基于自适应传播模式的社交网络节点重要程度排名方法
- 国知局
- 2024-10-21 15:12:52
本发明涉及信息,尤其涉及一种基于自适应传播模式的社交网络节点重要程度排名方法。
背景技术:
1、网络中的传播行为作为网络分析的重要组成部分,其商业潜力的研究和应用具有极高的价值。理解和分析这些社交网络中的复杂传播动态对于优化信息传播策略、防控错误信息的扩散、以及增强社会公共健康至关重要。
2、真实社交网络的传播过程非常复杂,信息具有衰减效应而且用户在社交网络上有着自己的独特偏好性,对于信息有自己的传播属性与偏向性。而信息级联可以被用来概述信息在社交网络上的传播,它考虑个体之间的传播决策、观点、属性偏好,模拟信息传播舆论趋势的形成,可以更加全面地自适应刻画信息的传播行为。现研究主要集中于对传播级联序列进行表示分析,而往往忽略了转发节点在传播过程中的作用和影响,同时节点特征难以表示为序列的形式。此外,用户的个性化属性和偏好在传播模式学习识别中起着关键作用,但目前的方法很少将这些因素纳入考量范围。
技术实现思路
1、本发明提供了一种基于自适应传播模式的社交网络节点重要程度排名方法,本发明可以在未知传播方式的情况下,在各种社交网络平台上基于用户的传播转发行为进行自适应学习,以便获得更精确地挖掘社交网络上的潜在重要用户,并进一步服务于传播策略的制定。
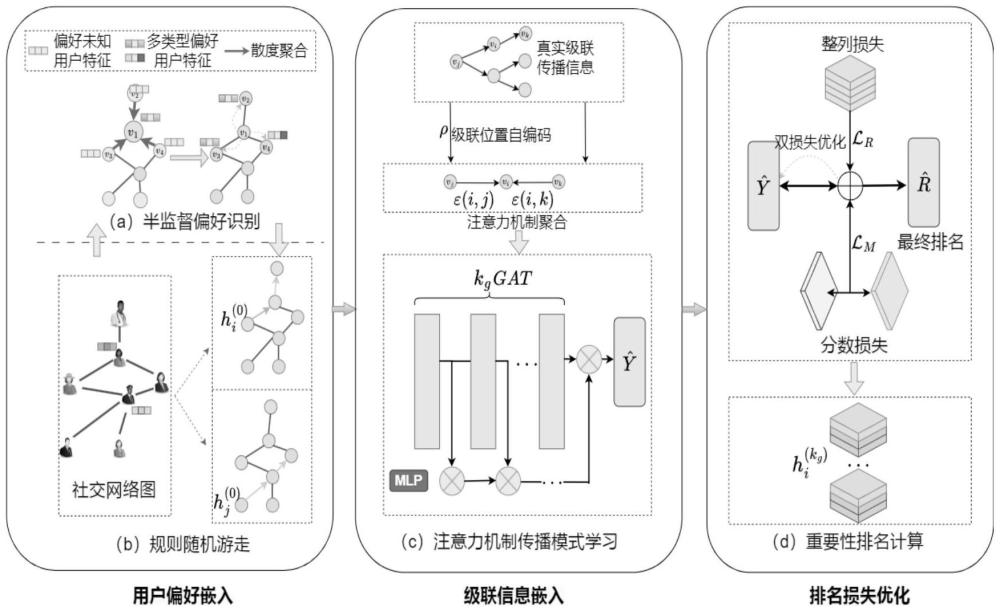
2、一种基于自适应传播模式的社交网络节点重要程度排名方法,所述方法包括:
3、利用基于相似性散度的方法对用户节点的偏好标签进行补充预测;
4、通过改进的随机游走算法与级联位置自编码方法,通过多头注意力机制对节点进行属性偏好与级联信息的联合嵌入;
5、根据回归损失和整列排名损失的双重优化策略来细化算法的节点排序性能。
6、其中,对于社交网络g,其中v和e分别表示g中用户节点和用户间好友关系的集合。具体来说,本发明考虑信息级联c,为应对社交网络信息级联传播的不确定性,将用户偏好属性与级联特征进行节点特征联合学习。
7、其中,基于半监督的节点的偏好标签预测:利用已获得的用户好友关系vij和转发级联消息c,计算节点偏好属性分类可以用于后续任务。本发明利用两层图卷积神经网络(gcn)进行用户偏好标签传播计算:
8、
9、其中为w(0)和w(1)分别为输入隐藏层和输出隐藏层的参数。在此之上,本发明设计了基于相似性归一化的jensen-shannon散度方法优化标签传播:其中和表示节点vi和vj的特征,x为社交网络的节点特征矩阵,a为邻接矩阵,σ为relu激活函数,softmax为向量的权重计算归一化函数,为归一化处理的度矩阵,用于构造对称归一化的拉普拉斯算子。
10、对于节点vi和vj:
11、
12、散度jsd相对一对节点是对称的,具体来说jsd(x|y)=jsd(y|x)。m为偏好类型数量,v和y均为节点特征,将用于对比的两个节点特征设为x和y,对于节点vi,模型的目的是最小化其与邻居节点的jsd:
13、
14、然后对全图节点,进行节点间的散度最小化,并将其作为损失函数来对半监督模型的无标签部分数据进行训练:
15、
16、
17、其中,表示节点vi的邻居个数,如果用户的好友或关注的人越少,越容易受好友的偏好影响。对于分类层面,使用交叉熵作为损失函数,则分类损失函数和最终半监督标签学习的损失函数分别为:
18、
19、
20、其中λ1可以调节散度损失函数在半监督偏好分类模块的权重,n为节点数量,eij为连接节点vi和vj的边,e为社交网络边的集合,l为损失函数标记,j为对应种类特征的特征标量,一共m种。
21、其中,对节点的偏好信息与级联位置信息进行联合特征嵌入包括:
22、a)利用计算的标签偏好信息,将节点的属性偏好信息嵌入到节点基于同属性级联的随机游走步骤中。级联的传播动态是在全图上进行的,随机游走可以在全图范围上进行并获得大量的全局结构信息。通过节点的属性偏好调节随机游走节点间的游走概率,可以进一步规范游走路径并把级联的信息嵌入到节点的特征矩阵中,节点偏好属性的邻居节点未标准化转移条件概率可以表示为βδγ,
23、
