以及实体之间的关系。接着对于从各种数据源中抽取得到的知识进行融合,进行实体对齐,属性对齐等工作。经过融合的新知识通过质量评估之后即可加入到知识库中。
3、构建行业领域的知识图谱,schema构建工作通常是非常影响项目快速推进的环节之一。在基于知识图谱的应用在各类行业中落地的进程中,大部分行业没有接触过知识图谱,因而没有沉淀行业内的知识schema用以构建行业图谱。同时由于知识图谱的概念较新,行业业务专家需要一个从理解到熟练构建schema的过程,而此过程往往还需要算法人员的频繁介入。如此在一个新的行业中落地图谱相关的应用时,构建一个完整的schema往往需要消耗周级甚至月级的时间单位。
4、此外,现有的实体对齐算法比较有代表性的有基于网络的方法和基于迭代的方法。基于网络的方法主要思想是使用实体之间的网络结构作为实体融合的基础。确定两个实体是否指向同一个对象不仅取决于实体本身,还需要通过判断其关联节点的相似程度。其中一种具有代表性的算法为基于图相似度传播的方法。其主要过程是根据节点周围网络结构的匹配程度,在多个实体图中映射实体的过程,即当一个节点匹配到一个节点的时候,两者的邻居节点也应当匹配上。
5、目前还有基于知识图谱表示学习的实体对齐方法。其主要包括三个模块,分别是嵌入模块、交互模块、对齐模块。嵌入模块目前主要有三种方法,一种是利用transe及其改进系列进行关系结构信息嵌入;一种是使用gnn构建邻接关系图进行嵌入;一种是使用gnn的改进模型gcn进行结构信息嵌入。嵌入模块利用的信息主要有两种,即结构信息和属性信息。交互模块的作用主要是将两个不同的知识图谱映射到同一向量空间,使得向量的计算在同一空间。目前联系两个知识图谱的桥梁主要是预对齐的实体对,通过预对齐的实体对在不同向量空间的转换和校准,统一两个知识图谱。对齐模块的作用主要是根据已经嵌入的实体向量来计算距离,此外,还能通过一些推理策略选择待对齐的实体。
6、综上所述,现有技术中,构建基于医疗健康数据的多源知识图谱需要很多时间,周期很长,无法快速进行实施。
技术实现思路
1、针对现有技术的不足,本技术提出一种基于医疗健康数据的多源知识图谱构建方法,包括:
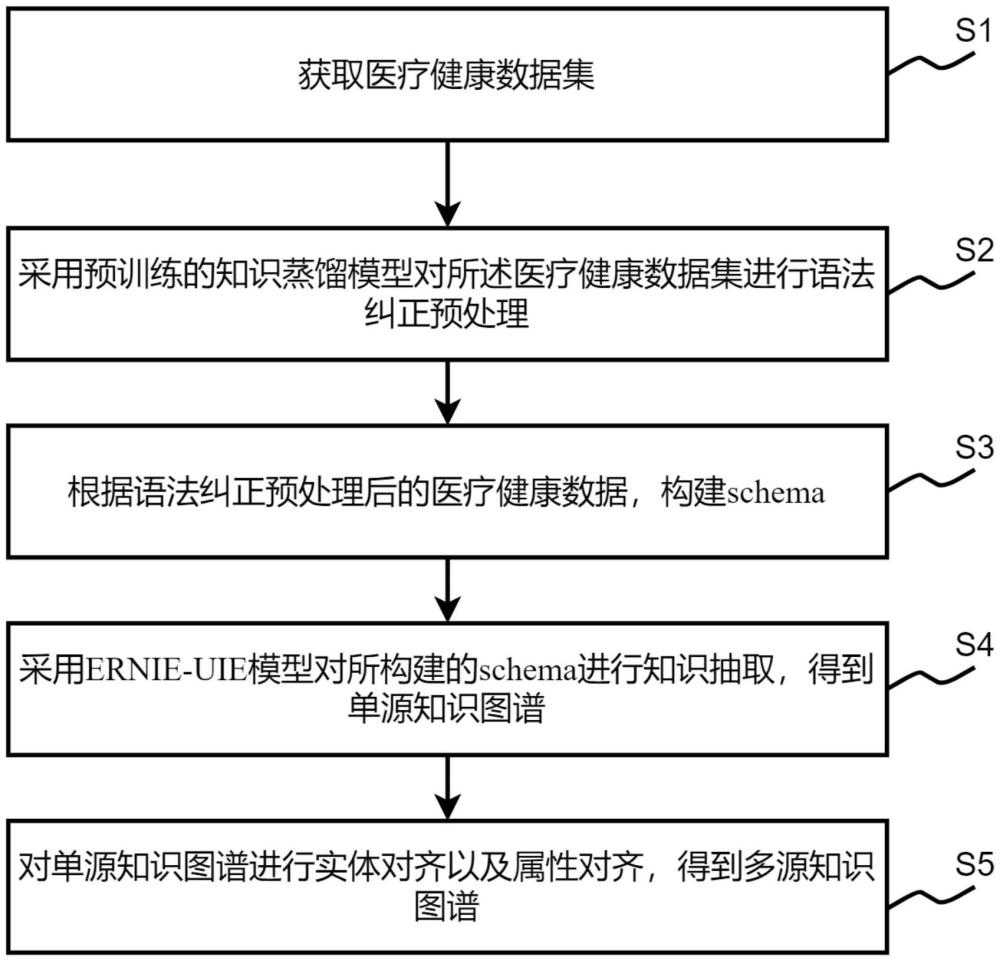
2、获取医疗健康数据集;
3、采用预训练的知识蒸馏模型对所述医疗健康数据集进行语法纠正预处理;
4、根据语法纠正预处理后的医疗健康数据,构建schema;
5、采用ernie-uie模型对所构建的schema进行知识抽取,得到单源知识图谱;
6、对单源知识图谱进行实体对齐以及属性对齐,得到多源知识图谱。
7、所述获取医疗健康数据集包括:
8、爬虫技术提取html网页的非结构化数据;
9、使用paddleocr识别pdf文本提取文本内容;
10、将所述非结构化数据与文本内容组成医疗健康数据集。
11、所述预训练的知识蒸馏模型,包括:采用chatgpt4作为教师模型,chatglm2-6b作为学生模型训练知识蒸馏模型,得到预训练的知识蒸馏模型。
12、所述根据语法纠正预处理后的医疗健康数据,构建schema,包括:
