基于多视图采样和渐进式生成的深度智能3D重建方法
- 国知局
- 2024-10-21 15:27:43
本发明涉及计算机视觉,尤其是指一种基于多视图采样和渐进式生成的深度智能3d重建方法。
背景技术:
1、如今,3d模型已经在许多制造过程和产品设计中占据了核心位置。这一趋势催生了对3d内容的巨大需求。传统上,3d内容的生成是通过设计师使用计算机辅助设计(cad)技术手动实现的,这一过程需要设计师具备高度的技能和专业知识,必须熟练掌握cad软件的命令和策略,能够将复杂的形状分解为一系列顺序命令。这不仅具有挑战性,而且是一个劳动密集型和耗时的过程。cad技术固有的局限性突显了对更快、更用户友好的3d建模选项的替代方法的需求。
2、在现有的替代方法中,基于手绘图的3d建模近年来成为一种有前途的解决方案。手绘图作为一种重要工具,无论是在专业设计还是日常生活中,都提供了表达想法的直观手段。大多数现有建模方法要么需要从多个视图绘制精确的线条图,要么需要使用具有策略知识的分步工作流程,这对用户来说并不友好,而且仍然很耗时。其他建模方法则使用模板原语或基于检索的方法,但这些方法缺乏可定制性。
3、为了实现快速直观的三维建模目标,现有的研究方向是使用单个手绘图作为输入,生成完整的高保真三维模型。由于手绘图的稀疏性和模糊性,这是一项具有挑战性的任务。手绘图只有一个视图,是稀疏且抽象的,绘制时缺乏精细的边界信息,最关键的是缺乏用于深度估计的纹理信息,这导致模型在学习3d形状时存在大量的不确定性。抽象的边界也使其难以解释,因为相同的一组笔画在3d世界中可能有不同的解释,从而导致歧义。在工业应用中,手绘图的残缺性也是一大常见问题。这种残缺手绘图可能由于绘制不完整、细节缺失或输入不清晰而导致生成的3d模型质量不理想的问题。
技术实现思路
1、为此,本发明所要解决的技术问题在于克服现有技术中基于残缺手绘图生成3d模型的质量较低的问题。
2、为解决上述技术问题,本发明提供了一种基于多视图采样和渐进式生成的深度智能3d重建方法,包括:
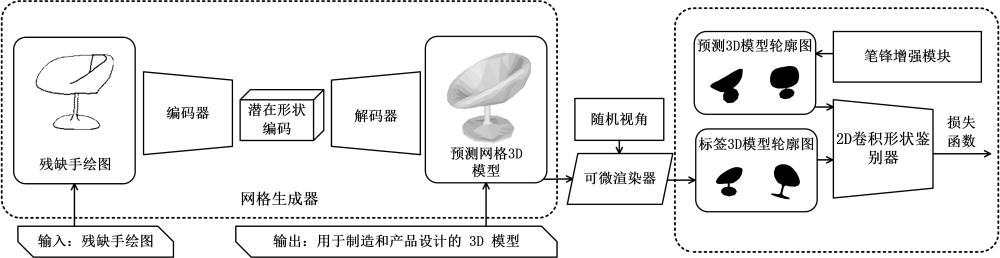
3、将数据集中残缺手绘图输入网格生成器,得到预测网格3d模型;所述数据集包括残缺手绘图及其标签网格3d模型;
4、将预测网格3d模型和标签网格3d模型输入可微渲染器,得到预测3d模型轮廓图和标签3d模型轮廓图;
5、将预测3d模型轮廓图和标签3d模型轮廓图输入至2d卷积形状鉴别器,分别得到预测3d模型轮廓图和标签3d模型轮廓图的评估值;
6、基于预测3d模型轮廓图和标签3d模型轮廓图构建多尺度miou损失,基于预测3d模型轮廓图和标签3d模型轮廓图的评估值构建结构感知gan损失,再利用多尺度miou损失、结构感知gan损失和平坦损失和拉普拉斯平滑损失构建损失函数,对网格生成器的参数进行优化;
7、利用经过训练的网格生成器对残缺手绘图进行3d建模,得到目标网格3d模型。
8、优选地,所述网格生成器采用编码器-解码器架构,编码器采用resnet-18架构,解码器采用级联上采样块。
9、优选地,所述将的预测网格3d模型和标签网格3d模型输入可微渲染器,得到预测3d模型轮廓图和标签3d模型轮廓图,包括:
10、将手绘图的预测网格3d模型和标签网格3d模型输入可微渲染器,并随机抽样n个相机姿态,得到相机姿势分布,利用相机姿势分布得到n个不同视角的预测3d模型轮廓图和标签3d模型轮廓图。
11、优选地,所述预测3d模型轮廓图输入至2d卷积形状鉴别器之前,经过笔锋增强模块,对预测3d模型轮廓图进行特征增强。
12、优选地,所述数据集的构建包括:
13、从shapenet数据库中下载包含各种网格3d模型的合成数据,并对网格3d模型进行标准化处理,确保大小和格式一致;
14、利用网格3d模型渲染生成网格3d模型对应的完整手绘图,并使用图像编辑工具手动删除完整手绘图的一部分,生成初步残缺手绘图样本;
15、基于初步残缺手绘图样本,利用图像处理库或图像生成模型生成残缺手绘图样本,并进行采样校验,移除不符合要求的残缺手绘图样本;
16、将残缺手绘图样本及其对应的网格3d模型以标准格式保存,得到数据集。
17、优选地,损失函数的公式为:
18、;
19、其中,表示第一损失函数,表示多尺度miou损失,表示平坦损失和拉普拉斯平滑损失,表示结构感知gan损失,表示结构感知gan损失的权重参数。
20、优选地,所述数据集的构建还包括:
