基于原始电流和注意力模型的Nanopore测序数据纠错方法
- 国知局
- 2024-11-06 14:28:03
本发明涉及基因测序的一种nanopore测序数据纠错方法,具体涉及了一种基于读长原始电流信号和transformer模型的nanopore测序数据纠错方法。
背景技术:
1、纳米孔(nanopore)测序技术作为第三代测序技术的一种,具有读长长、测序速度快、实时测序、无pcr扩增等优点,广泛应用于基因组学、表观基因组学、转录组学和单细胞测序等研究领域。纳米孔测序通过检测单个核苷酸通过纳米孔时引起的电流变化来确定dna或rna序列。然而,纳米孔测序数据存在较高的噪声和错误率,这主要是由于电流信号噪声、测序通道质量不一致、dna/rna分子行为复杂以及化学反应复杂性等因素的影响。电流信号会受到电化学噪声、温度波动和系统噪声等影响,导致信号不稳定,影响测序结果的准确性。不同纳米孔测序通道在物理和化学特性上存在差异,同一序列在不同通道中的测序信号也会有所不同,增加了数据的复杂性和错误率。dna或rna分子在通过纳米孔时可能会出现停滞、倒退等行为,导致电流信号波动和扭曲。此外,纳米孔测序依赖与dna/rna分子相互作用的化学试剂和酶,这些化学反应的复杂性和不确定性也会影响测序的准确性。
2、现有的纳米孔测序纠错方法主要依赖于比对和校正的方法,这些算法通过将测序结果与参考基因组序列进行比对,识别和校正错误位点。然而,这些方法存在对参考基因组的依赖、忽略原始电流信号信息、计算复杂度高等不足。比对和校正方法高度依赖于高质量的参考基因组序列,对于参考基因组不完整或存在变异的情况,纠错效果较差。现有方法主要集中在对测序结果的后处理,忽略了原始电流信号中可能包含的重要信息,无法充分利用这些信息进行纠错。比对和校正方法通常需要大量的计算资源和时间,尤其是在处理大规模基因组数据时,计算复杂度更高,处理效率较低。
3、近年来,深度学习技术在自然语言处理、计算机视觉和生物信息学等领域取得了显著进展。特别是transformer模型在自然语言处理中的应用表现出色,具有强大的特征提取和模式识别能力。transformer模型通过自注意力机制,可以捕捉长距离依赖关系,适用于处理序列数据。将transformer模型应用于纳米孔测序数据的纠错,有望解决现有方法的不足,提高纠错的准确性和效率。
技术实现思路
1、为了解决现有技术中对原始电流信号利用不足、纠错效果不理想的问题,本发明提供了一种基于读长原始电流信号和transformer模型的nanopore测序数据纠错方法。本发明通过引入transformer模型对纳米孔测序数据进行纠错,充分利用原始电流信号中的信息,提升测序数据的准确性和可靠性。
2、本发明的技术方案如下:
3、一、一种基于原始电流和注意力模型的nanopore测序数据纠错方法
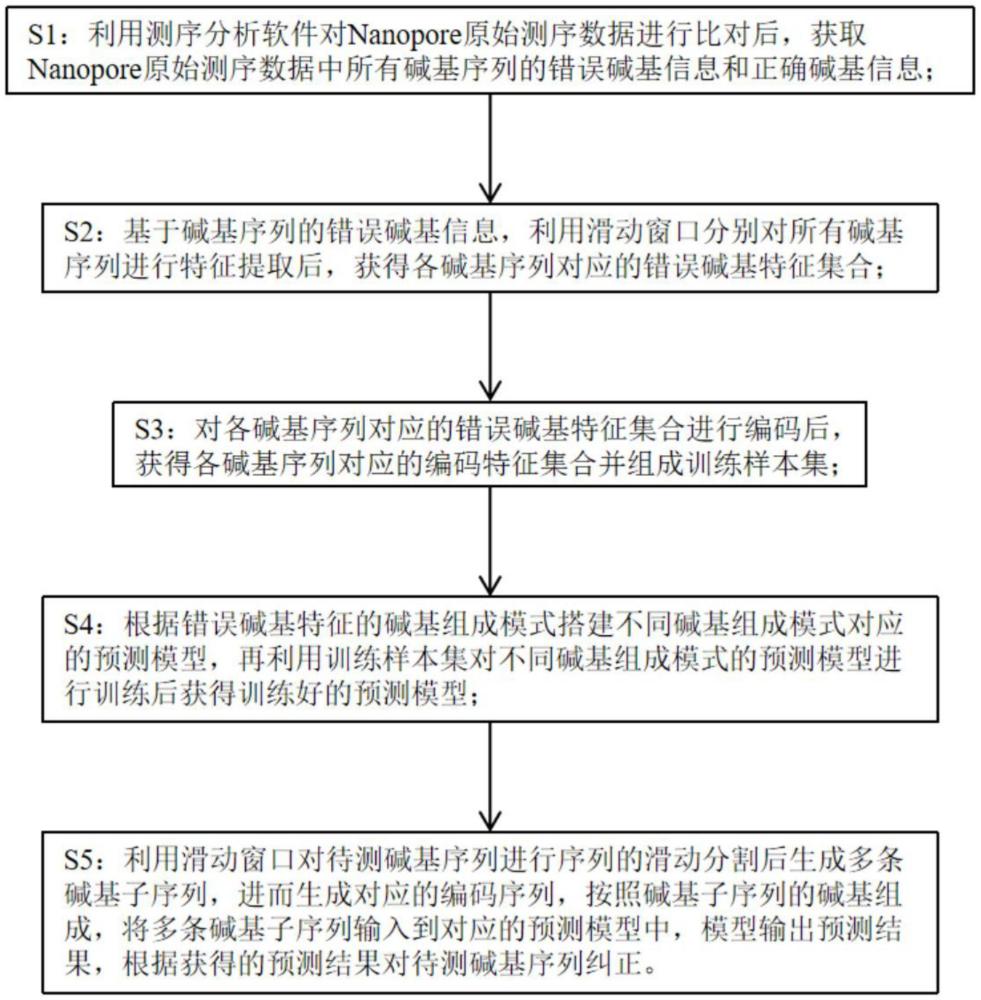
4、s1:利用测序分析软件对nanopore原始测序数据进行比对后,获取nanopore原始测序数据中所有碱基序列的错误碱基信息和正确碱基信息;
5、s2:基于碱基序列的错误碱基信息,利用滑动窗口分别对所有碱基序列进行特征提取后,获得各碱基序列对应的错误碱基特征集合;
6、s3:对各碱基序列对应的错误碱基特征集合进行编码后,获得各碱基序列对应的编码特征集合并组成训练样本集;
7、s4:根据错误碱基特征的碱基组成模式搭建不同碱基组成模式对应的预测模型,再利用训练样本集对不同碱基组成模式的预测模型进行训练后获得训练好的预测模型;