13、采用lac分词库对语法纠正预处理后的医疗健康数据进行分词处理,并抽取动词短语,将所有抽取到的动词短语组成动词集;
14、采用词频-逆文档频率算法分析所有抽取到的动词短语,抽取到关键动词,将所有抽取到的关键动词组成关键动词集;
15、根据语法纠正预处理后的医疗健康数据中的单篇文本,采用word2vec模型构建动词集与关键动词集的词向量;
16、根据词向量之间的相似度,筛选得到实体关系子集;
17、将单篇文本中的实体关系子集以及预定义的实体属性构成schema。
18、采用ernie-uie模型对所构建的schema进行知识抽取,得到单源知识图谱,包括:
19、采用ernie-uie模型对于遍历所有schema进行实体识别、事件抽取、时间元素抽取,得到结构化的知识;
20、根据所述结构化的知识,得到单源知识图谱,所述单源知识图谱包括:关系三元组以及属性三元组。
21、所述对单源知识图谱进行实体对齐以及属性对齐,得到多源知识图谱,包括:
22、采用jape算法对系三元组以及属性三元组进行实体对齐;
23、采用word2vec语义相似度对属性三元组进行属性对齐。
24、所述采用jape算法对系三元组以及属性三元组进行实体对齐,包括:
25、假设第一知识图谱与第二知识图谱是已对齐的实体对;
26、根据第一知识图谱与第二知识图谱的关系三元组,得到结构嵌入;
27、根据第一知识图谱与第二知识图谱的属性三元组,得到属性嵌入;
28、根据所述属性嵌入计算实体之间的相似度,得到相似度矩阵;
29、将相似度矩阵与结构嵌入结合,得到最终的嵌入;
30、根据所述最终的嵌入进行对齐,得到实体对齐后结果。
31、所述采用word2vec语义相似度对属性三元组进行属性对齐,包括:
32、步骤s521:采用word2vec语义相似度计算属性三元组中每个属性的词向量;
33、步骤s522:根据所述词向量,计算不同属性的相似属性;
34、步骤s523:若所述相似属性存在于医疗健康数据集中不同数据源中,并且相似属性的cosine距离大于设定值,则此时不同属性之间已对齐,输出属性对齐后结果;否则执行步骤s524;
35、步骤s524:对不同数据源中的属性进行属性融合,构建融合的属性关系集合,并以融合的属性关系集合作为属性对齐后结果。
36、有益效果:
37、本技术提出一种基于医疗健康数据的多源知识图谱构建方法及系统,本技术提出医疗健康领域半自动化构建schema的解决办法,能够缩短多源知识图谱的创建周期,能够满足快速进行实施的需求。本技术还解决了多源数据知识图谱融合构建中的实体对齐问题,多源数据中对于同一对象往往存在重叠或互补的知识,实体对齐的目标为将描述相同的真实世界的对象进行统一。早期的实体对齐工作一般使用手工标注方法,但是随着知识库规模变大,处理起来越来越麻烦,本技术实现了从知识库中自动挖掘等价实体对构建知识库。
本文地址:https://www.jishuxx.com/zhuanli/20241021/320959.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表