24、其中,π是原node2vec随机游走的转移概率,sim(u,v)表示节点u和v是否属性一致(属性相同为1,不同为0),γ是一个大于1的数,用于调节游走到属性不一致节点的概率,δ是另一个参数,用于鼓励从偏好属性不一致节点返回到与初始起点v0偏好属性一致的节点的转移概率,x为随机游走过程的现节点,sim()表示判断现节点是否与起始节点偏好特征一致。
25、b)利用级联的时间特性,拟合级联的变化动态,模型模型学习到级联序列。本发明利用图注意力模型(gat)模型学习得到注意力权重,将节点在级联中的位置作为特征拼接到节点的向量表示中,可以让gat模型根据节点在级联中的信息调整邻居聚合权重。级联位置编码可以表示为:
26、
27、其中,pv是节点在级联中的位置,j为表示编码检索维度,dmodel为模型向量维度,通过使用三角函数来对位置信息编码,捕获序列中的位置关系。gat模型的注意力权重可以表示为:
28、
29、其中a为可学习的权重向量,w,wp是可学习的特征转换矩阵,||表示拼接操作,εc(i,j)为节点vi对于邻居vj的相对位置编码,计算方式为ε(i,j)=ρc(i)-ρc(j),vj∈c,leakyrelu为改进的relu激活函数,c表示一条级联,有序节点集合,ni为节点vi的邻居集合,vk为ni的元素,ρc为对应级联c的绝对位置编码。hi,hj∈rf为节点vi,vj的特征向量,rf表示f维实数特征向量,首层的特征向量为上一节随机游走获得的向量。通过对邻居节点注意力进行softmax处理,获得对应的权重并通过αij对邻居进行聚合。
30、每一层的聚合操作可以表示为:
31、
32、本发明将多头注意力机制引入到gat模型中来,使用k个注意力头来表示节点特征向量:
33、
34、同时对最后一层使用平均操作以匹配目标特征大小:
35、
36、σ为relu激活函数,k为注意力头集合。
37、其中,使用回归损失和整列排名损失的双重优化策略,进而获得更为准确的节点重要性分数值与排名结果:(1)为了减轻图注意力模型层数对模型性能的过平滑影响,在对节点特征进行下一层输入时,选取本层节点特征进行一次mlp操作,特征进入下一层图注意力模型后重复此操作:
38、
39、
40、其中模型最终获得的节点重要性分数为模型通过输入的真值i去训练;因为衡量指标为节点的重要性分数与排名,针对重要性分数回归值与整列相对排名两个视角,将优化过程扩展为两个损失函数,包括基于真值数值的节点分数回归mse损失和基于真值相对排名的排名损失为经过1层注意力层后经过激活函数得到的节点vi的特征,为节点vi的重要性分数,b为偏移权重;
41、(2)对于重要性分数的回归操作,使用mse作为损失函数:
42、
43、其中是一组通过数据集计算出重要性分数真值的节点的集合;
44、(3)整表排序的整列损失函数表示为:
45、
46、其中,指根据节点vi采样的一组有重要性分数真值的节点组成的集合,softmax处理的ij是节点vj位于首位排名的近似概率分布,指根据节点vi采样的一组有重要性分数真值的节点组成的集合,ik是集合中节点vk位于首位排名的近似概率分布;
47、(4)通过最小化损失函数,鼓励模型提高正确排序项目的概率,从而改善整个列表的排名质量,最终整个模型的排名学习模块的损失函数表示为:
48、
49、其中λ2,λ3用于调节模型优化的细化粒度。
50、本发明提供的技术方案的有益效果是:
51、1、本发明提出的模型可以通过机器学习的方法,利用级联的强大表示能力自适应学习复杂传播模式,有更强的性能来应对真实社交网络上的复杂传播问题;
52、2、本发明针对用户个性化偏好标签难以获取的问题,提出了一种基于半监督的用户偏好分类识别方法,并引入用户相似性散度,进一步优化了识别结果;
53、3、本发明设计了一种基于用户级联序列的相对位置编码策略,通过将其与注意力机制结合,简化用户节点级联序列的特征嵌入,克服了传播级联序列结构难以表示的问题。
54、4、本发明利用回归损失和整列排名损失进行算法双损失优化,获得更为精确的社交网络用户节点重要性分数结果与排名结果。
本文地址:https://www.jishuxx.com/zhuanli/20241021/320881.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表