21、从shapenet数据库中下载包含各种网格3d模型的合成数据,并对网格3d模型进行标准化处理,确保大小和格式一致;利用网格3d模型渲染生成网格3d模型对应的完整手绘图;
22、对完整手绘图添加噪声,得到噪声手绘图样本,包括:
23、设置噪声的强度和噪声区域的数量,并对每个噪声区域随机选择局部噪声的中心点和局部噪声的半径,生成局部噪声区域;
24、在每个局部噪区域随机进行模糊操作或锐化操作,并将每个局部噪声区域使用掩码覆盖到完整手绘图上,得到噪声手绘图样本;
25、将完整手绘图、噪声手绘图样本及其对应的网格3d模型以标准格式保存,得到数据集。
26、优选地,所述将数据集中手绘图输入网格生成器,得到预测网格3d模型,包括:
27、噪声手绘图在网格生成器中生成潜在视图编码和潜在形状编码,将潜在视图编码输入至视点解码器,得到预测视点信息;网格生成器基于预测视点信息和潜在形状生成预测网格3d模型。
28、优选地,损失函数还包括视点预测损失和去噪损失,公式为:
29、;
30、其中,表示第二损失函数,表示多尺度miou损失,表示平坦损失和拉普拉斯平滑损失,表示结构感知gan损失,表示结构感知gan损失的权重参数,表示视点预测损失,表示视点预测损失的权重参数,表示去噪损失,表示去噪损失的权重参数;
31、所述视点预测损失的公式为:
32、;
33、其中,表示真实视点信息,表示预测视点信息;
34、去噪损失的公式为:
35、;
36、其中,表示完整手绘图,表示预测3d模型轮廓图,和分别表示完整手绘图的轮廓图和预测3d模型轮廓图的像素点。
37、优选地,所述基于预测3d模型轮廓图和标签3d模型轮廓图构建多尺度miou损失,包括:
38、将预测3d模型轮廓图和标签3d模型轮廓图分别进行多次下采样,得到不同分辨率的预测3d模型轮廓图和标签3d模型轮廓图组成的多尺度轮廓图对,量化每个多尺度轮廓图对中预测3d模型轮廓图和标签3d模型轮廓图之间的相似性,公式为:
39、;
40、其中,表示多尺度轮廓图对的总对数,表示第i个多尺度轮廓图对的超参数,用于平衡不同分辨率轮廓图损失之间的权重,表示第i个多尺度轮廓图对的损失;
41、;
42、其中,表示第i个多尺度轮廓图对中的预测3d模型轮廓图,表示第i个多尺度轮廓图对中的标签3d模型轮廓图;
43、所述基于预测3d模型轮廓图和标签3d模型轮廓图的评估值构建结构感知gan损失,公式为:
44、;
45、;
46、其中,表示相机姿态,表示相机姿势分布,表示相机采样视角,表示相机采样视角分布,表示相机采样视角和相机姿态的期望值;表示2d卷积形状鉴别器,表示可微渲染器,表示标签网格3d模型,表示预测网格3d模型,表示2d卷积形状鉴别器输出的预测3d模型轮廓图的评估值,表示2d卷积形状鉴别器输出的标签3d模型轮廓图的评估值,表示对数损失函数,表示对数损失函数的输入。
47、本发明的上述技术方案相比现有技术具有以下有益效果:
48、本发明所述的一种基于多视图采样和渐进式生成的深度智能3d重建方法,针对残缺手绘图,在训练网格生成器的过程中,利用可微渲染器生成预测3d模型轮廓图和标签3d模型轮廓图并输入至2d卷积形状鉴别器,利用2d卷积形状鉴别器能够有效区分预测网格3d模型的真实性和保真度,从而辨别预测网格3d模型的质量和真实性,增强了对复杂形状的识别能力,提高了预测网格3d模型的精确度和可靠性。并且,本发明将预测3d模型轮廓图和标签3d模型轮廓图分别进行多次下采样,得到不同分辨率的预测3d模型轮廓图和标签3d模型轮廓图组成的多尺度轮廓图对,进而构建多尺度miou损失,通过逐步增加2d卷积形状鉴别器的复杂度和多尺度轮廓图对的分辨率,逐步细化2d卷积形状鉴别器的判别能力,从而更有效地引导网格生成器生成高质量的预测网格3d模型,提高预测网格3d模型的质量。
49、本发明在2d卷积形状鉴别器之前笔锋增强模块,可以有效提升网格生成器对特定位置特征的学习,以缓解残缺手绘图的不完整性带来的挑战,从而提高网格生成器生成预测网格3d模型的精度和鲁棒性。
50、除此之外,本发明还在噪声数据集上对网格生成器进行训练,并对噪声手绘图进行视点预测,在训练时增加视点预测损失和去噪损失,提高了本发明利用噪声手绘图进行3d建模的准确性。
本文地址:https://www.jishuxx.com/zhuanli/20241021/321611.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表