8、s5:利用滑动窗口对待测碱基序列进行序列的滑动分割后生成多条碱基子序列,进而生成对应的编码序列,按照碱基子序列的碱基组成,将多条碱基子序列对应的编码序列输入到对应的预测模型中,模型输出预测结果,根据获得的预测结果对待测碱基序列纠正。
9、所述s2具体为:
10、利用滑动窗口提取每条碱基序列中所有包含错误碱基的碱基子序列并形成错误碱基特征,从而获得当前条碱基序列的错误碱基特征集合,遍历处理nanopore原始测序数据中的其他碱基序列,最终获得各碱基序列对应的错误碱基特征集合。
11、所述s2中,对于每条碱基序列中的每个错误碱基i,若错误碱基i前后的碱基数均大于等于滑动窗口大小,则将错误碱基i作为滑动窗口的最后一个碱基并形成第一滑动窗口,利用第一滑动窗口对该条碱基序列进行特征提取后获得一条错误碱基特征;接着在第一滑动窗口的基础上,以一个碱基为单位依次移动滑动窗口并对该条碱基序列进行特征提取,从而获得多条错误碱基特征,直至错误碱基i作为滑动窗口的第一个碱基,从而获得错误碱基i的错误碱基特征组合,遍历处理该条碱基序列中的所有错误碱基,获得该条碱基序列中所有错误碱基的错误碱基特征组合,从而组成该条碱基序列的错误碱基特征集合;
12、若错误碱基i前后的碱基数中存在小于滑动窗口大小的情况,则用缺失值代替前后缺少的碱基后形成完整的滑动窗口,再利用滑动窗口以一个碱基为滑动步长的方式对碱基序列的错误碱基i进行特征提取,获得错误碱基i的错误碱基特征组合。
13、所述滑动窗口的大小为5-mer。
14、所述s3中,对于每条碱基序列对应错误碱基特征集合中的每条错误碱基特征,利用i6ma-pred模型中的编码方式对每条错误碱基特征进行编码后,获得对应的编码序列。
15、所述s4中,预测模型包含二分类模型和三分类模型。
16、所述二分类模型和三分类模型具体为基于多头注意力机制的transformer模型。
17、所述s4中,预测模型的数量大于等于错误碱基特征的模式数量相同。
18、所述预测模型为基于多头注意力机制的transformer模型,其包括多个依次级联的多头注意力层和与最后一个多头注意力层相连线性层以及与线性层相连的分类器,其中,每个多头注意力层包括两个多头注意力块、归一化层和前馈神经网络,当前多头注意力层的输入作为第一多头注意力块的输入,第一多头注意力块的输出与其与输入进行残差连接后输入到第一归一化层中,第一归一化层的输出作为第二多头注意力块的输入,第二多头注意力块的输出与其与输入进行残差连接后输入到第二归一化层中,第二归一化层的输出作为前馈神经网络的输入,前馈神经网络的输出与其与输入进行残差连接后输入到第三归一化层中,第三归一化层的输出作为当前多头注意力层的输出。
19、二、一种计算机设备
20、所述设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现所述方法的步骤。
21、本发明的有益效果是:
22、本发明结合长读长原始电流信号和transformer模型,充分利用原始电流信号中的丰富信息,利用transformer模型强大的特征提取和模式识别能力,有效提升了nanopore测序数据的纠错精度。
技术特征:1.一种基于原始电流和注意力模型的nanopore测序数据纠错方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于原始电流和注意力模型的nanopore测序数据纠错方法,其特征在于,所述s2具体为:
3.根据权利要求2所述的一种基于原始电流和注意力模型的nanopore测序数据纠错方法,其特征在于,所述s2中,对于每条碱基序列中的每个错误碱基i,若错误碱基i前后的碱基数均大于等于滑动窗口大小,则将错误碱基i作为滑动窗口的最后一个碱基并形成第一滑动窗口,利用第一滑动窗口对该条碱基序列进行特征提取后获得一条错误碱基特征;接着在第一滑动窗口的基础上,以一个碱基为单位依次移动滑动窗口并对该条碱基序列进行特征提取,从而获得多条错误碱基特征,直至错误碱基i作为滑动窗口的第一个碱基,从而获得错误碱基i的错误碱基特征组合,遍历处理该条碱基序列中的所有错误碱基,获得该条碱基序列中所有错误碱基的错误碱基特征组合,从而组成该条碱基序列的错误碱基特征集合;
4.根据权利要求2所述的一种基于原始电流和注意力模型的nanopore测序数据纠错方法,其特征在于,所述滑动窗口的大小为5-mer。
5.根据权利要求1所述的一种基于原始电流和注意力模型的nanopore测序数据纠错方法,其特征在于,所述s3中,对于每条碱基序列对应错误碱基特征集合中的每条错误碱基特征,利用i6ma-pred模型中的编码方式对每条错误碱基特征进行编码后,获得对应的编码序列。
6.根据权利要求1所述的一种基于原始电流和注意力模型的nanopore测序数据纠错方法,其特征在于,所述s4中,预测模型包含二分类模型和三分类模型。
7.根据权利要求6所述的一种基于原始电流和注意力模型的nanopore测序数据纠错方法,其特征在于,所述二分类模型和三分类模型具体为基于多头注意力机制的transformer模型。
8.根据权利要求1所述的一种基于原始电流和注意力模型的nanopore测序数据纠错方法,其特征在于,所述s4中,预测模型的数量大于等于错误碱基特征的模式数量相同。
9.根据权利要求1所述的一种基于原始电流和注意力模型的nanopore测序数据纠错方法,其特征在于,所述预测模型为基于多头注意力机制的transformer模型,其包括多个依次级联的多头注意力层和与最后一个多头注意力层相连线性层以及与线性层相连的分类器,其中,每个多头注意力层包括两个多头注意力块、归一化层和前馈神经网络,当前多头注意力层的输入作为第一多头注意力块的输入,第一多头注意力块的输出与其与输入进行残差连接后输入到第一归一化层中,第一归一化层的输出作为第二多头注意力块的输入,第二多头注意力块的输出与其与输入进行残差连接后输入到第二归一化层中,第二归一化层的输出作为前馈神经网络的输入,前馈神经网络的输出与其与输入进行残差连接后输入到第三归一化层中,第三归一化层的输出作为当前多头注意力层的输出。
10.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1至9中任一项所述方法的步骤。
技术总结本发明公开了一种基于原始电流和注意力模型的Nanopore测序数据纠错方法。本发明包含以下步骤:首先,根据Nanopore原始测序数据进行比对后,获取Nanopore原始测序数据中所有碱基序列的错误碱基信息和正确碱基信息;结合滑动窗口对所有碱基序列进行特征提取后,获得各碱基序列对应的错误碱基特征集合,进而构建训练样本集;接着训练并获得不同模式的预测模型,最后对待测碱基序列预处理后再输入到预测模型并获得预测结果,根据获得的预测结果对待测碱基序列纠正。本发明通过引入Transformer模型对纳米孔测序数据进行纠错,充分利用原始电流信号中的信息,提升测序数据的准确性和可靠性。技术研发人员:代琦,陈浒,乙文静,刘晓庆受保护的技术使用者:浙江理工大学技术研发日:技术公布日:2024/11/4本文地址:https://www.jishuxx.com/zhuanli/20241106/322248.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
一种坐位动脉采血装置
下一篇
返回列表